前一天发布 LLMPerf 排行榜,宣称要推动大型语言模型推理领域的发展,鼓励创新与超越。
第二天就收获 AI 社区的大量吐槽,原因是排行榜的「基准甚至没有得到很好的校准」。
这是 Anyscale 这家初创公司正在经历的事情。
Anyscale 是一家专注分布式计算领域的美国初创公司,虽然创立仅三年时间,但却收获了不少的关注。
首先就是 Anyscale 旗下开源项目 Ray 带来的光环。Ray 是一个开源的分布式计算框架,可以将 AI/ML 和 Python 的 workload 从单机拓展至多台计算机上,从而提高 workload 的运行效率,目前已经在 Github 上收获了两万多个 Star。带动了最新一波大模型热潮的 ChatGPT,也是基于 Ray 框架训练的。
还有一部分原因是创始团队的光环。这家初创公司的创始人之一、UC 伯克利教授 Ion Stoica 是市值 310 亿美元的数据巨头 Databricks 的联合创始人,他在十年前带领学生创立了 Databricks,收获了商业上的巨大成功。在 2019 年,他又一次做出了创业的决定 ——Anyscale 诞生了。公司创始团队中的 CEO Robert Nishihara 和 CTO Philipp Moritz ,也都是他在伯克利的学生。此外,伯克利教授 Michael I. Jordan 也参与了 Anyscale 的创业。
这些要素,都让人们在 Anyscale 身上看到了 Databricks 的影子,一些投资者将 Anyscale 描述为充满希望的「下一个 Databricks」
