












谷歌最近发布的Gemini掀起了不小的波澜。
毕竟,大语言模型领域几乎是OpenAI的GPT一家独大的局面。
不过作为吃瓜群众,当然希望科技公司都卷起来,大模型都打起来!
所以,作为科技巨无霸谷歌的亲儿子,Gemini自然承受了很高的期待。
虽然Gemini发布之后发生了一些奇奇怪怪的事情吧,什么视频造假啦,认为自己是文心一言啦。
不过问题不大,咱们不看广告看疗效。
最近在CMU,研究人员进行了一组公正、深入和可重复的实验测试,重点比较了Gemini和GPT在各项任务中的优劣,另外还加入了开源的竞争对手Mixtral。

论文地址:https://arxiv.org/abs/2312.11444
代码地址:https://github.com/neulab/gemini-benchmark
研究人员在论文中对Google Gemini的语言能力进行了深入地探索,
从第三方的角度,对OpenAI GPT和Google Gemini模型的能力进行了客观比较,公开了代码和比较结果。
我们可以从中发现两个模型分别擅长的领域。
研究人员比较了6种不同任务的准确性:
- 基于知识的QA(MMLU)
- 推理(BIG-Bench Hard)
- 数学(GSM8k、SVAMP、ASDIV、MAWPS)
- 代码生成(HumanEval,ODEX)
- 翻译 (FLORES)
- Web指令跟踪(WebArena)
为了公平起见,实验中尝试控制所有变量,对所有模型使用相同的提示、生成参数和评估。
评测中使用了LiteLLM以统一的方式查询模型,使用try_zeno做全面深入的分析。
测试模型
研究比较了Gemini Pro、GPT-3.5 Turbo、GPT-4 Turbo以及Mixtral,指出了他们在能力上的不同。
特点:Gemini Pro是多模态的,通过视频、文本和图像进行训练。GPT-3.5 Turbo和GPT-4 Turbo则主要基于文本训练,其中GPT-4 Turbo是多模态的。
测试复现方法
更方便的复现方法:点击下文测试任务的链接即可进入CMU集成好的基于Zeno的AI评估平台进行验证

GitHub链接:
https://github.com/neulab/gemini-benchmark]
具体测试任务
基于知识的问答(Knowledge-based QA)
基于UC伯克利2020年提出的MMLU(Massive Multitask Language Understanding)大模型评测进行评测
该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。
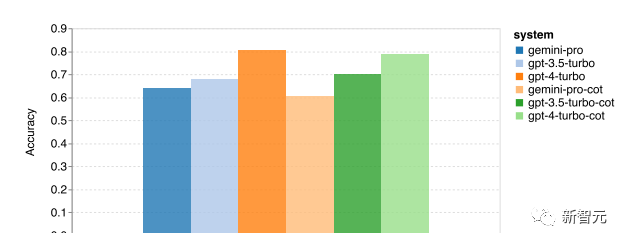
用5-shot和思维链提示词的MMLU任务总体准确率如下图,Gemini Pro均略微落后GPT-3.5 Turbo
文章也指出使用思维链提示的性能差异不大,可能是因为 MMLU 主要是基于知识的问答任务,可能不会从更强的面向推理的提示中显着受益。
下图显示Gemini-pro、gpt3.5-turbo、gpt-4-turbo对于多选题答案输出的比例,结果显示Gemini-pro、gpt3.5-turbo都有一些答案偏见,尤其Gemini-pro十分偏向D选项
表明 Gemini 尚未针对解决多选题问题,进行大量指令调整,这可能导致模型在答案排序方面存在偏差

MMLU的57个子任务中只有两项Gemini-pro超过GPT3.5-turbo。
下图显示gpt3.5最领先Gemini-pro的前四个任务的准确性,和Gemini-pro超过gpt3.5的两个任务

通用推理(General-purpose Reasoning)
基于BBH(BIG-Bench Harch)这一通用推理数据集进行测试,其中包括算术、符号和多语言推理以及事实只是理解任务。
首先,从如下总体精度图中可以看到Gemini Pro实现的精度略低于GPT 3.5 Turbo,并且远低于GPT 4 Turbo。相比之下,Mixtral 模型的精度要低得多。

