一、数据集成的发展与现状
理想汽车数据集成的发展经历了四个阶段:

第一阶段:在 2020 年 7 月基于 DataX 构建了离线数据交换能力。
第二阶段:在 2021 年 7 月,构建了基于 Flink 的实时处理平台,在这两个阶段,还没有一个真正的数据集成的产品。
第三阶段:2022 年 9 月,开始建设数据集成平台,构建了第一个数据集成链路,实现 Kafka 到 Hive 的数据链路。
第四阶段:2023 年 4 月,在原来实时处理能力的基础上扩展了离线集成能力,实现了批流数据的统一。
早期,理想还没有统一的数据集成平台,数据产品纷杂。

TiDB、MySQL、StarRocks、MongoDB 等数据传输到下游,是通过 DataX 来实现的;而 Kafka、Oracle 等数据传输具备流特性的数据又是通过 Flink 实现的;同时,比如 Hive 等一些数据传输是通过写 Spark SQL 来实现的;还有一些数据库,如 TiDB、Oracle 是通过数据库自己的引擎进行数据传输。
基于以上数据形态,业务方在使用产品时存在如下一些痛点:

- 产品能力缺失。需要在多套平台之间切换,没有直接可落地的产品,需要开发团队写代码。
- 多套开发语言。无论是 Flink、Spark 还是 DataX 等等,每一个引擎都有其特有的配置,需要同时了解多套开发语音和不同的开发细节。
- 资源共享难。由于批流使用不同的引擎,由不同的团队开发,底层的计算和存储资源很难共享。
- 资源利用率低。正是由于资源共享难,又引发了另外一个问题,就是资源利用率低,且存在不均衡的状况。比如实时计算集群,是长期运行的任务,其计算资源经常吃紧,但是存储资源基本上处于没有使用的状态。

根据业务痛点,我们总结出了三大需求:
首先是统一平台,屏蔽各种异构数据源之间不同传输引擎的差异。
第二是统一计算引擎,将批式、流式用一套引擎实现。
第三是存算分离,能够在计算层和存储层,按照业务的需求进行独立的弹性伸缩。

为了满足上述需求,我们选择使用 Fink 作为计算引擎,其批流一体的计算引擎,让我们在处理批式、流式时可以做到无缝切换。同时,Flink 基于 K8s 的云原生的能力也能够帮助我们实现计算资源和存储资源的弹性扩缩容。
我们的产品已经在业务上有很多应用实例。对接了包括服务器端的日志类数据,比如 Oracle、MySQL、TiDB 等有 binlog 的业务数据传输到下游。同时,车端、云端还有工厂的一些埋点和信号的数据,也通过集成平台实现了数据传输。
计算方面,在传输能力上,可以实现流式和批式的数据处理转换,支持并行读取和并行写入的能力,以及对于异构数据源不同类型数据转换的能力,业务用户不再需要去了解不同产品的细节。在产品运维能力上,包括任务的管理、权限控制、监控告警、日志采集等等,覆盖了任务的全部生命周期。最终落到下游各种数据存储。

二、数据集成的落地实践
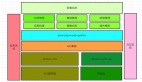
1、数据集成平台架构

存储层:采用 JuiceFS+BOS 的方式,同时借助 K8s 本身 node 节点的一些本地存储能力,为计算引擎提供相应的存储能力。
计算层:基于 Flink 的内核,扩展了各种 connector,最终封装成了一个标准化镜像,通过 Flink Operator 来调取镜像,把任务提交到 K8s 的集群当中。同时,配备了 Flink 的 history 的服务,这样用户可以在任务出现异常或任务结束时对任务的历史状况进行分析。Flink Operator 是一个定义在 Flink 上的 CRD,它通过 K8s 的 API server 对外提供标准化的 API。上面封装了一个中间层,对下使用 K8s 的 API server,对产品则封装了标准化的 API,屏蔽各个层的依赖关系,还承接了任务的编排和任务生命周期的管理。
2、设计模型
数据集成的设计模型如下图所示,通过定义各种 source 和 sink 的插件来实现数据传输的转换。

下面封装的 API,用户只需要定义 source 和要传输的数据内容,以及写到哪一个 sink,就可以完成一个 transform 的过程。

例如,假设我们已经有了 TiDB、OceanBase、Hive、Kafka 等 sink 的链路,当增加一个新的 MySQL 的 connector 时,就创建了这一套插件的一组数据传输能力。这样就可以快速实现各种场景的数据落地。
3、典型场景

在离线集成场景中,首先获取库表的关联关系。数据之间的增量和全量的数据同步,通过调度平台进行统一的调度处理。

在过去使用 OceanBase 到 Hive 的链路,数据量大时 OB 经常出现 time out,因为 OB 本身设置了 time out 时间。我们的解决方法是,首先获取 OB 的数据结构,分析主键及分区选择分片字段,计算出这个字段的最大值、最小值,以及这一批次的数据量,然后使用这三个信息,合理设置拉取这个数据的 size。之后, Flink 就可以基于这个 size 的大小并行地去拉取。保证每一次拉取的数据量不会特别的多,这样就解决了数据出现 time out 的问题