2021 年 12 月,Anyscale 完成了 1 亿美元的 C 轮融资,估值达到 10 亿美元,投资者包括 a16z、Addition、NEA、Intel 等。今年 8 月,Addition 和 Intel 又共同牵头追加了新一轮 9,900 万美元投资。

这应该是一个前景光明的技术团队。而此次被吐槽事件的经过是这样的:
11 月初,Anyscale 发布过一个开源大模型推理基准,叫做「LLMPerf」。这个基准是为了方便广大研究者评估 LLM API 性能。
三天前,Anyscale 在上述工作的基础上,推出了 LLMPerf 排行榜。

排行榜地址:https://github.com/ray-project/llmperf-leaderboard
Anyscale 称,他们已经利用 LLMPerf 对一些 LLM 推理提供商进行了基准测试,评估大模型性能、可靠性、效率的关键指标包括以下三点:
- 第一个 token 的时间(TTFT),表示 LLM 返回第一个 token 的持续时间。TTFT 对于聊天机器人等流媒体应用尤为重要。
- token 间延迟:连续 token 之间的平均时间。
- 成功率:推理 API 在无错误的情况下成功响应的比例。由于服务器问题或超出速率限制,可能会出现失败,这反映了 API 的可靠性和稳定性。
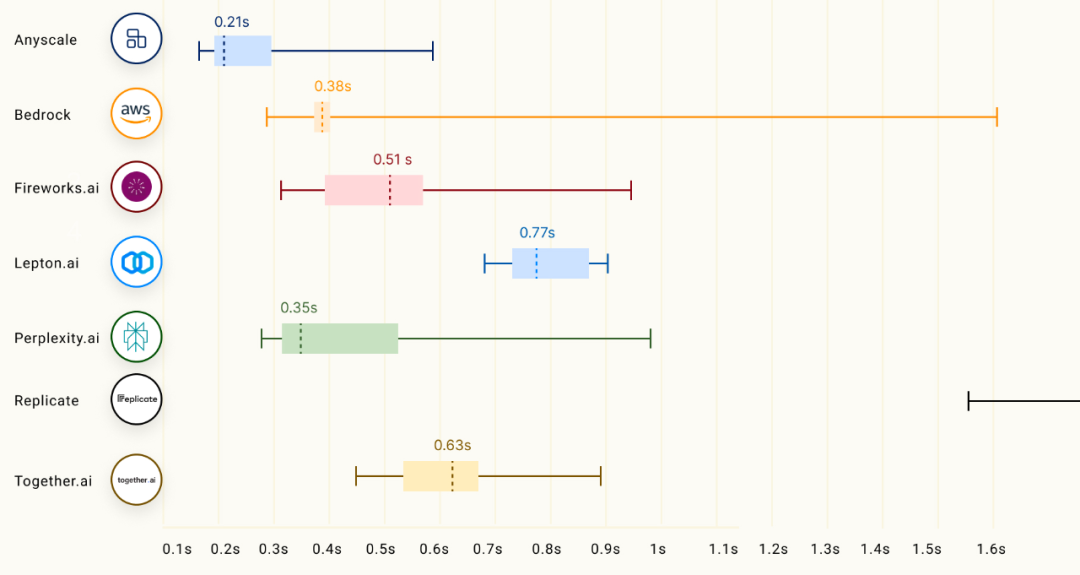