接下来进行一些细节分析,首先根据问题的长度测试一下准确性,结果如下图。

作者发现Gemini Pro在更长、更复杂的问题上表现不佳,而GPT模型对此更稳健。
GPT-4 Turbo的情况尤其如此,即使在较长的问题上,它也几乎没有表现出性能下降,这表明它具有强大能力来理解更长和更复杂的查询。
GPT-3.5 Turbo的稳健性处于中间位置。Mixtral在问题长度方面特别稳定,但总体准确率较低。
下图再具体列出了GPT-3.5 Turbo表现优于Gemini Pro最多的任务。

Gemini Pro在tracking_shuffled_objects任务上表现很糟糕
在某些任务中,即multistep_arithmetic_two、salient_translation_error_detection、snarks、disambiguition_qa和两个tracking_shuffled_objects任务中,Gemini Pro的表现甚至比Mixtral模型还要差。
当然,有一些任务Gemini Pro优于GPT3.5。
下图显示了 Gemini Pro 比 GPT 3.5 Turbo 表现优秀的六项任务。这些任务需要世界知识(sports_understanding)、操作符号堆栈(dyck_languages)、按字母顺序排序单词(word_sorting)和解析表(penguins_in_a_table)等。

文章在此部分最后表示,对于通用推理任务,似乎没有Gemini和GPT都没有绝对优势,所以可以都尝试一下
数学问题
基于四个数学应用题评测进行:
- GSM8K,小学数学基准
- SVAMP 数据集,通过不同的词序生成问题来检查稳健的推理能力,
- ASDIV 数据集,具有不同的语言模式和问题类型
- MAWPS 基准,由算术和代数应用题组成。
下图显示四项数学推理任务的总体准确性

从图中可以看出,在 GSM8K、SVAMP 和 ASDIV 任务上,Gemini Pro的精度略低于 GPT-3.5 Turbo,并且远低于 GPT-4 Turbo,这些任务都包含多样化的语言模式。
对于 MAWPS 任务,所有模型都达到了 90% 以上的准确率,尽管 Gemini Pro 仍然比GPT模型稍差。
有趣的是,在此任务中,GPT-3.5 Turbo的表现以微弱优势胜过GPT-4 Turbo。
相比之下,Mixtral模型的准确率比其他模型要低得多。
和之前在BBH上的推理任务一样,我们可以看到较长任务推理性能会下降。
并且和以前一样,GPT 3.5 Turbo 在较短的问题上优于 Gemini Pro,但下降得更快,Gemini Pro 在较长的问题上实现了类似(但仍稍差)的准确度。
不过在思维链(CoT)长度超过100的最复杂例子中,Gemini Pro优于GPT 3.5 Turbo,但在较短示例中表现不佳。

最后,文章研究了比较模型在生成不同位数答案时的准确性。
根据答案中的位数创建三个类别,一位数、两位数、三位数答案(MAWPS 任务除外,其答案不超过两位数)。
如下图所示,GPT-3.5 Turbo似乎对于多位数数学问题更加稳健,而Gemini Pro在位数较多的问题上性能下降更多。

代码生成
在此类别中,文章使用两个代码生成数据集HumanEval和ODEX检查模型的编码能力。
前者测试对Python标准库中一组有限函数的基本代码理解。
后者测试使用整个Python生态系统中更广泛的库的能力。
它们都将人工编写的英语任务描述(通常带有测试用例)作为输入。这些问题用来评估对语言、算法和初等数学的理解。
总体而言,HumanEval有164个测试样本,ODEX有439个测试样本。
代码生成的总体情况如下图:
Gemini Pro在两项任务上的Pass@1 成绩都低于GPT-3.5 Turbo,远低于GPT-4 Turbo。

接下来,分析最佳解决方案长度与模型性能之前的关系,因为解决方案长度可以一定程度上表明相应代码生成的任务的难度。
本文发现,当解决方案长度低于100(即代表处理简单问题)时,Gemini Pro 可以达到与 GPT-3.5 相当的 Pass@1,但当解决方案变得更长(即处理更难的问题时)时,它会大幅落后。

文章还分析了每个解决方案所需的库如何影响模型性能,结果如下图显示:
根据结果分析,在大多数使用库的情况下,例如mock、pandas、numpy和datetime,Gemini Pro的表现比GPT-3.5差。
然而,它在 matplotlib 情况下优于 GPT-3.5 和 GPT-4,在通过代码执行绘图可视化时显示出更强的功能。

