













一年一度的年终盘点来了!
2023年,计算机科学领域大事件人人都能脱口而出,火遍全网的ChatGPT一系列大模型、AI作画神器Midjourney,AI视频生成Gen-2、Pika飞速迭代......

在「P与NP」最经典的问题上,研究人员取得了微妙但重要的进展。
秀尔算法(Shor’s algorithm),量子计算的杀手级应用程序,在近30年后进行了首次重大升级。还有研究人员终于学会了如何在理论上通过一种普通类型的网络,以最快速度找到最短路径。
此外,加密学家在与AI建立意想不到的连接时,展示了机器学习模型和机器生成内容也必须应对隐藏的漏洞和消息。
Top 1:50年P与NP难题,「元复杂性」理论开路
50年来,计算机科学家一直试图解决所在领域中最大,且悬而未决的问题,即「P与NP」。
简单讲,「P与NP」就是探讨已知的困难的计算问题,具体有多难,是否存在更高效的算法。
但是,50年来想要解决这个问题的科学家们,都以失败而告终。

就在许多科学家感觉快要有突破的时候,总是会遇到无法跨越的障碍,证明他们的方法行不通。
久而久之,科学家开始质疑,为什么就连证明一个问题「很难」本身也这么困难。
在回答这类内省式问题的努力中,出现了一个新兴的领域「元复杂性」(meta-complexity)理论。它为这个问题提供了迄今为止最好的见解。
8月,Quanta一篇文章中曾介绍了「元复杂性」的理念,以及科学家们开始的探索。

三位数学家对数学推理的局限性不同看法
「P与NP」问题破解,能够解决无数日志问题,使所有密码学毫无意义,甚至揭示人类能够知晓的事物的本质。
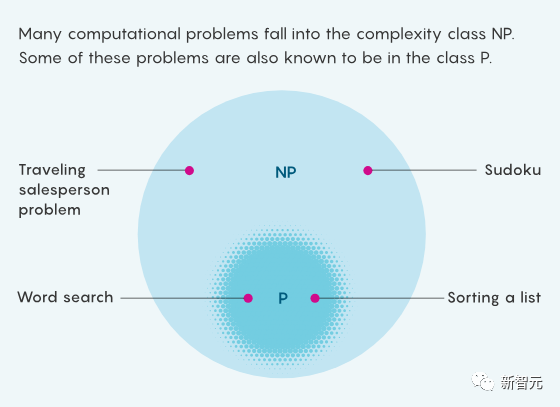
简单来说,P是那些可以轻松解决的问题,比如按字母顺序排列。NP是那些解决方案易于检查的问题,如数独。
由于所有易于解决的问题也易于检查,所以P中的问题也属于NP。
但有些NP问题似乎很难解决,你无法在不先尝试许多可能性的情况下直观地得出数独难题的解决方案。
通过研究这些内省式问题,研究人员了解到,证明计算难度的困难程度,与乍看起来似无关的基本问题密切相关。
在明显随机的数据中发现隐藏的模式有多难?如果确实存在真正困难的问题,那么这些问题多久会出现一次?
德克萨斯大学奥斯汀分校的复杂性理论家Scott Aaronson表示,「很明显,元复杂性与事物的核心关系密切」。

「P与NP」问题引领研究人员进入「元复杂性」理论艰难的旅程。
然而对于「元复杂性」的研究人员来说,这段在未知领域的旅程就是它自身的回报。
Top 2:大模型涌现,黑盒谁能打开
涌现,可以成为大模型领域年度热词。
OpenAI团队曾在2022年一篇论文中,给「涌现」下了一个定义:
在参数规模较小的模型中不存在,在规模较大的模型中存在,那么这种能力就是涌现。

比如,你给大模型几个表情包,然后询问这代表着什么电影?LLM会根据已有的知识,去预测下一个token,最后给出答案。

答案:海底总动员
不仅如此,小模型无法完成的任务,其中许多似乎与分析文本没有什么关系,从乘法到生成可执行的计算机代码,再到显然基于表情符号对电影进行解码。
OpenAI这项研究也表明,对于一些任务和一些模型,存在一个复杂性阈值,超过这个阈值,模型的能力会迅速增长。
但是,不得不承认,随着LLM能力不断增长,引发了新的担忧。
这些强大的AI系统不仅编造谎言,制造社会偏见,甚至连人类语言中一些最基本的元素都无法处理。
最重要的是,这些AI仍旧是一个黑盒,内部推理逻辑无法得知。
不过,在打开AI「黑盒」上的研究也在不断涌现。比如,OpenAI团队用GPT-4去解释30万个GPT-2神经元,甚至在最新研究中提出用GPT-2监督GPT-4。
总而言之,揭开大模型内部运作机制还有很长的路要走。
Top 3:40年前算法,找到最短路径
计算机科学家很早就知道,可以快速遍历图网络的算法(由边连接的节点网络),而且其中的连接是有一定成本的,比如连接两个城市的收费公路。
但几十年来,如果只考虑一条路的成本和回报,科学家找不到任何快速算法来确定最短路径。
去年年底,来自罗格斯大学的3位研究人员提出了一种可行的算法。
他们的新算法找到了从一个给定的「源」节点到每一个其他节点的图中的最短路径,几乎赶上了很久以前正权重算法所达到的速度。