但 Anyscale 晒出的这些测评结果引发了不小的争议,比如 TTFT 这一项指标,对于不同规模的模型,Anyscale 都是第一名。
70B Models:
13B Models:
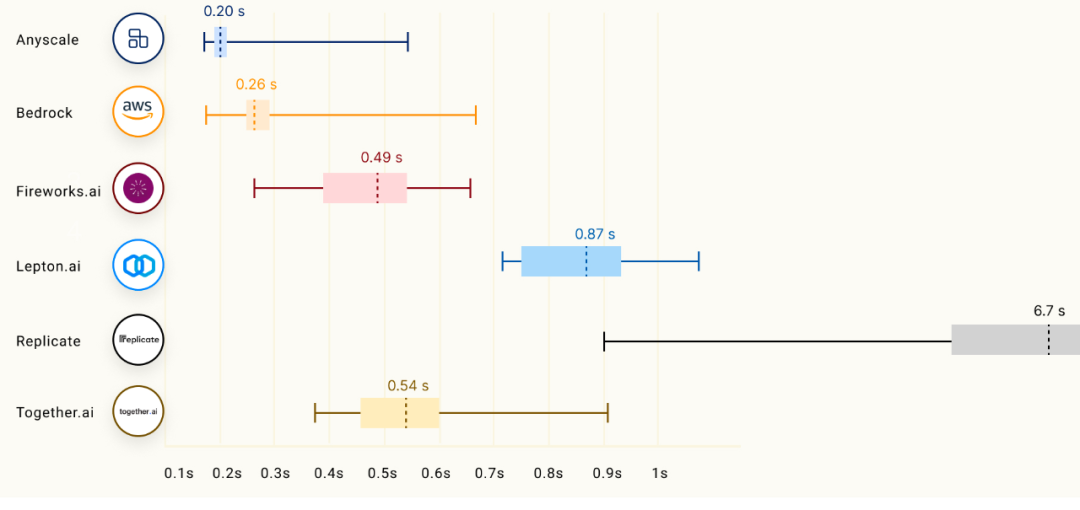
7B Models:
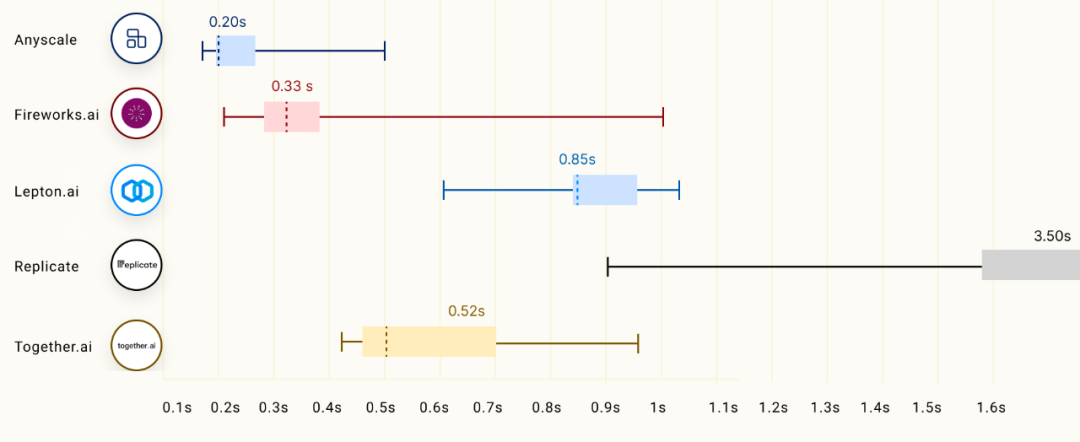
后两项指标的测评结果中,Anyscale 也显示出「遥遥领先」的水准。
面对这么多优秀对手,Anyscale 真的能实现「吊打」吗?图中结果令人怀疑。
对此,PyTorch 创始人 Soumith Chintala 表示:「看到来自可靠来源的构建不佳的基准让我感到痛苦。我希望 Anyscale 能够解决问题,并在发布此类基准之前咨询其他利益相关者。如果我不是很了解 Anyscale,我会认为这是恶意行为。」
问题出在哪里呢?Soumith Chintala 认为,这个基准没有得到很好的校准,「它仅在很短的时间内展示了复杂问题的一个方面」。
至少,用户需要了解多个附加因素:1. 服务的每个 token 成本;2. 吞吐量,而不仅仅是延迟;3. 在一段时间内测量的可靠性、延迟和吞吐量,而不仅仅是突发可靠性,突发可靠性可能会根据一天中的时间而有很大变化。
此外,Anyscale 应该明确标记该基准是有偏见的,因为 Anyscale 正在管理它,或者向其他利益相关者开放基准的设计和治理,即开放治理,而不仅仅是开源。试图制定和控制标准并不好。