过去的实时传输链路,用户需要跨多个平台去做,开发流程长。并且,用户需要手动创建表,开发复杂。

有了数据集成平台之后,就省去了上面一系列的人工过程。通过集成平台配置 source、sink,就可以实现数据流转。
对于 Hive 的表,经常会有数据分区。这里提供了几种方式来生成 Hive 的分区,可以基于数据、基于处理或基于元数据时间来进行分区。基于元数据时间分区的好处是可以避免生成太多的 Hive 的小碎文件,因为消费数据在不出现延迟的情况下,基本上一个分区的数据都会写到同一个 Hive 的 partition 里面。同时,开启了 Kafka 的自动感知分区的能力,比如当 Kafka 数据暴增时,Kafka 的 topic 的分区进行增加,自动感知就非常有必要。

上图展示的是一个 Oracle 传输入流的场景。借助 Flink CDC 的能力,在全量阶段,通过设置多个并行度来读全量数据,当全量数据读取完成后,Flink 会通过自动切换能力切换到增量模式。增量模式会选择其中的某一个 task manager,去读取增量的数据。
4、异构数据源

不同类型的数据库支持的数据类型存在差异,我们很难在这个过程当一一记住该把哪个类型转换到哪个类型。因此,在数据集成平台上,我们把数据源的类型映射成 Flink 类型,把数据目标的类型也映射成 Flink 类型。最终,都通过 Flink 的类型进行统一的处理转换。映射过程用户是不需要关注的。
5、SQL 形式的过滤条件

这个转换过程中,需要过滤一些常用的 where 条件,这里提供了常用的一些函数。
三、数据集成云原生的落地实践

K8s 云原生方案的落地主要考虑了四大关键点,接下来逐一展开介绍。
1、方案选型

选型方面,选择使用 Flink Operator 进行任务管理。首先,Flink Operator 可以方便地进行管理集群。它封装了 K8s 的一个应用,可以扩展 API 来实现配置和创建应用实例。采用声明式地提交。同时配备了集成的 ingress,可以通过 ingress 来实现配置 Flink 的 web UI,在运行过程中通过 web UI 监控任务的状态,或者查看运行日志。Flink Operator 实现了作业全生命周期的管理,可以实现运行和暂停应用程序,有状态、无状态的应用升级,以及定时触发和管理 CheckPoint 点。还可以做到回滚。

上图展示了 Flink Operator 的处理过程。首先,在平台上注册 Flink Operator,也就是在 K8s 集群中创建一个 Flink deployment 的 CRD。之后就可以使用这个 CRD 去创建相应的资源。一个 yaml 文件提交到 K8s 集群之后,K8s 的 API 调用 CRD 创建 FlinkDeployment。然后由 Flink Operator 创建 Flink 的 Deployment,并创建相应的 TaskManager。同时,Operator 会监听 FlinkDeployment 的状态,其实质上是监听 JobManagerPod 的状态,并更新到 Operator 中。如果任务失败,会尝试重新调起。
2、状态判断及日志采集

各种任务的状态已经被记录到了 FlinkDeployment 中,通过 watch 的方式去监听 Flink K8s API server,就可以捕获任务各个事件的状态。同时,还会 watch 每一个 JobManager 和 TaskManager 的 pod,将 pod 状态和名称来作为日志标题。已经有了任务运行的状态,为什么还要采集 pod 的状态呢?因为实时任务是一个持久化运行的任务,pod 可能会在某一个时间节点,由于一些原因导致了死亡。对于已经死亡的 pod,不需要看到所有的日志的状态。通过标记 pod 的状态,来描述这一个日志是一个有效还是一个无效的日志。在每一个 K8s 的 node 节点上部署了 Agent,通过 Agent 采集某每一个 pod 的日志作为下游的转换日志。

上图描绘出了状态转换关系。Failed、Finished、Canceled 和 Suspended 这四个状态是最终任务结束的状态类型。如果出现 Failed,下游会进行相应的告警。
3、监控告警

我们对每一个任务都给用户提供了配置告警的方式,当用户启动任务的时候,任务会把相应的指标上报到 Prometheus,Prometheus 会周期性地去采集和运算,如果告警指标没有被触发,就会处于静默的状态。如果告警指标被触发,就会触发一条告警发送给相应的用户。用户就可以基于告警采取相应的处理。
4、共享存储

共享存储使用了 JuiceFS。每一个 pod 都会通过挂载本地 CSI 的方式把 JuiceFS 挂载到本地,形成一个本地的存储目录。
Flink 的任务需要去做周期性的 checkpoint,checkpoint 会被持久化到 JuiceFS 里面。在任务运行时,Flink 配置了重启的策略,Operator 也会有一些重启的策略,当任务出现异常的时候会进行任务的重启,在重启时会找到最近一次 checkpoint 点进行重启。另外,Flink Operator 可以实现任务的无状态和有状态的升级,升级时,如果 yaml 状态发生了变更,就会去找到最新的 checkpoint 点进行任务重启。
Flink 运行期间的状态信息和存档信息也会记录在 JuiceFS 里面,会由 Flink 的 history 来提供查看。
四、未来规划

首先,支持更多的数据源,实现更多异构数据源之间的转换。
第二,弹性伸缩能力方面,目前虽然使用了 K8s 的能力,但是对资源的弹性伸缩等问题还没有进行完整的落地,后续希望在弹性伸缩能力上进行一些增强。
第三,进一步提升海量数据的传输性能。
最后,对于批处理任务,目前 Flink 存在一个缺陷,无法进行谓词下推,导致在做有 where 条件的任务时会把全量数据拉到 Flink 内存里面,再进行 where 条件的过滤。