论文地址:https://arxiv.org/abs/2203.03456
值得一提的是,Dijkstra这一算法早在1956年,是由荷兰计算机科学家Edsger Dijkstra开发的快速算法,可以在只有正权的图上找到最短路径。
对此,研究人员反转思路,给出了负权图的最短路径算法。
今年3月,芝加哥大学的华人计算机科学家Xiaorui Sun提出了一种更快的算法,以更快的速度打破了群同构问题中最难解决的实例。
论文地址:https://arxiv.org/abs/2303.15412
它可以精确地确定两种被称为组的数学对象何时相同。
此外,今年的其他重大算法新闻还包括,通过结合随机和确定性方法计算素数的新方法,反驳了一个关于信息有限算法性能的长期猜想。
以及一项分析,展示了一个非直观的想法如何提高渐降算法的性能,梯度下降算法在机器学习程序和其他领域中随处可见。
Top 4:AI生图爆火,背后技术沉淀多年
今年,DALL·E、Midjourney、Stable Diffusion等图像生成工具,深受人们欢迎。
只需给一个文字提示,AI就可以按照你的要求创作出一幅艺术作品。
不过,这些AI艺术家背后的技术,其实早已经历了多年的积累——
扩散模型(diffusion models)基于的是物理学中流体扩散的原理,它们能有效地把模糊的噪声转换为清晰的图形——就好比将咖啡中混合均匀的奶油再次分离出来,恢复成清晰的形状。
此外,AI工具在提高现有图像的清晰度方面也取得了进展,虽然这距离电视剧中警察反复大喊「增强!」的场景还有很长的路要走。
最近,研究人员开始研究扩散以外的其他物理过程,来寻找机器生成图像的新方法。
其中一种新的方法是基于泊松方程(Poisson equation)——用于描述电场力随距离变化的过程。这种方法已经证明在处理错误方面更加高效,并且在某些情况下比扩散模型更容易训练。
Top 5:30年后,量子因数分解运算速度飙升
几十年来,秀尔算法(Shor’s algorithm)一直被视为量子计算机强大能力的象征。
这套由Peter Shor在1994年开发的算法,让量子计算机能够利用其量子物理特性,比经典计算机更快地将大数分解为质因数。而这对目前大部分的互联网安全系统,构成了潜在威胁。
2023年8月,一位计算机科学家开发出了一个更快的Shor算法变体,这是自该算法被发明以来的首次重大改进。

尽管如此,真正实用的量子计算机仍然遥不可及。
在实际应用中,微小的误差会迅速累积,从而破坏计算结果,并进一步消除了量子计算带来的所有优势。
事实上,去年年底,一组计算机科学家的研究表明,对于一个特定的问题,经典算法与包含误差的量子算法大致相同。
但希望还是有的:8月的研究显示,某些纠错码(称为低密度奇偶校验码)的效率,至少是现行标准的10倍。
Top 6:密码学+AI的隐藏秘密
在密码学和人工智能交叉领域的一项不寻常研究中。
最近,一组计算机科学家证明了可以在机器学习模型中嵌入后门,这些后门不仅几乎无法被发现,而且它们的隐蔽性得到了类似于现代最先进加密技术的逻辑支持。

不过,团队主要研究的是较简单的模型,因此目前还不清楚这一发现是否也适用于当今AI技术中使用的更复杂的模型。
然而,这些研究成果为未来系统如何防御这类安全漏洞提供了可能的方向。
正是因为这类安全问题,Cynthia Rudin强烈推荐使用可解释的模型,来更深入地了解机器学习算法内部的运作机制。
与此同时,像Yael Tauman Kalai这样的研究人员,也在安全性和隐私领域取得了进展,而这对即将到来的量子技术来说极为重要。
而在隐写术这一相关领域,研究成果展示了如何在机器生成的媒体中以绝对安全的方式隐藏信息。
Top 7:向量注入语义,让LLM推理更高效
尽管人工智能已经非常强大,但支撑大多数现代系统的人工神经网络存在两大问题:
1. 在训练和运行时需要消耗大量资源
2. 容易变成难以理解的「黑箱」
因此,很多研究人员都认为,现在或许是采取新方法的时候了——
通过成千上万的超维向量来表现概念,而不是用人工神经元来检测单个特征或特性。
这种系统用途更广,处理错误的能力更强,计算效率也高得多。
而且,研究人员还可以直接操作模型所考虑的想法和关系,从而更深入地了解它的推理过程。
今年3月,苏黎世IBM研究院的团队,使用带有神经网络的超维计算来解决抽象视觉推理中的一个经典问题——「瑞文的递进矩阵」。
它将几何对象的图像呈现在一个3x3的网格中。网格中的一个位置为空,对象必须从一组候选图像中选择最适合空白的图像。

为了使用超维计算解决这个问题,该团队首先创建了一个超向量字典来表示每幅图像中的对象。
字典中的每个超向量代表一个对象及其属性的某种组合。
然后,该团队训练神经网络来检查图像并生成一个双极超向量,一个元素可以是+1或−1,它尽可能接近字典中超向量的某种叠加。
因此,生成的超向量包含关于图像中所有对象及其属性的信息。
他们提出的方法在一组问题上的准确率接近88%,而仅使用神经网络的解决方案的准确率不到61%。
目前超维计算尚处于初期阶段,但随着其在更大规模的测试中的应用,我们可能会看到这种新方法开始展现其潜力。






