「基准游戏」并不新鲜,曾经的数据库之战、大数据之战、机器学习框架之战都涉及到各种投机取巧的基准测试,仅仅为了更好地展示自己。
两位 AI 学者陈天奇和贾扬清也回忆起,那些年关于「基准游戏」的故事:

作为 LeptonAI 的创始人,贾扬清还分析了 Anyscale 发布的大模型推理排行榜为什么不够合理:
作为 AI 框架领域的资深人士,请允许我分享一个故事。在图像模式时代,每个人都想成为 「最快的框架」,为了让自己的速度快上 2%,不惜牺牲很多其他因素。
有一个框架从来都不是最快的。猜猜它是什么?
这个框架的名字叫 PyTorch。直到今天,PyTorch 仍然不是最快的框架,这是我从同事 Soumith Chintala 身上学到的重要一课。这是一个有意识的选择,以确保不会过度优化单一(或少数)标准。
我为 Anyscale 制作基准测试而鼓掌,恕我直言,这是一个诚实、用心良苦的基准测试,却存在严重错误和不明确的参数。比如,在引擎盖下运行这些服务的是什么 GPU?
但是,既然性能比较不可避免,那我就把结果公布出来吧。
在 Anyscale 在 10 月份发布的一篇帖子中,曾对比过三家 API 的推理性能。贾扬清晒出了一张 Lepton API 与这三家 API 的对比图片:
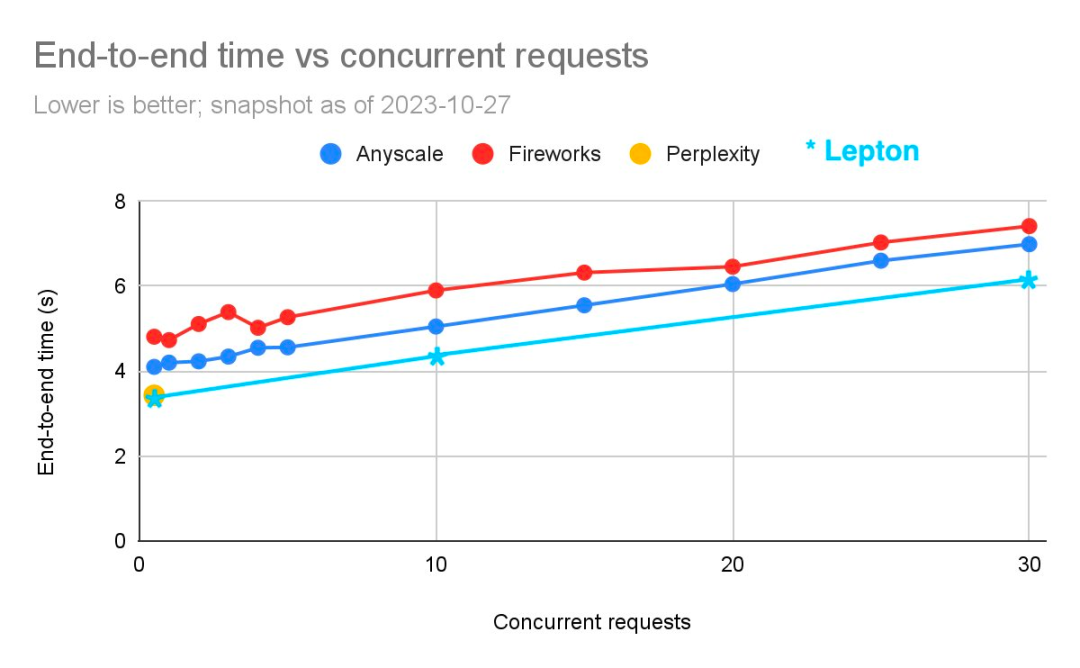
基准数据来源:https://anyscale.com/blog/reproducible-performance-metrics-for-llm-inference