下面展示几个具体的失败案例:
首先, Gemini在从Python API中正确选择函数和参数方面稍差一些
比如,当你给出如下指令时
def f_3283984():
"""decode a hex string '4a4b4c' to UTF-8."""Gemini Pro 生成以下代码,导致类型不匹配错误。
bytes(bytearray.fromhex('4a4b4c'), 'utf-8')相比之下,GPT 3.5 Turbo 使用以下代码,达到了预期的结果:
hex_string = '4a4b4c'
decoded_string = bytes.fromhex(hex_string).decode('utf-8')
return decoded_string此外,Gemini Pro的错误比例较高,所实现的代码在语法上是正确的,但与复杂的意图不正确匹配。
例如,对于以下指令
from typing import List
def remove_duplicates(numbers: List[int]) -> List[int]:
"""From a list of integers, remove all elements that occur more than once.
Keep order of elements left the same as in the input.
>>> remove_duplicates([1, 2, 3, 2, 4])
[1, 3, 4]
"""Gemini Pro 给的代码,只提取唯一的数字,而不删除那些出现多次的数字。
seen_numbers = set()
unique_numbers = []
for number in numbers:
if number not in seen_numbers:
unique_numbers.append(number)
seen_numbers.add(number)
return unique_numbers机器翻译(Machine Translation)
基于FLORES-200 机器翻译基准评估模型的多语言能力,特别是在各种语言对之间翻译的能力。
针对所有选定的语言对,对测试集中的1012个句子进行评估。作为这项研究的第一步,本文将范围限制为仅从英语到其他语言(ENG→X)的翻译。
结果显示如下图,Gemini Pro在翻译任务上,总体优于其他模型,在 20 种语言中的 8 种语言上均优于 GPT-3.5 Turbo 和 GPT-4 Turbo,并在4种语言上取得了最高性能。

虽然在非英语语言翻译方面尚未超越专用机器翻译系统,但通用语言模型也显示出了强竞争力的性能
零样本提示和5样本提示Gemini Pro在翻译任务上均优于其他模型

网页代理(Web Agents)
最后,本文验证每个模型充当网络导航代理(web navigation agent)的能力,这是一项需要长期规划和复杂数据理解的任务。
使用 WebArena ,这是一个基于命令执行的模拟环境,其中成功标准基于执行结果。分配给代理的任务包括信息查找、站点导航以及内容和配置操作。
这些任务跨越各种网站,包括电子商务平台、社交论坛、协作软件开发平台(例如 gitlab)、内容管理系统和在线地图。
如下图文章从总体结果可以看出,Gemini-Pro 的性能与 GPT-3.5-Turbo 相当,但稍差。

与 GPT-3.5-Turbo 类似,当Prompts提到任务可能无法完成时(UA 提示),Gemini-Pro 的表现会更好。通过 UA 提示,Gemini-Pro 的总体成功率达到 7.09%。
之后文章又按照网络进行细分,如下图,可以看到 Gemini-Pro 在 gitlab 和地图上的表现比 GPT-3.5-Turbo 差,而在购物管理、reddit 和 Shopping 上则接近 GPT-3.5-Turbo 。它在多站点任务上的表现比 GPT-3.5-Turbo 更好。

测试结果总览
在本文中,作者对 Google 的 Gemini 模型进行了第一次公正、深入的研究,并将其与 OpenAI 的 GPT 3.5 和 4 模型以及开源 Mixtral 模型进行了比较。

CMU评测的主要结果展示,黑色粗体表示最佳模型,下划线为第二
在最后,作者叠了一些甲:
指出他们工作是针对不断变化且不稳定的API,所有结果均为截至 2023 年 12 月 19 日撰写本文时的最新结果,但随着模型和周围系统的升级,未来可能会发生变化。
结果可能取决于其选择的特定提示和生成参数
作者测试时没有像谷歌意义使用多个样本和自我一致性(self-consistency),不过作者认为对不同模型使用一致的prompts的多项任务上进行的测试,恰恰可以合理地展示被测模型的稳健性和广义指令的遵循能力
作者指出数据泄露对当前大模型评测任务的困扰,虽然他们没有明确测量这种泄露,但他们也尝试过各种方法来缓解这个问题
在展望中,作者也提出建议,希望大家在使用Gemini Pro之前,根据这篇论文,自己评估Gemini Pro是否如宣传所说与GPT 3.5 Turbo相媲美。作者也表示Gemini的Ultra版本尚未发布,等其发布后也会验证其是否如报道所说与GPT4相当。





