「原始数据不是由 Anyscale 发布的,因此我们不得不在帖子中的原始图片上叠加图表。很抱歉把这些东西拼凑在一起。」贾扬清表示:「我们并不打算用它来衡量谁是最快的,只是想证明我们是名列前茅的。」
除了贾扬清,其他「被上榜」的 API 所属团队也提出了质疑。
比如 FireworksAI 联合创始人、CTO Dmytro Dzhulgakov:
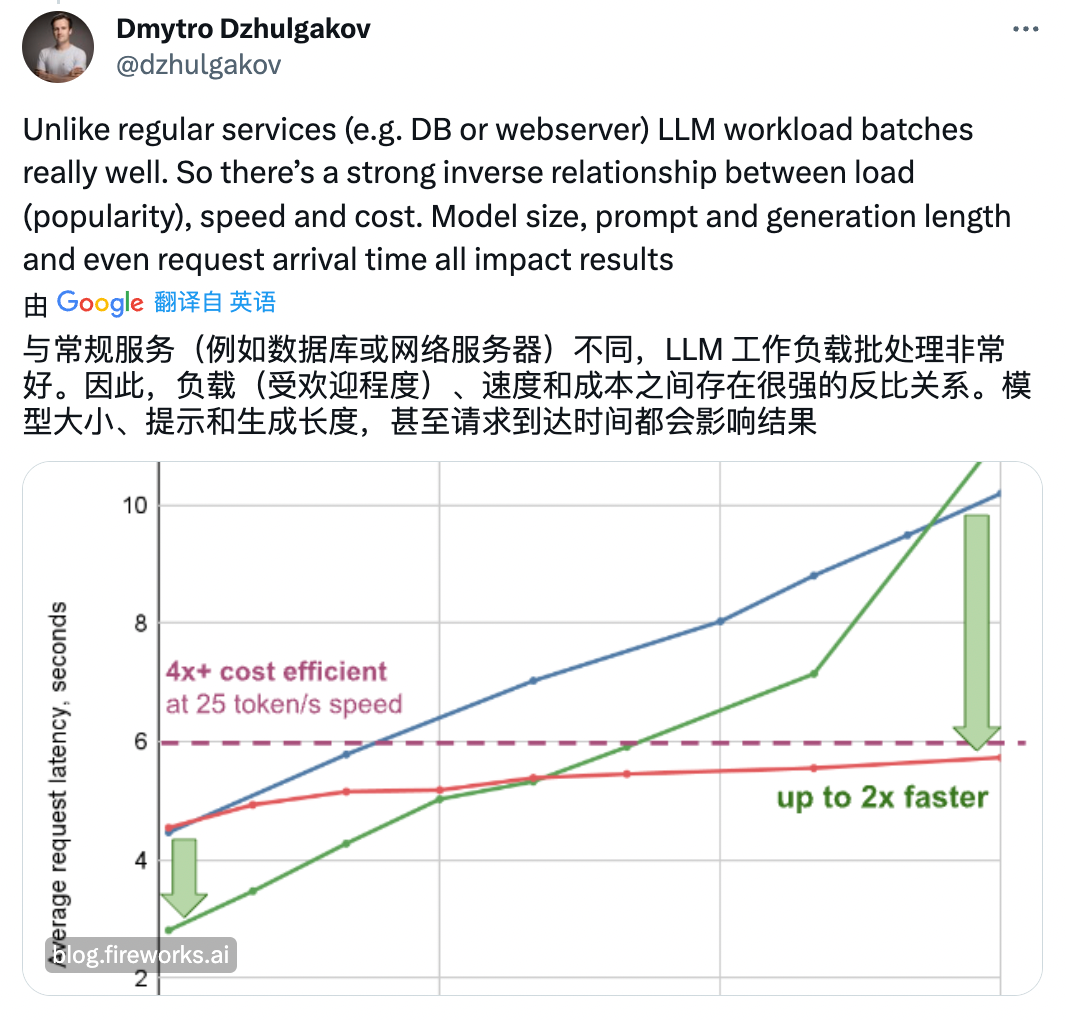
TogetherAI 的 CEO 表示:「Anyscale 是为了清洗他们 API 糟糕性能进行的基准测试。」

多方质疑之下,Anyscale 的 CEO 亲自回应了基准的缺陷问题:
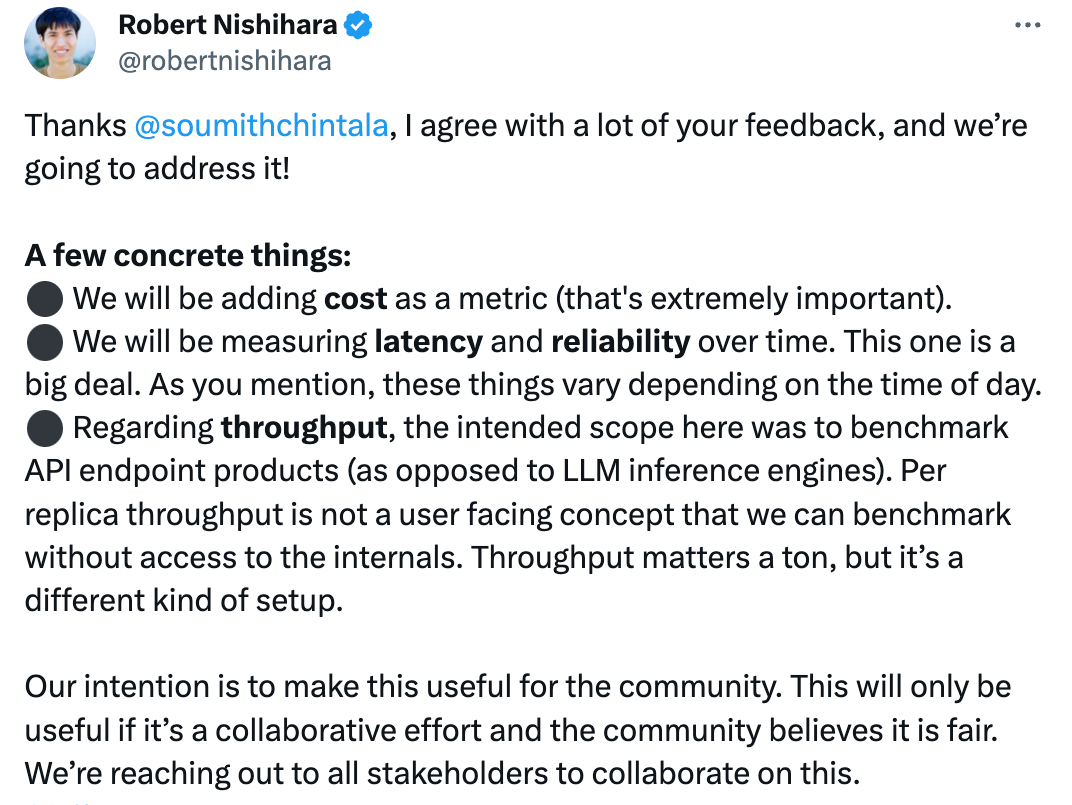
我同意你的很多反馈,我们将解决它!
一些具体的事情:
我们将添加成本作为一个指标(这非常重要)。
我们将随着时间的推移测量延迟和可靠性。正如您提到的,这些事情根据一天中的时间而变化。
关于吞吐量,此处的预期范围是对 API 端点产品进行基准测试(而不是 LLM 推理引擎)。每个副本的吞吐量不是一个面向用户的概念,我们可以在不访问内部的情况下进行基准测试。吞吐量非常重要,但这是一种不同的设置。
我们的目的是使其对社区有用。仅当其成为共同努力并且社区认为这是公平时,它才会有用。我们正在与所有利益相关者联系以就此进行合作。
与此同时,Anysacle 也在邀请各位 API 提供商共同参于排行版的「修正」:


对于此事,你怎么看?