译者 | 朱先忠
审校 | 重楼
简介
在本文中,我们将从基础设施供应到配置管理和部署等各个环节来全方位探讨大型语言模型(LLM)是否适合应用于实际应用程序的生命周期开发。这项工作产生的源代码工程已经在GitHub上公开([参考资料11])。基础设施即代码(IaC:Infrastructure as Code)解决方案通过代码而不是手动流程来促进应用程序基础设施的管理和供应([参考资料1])。

当下,这种技术的应用越来越普遍,一些主流的云提供商已经实现了他们自己风格的IaC解决方案,用于与他们所提供的服务进行交互。在这方面,亚马逊CloudFormation、谷歌的云部署管理器和微软的Azure资源管理器模板都成功简化了云服务端的供应,消除了IT运营人员手动启动服务器、数据库和网络的需要。然而,这许多的可能性也导致了供应商锁定的风险,因为给定云提供商所需IaC的定义是不可移植的,并且如果需要不同的云提供商的话,则需要在它们之间进行转换。
值得欣慰的是,在这方面,像Terraform([参考资料2])或Pulumi([参考资料3])这样的工具提供了对不同云提供商的各种实现的抽象,并促进了便携式部署的开发。通过这种方式,供应商锁定的风险大大降低,应用机构就可以对其需求做出动态反应,而不会产生显著的实施成本。除此之外,IaC技术还带来了许多好处([参考资料4]):
- 一致性:通过实现可重复的部署,实现了基础设施供应的自动化。
- 降低风险:促进了对基础设施管理的不易出错的近似,因为手动干预被最小化。
- 成本优化:可以更容易地识别不必要的资源,有利于在云提供商之间更快地迁移以应对计费变化。
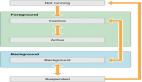
- 改进的协作:可以把脚本集成到版本控制工具中,从而促进个人和团队之间的协作。但是,这样一来,应用程序的生命周期超出了基础架构资源调配的范围。下图显示了使用不同IaC技术支持的应用程序生命周期([参考资料5])。

“基础结构即代码(IaC)”技术支持的应用程序生命周期。|资料来源:Josu Diaz de Arcaya等人([参考资料5])。
在这种情况下,IaC技术的目标不仅仅是提供基础设施资源。在启动必要的基础设施之后,配置管理阶段可确保所有需求都得到适当的安装。此阶段通常使用Ansible([参考资料6])、Chef([参考资料7])、Puppet([参考资料8])等工具来完成。最后,应用程序部署通过各种基础设施设备来监督应用程序的协调性。
认识LLM
大型语言模型(LLM)是指一类人工智能模型,旨在根据提供给它们的输入来理解和生成类似人类的文本。这些模型以其大量的参数而闻名,这些参数使它们能够捕捉语言中的复杂模式和细微差别([参考资料9])。
- 文本生成:LLM创建的文本可以具有凝聚力,并与其周围环境相关。这些技术可以用来完成文本、制作材料,甚至进行创造性写作等活动。
- 自然语言理解:LLM能够理解和提取文本中的信息。它们能够进行态度分析、文本分类和信息检索。
- 翻译:LLM可以将文本从一种语言翻译成另一种语言。这对机器翻译应用非常有益。
- 回答问题:LLM可以根据给定的上下文回答问题。它们经常被应用于聊天机器人和虚拟助理,以回答用户的查询。
- 文本摘要:LLM可以将长段落的文本总结为更短、更连贯的摘要。这对于浓缩信息以便快速利用的领域需求非常有用。在上述诸多功能中,我们将专注于文本生成方面的讨论。特别是,在基于输入提示生成正确的IaC代码的能力方面,大型语言模型(LLM)在自然语言处理领域取得了重大进展,但也提出了一些挑战和令人担忧的问题。目前情况下,与LLM相关的一些关键问题和关注点包括:
- 偏见和公平性:LLM可以学习它们所训练的数据中存在的偏见信息,由此可能导致存在偏见或不公平的结果。
- 错误信息和虚假信息:LLM可能产生虚假或误导性信息,这可能会导致错误信息在网上的传播。这些模型有可能创造出看似可信但事实上不正确的内容。
- 安全和隐私:LLM可能被滥用来生成恶意内容,如深度伪造文本、假新闻或钓鱼性质的电子邮件等。
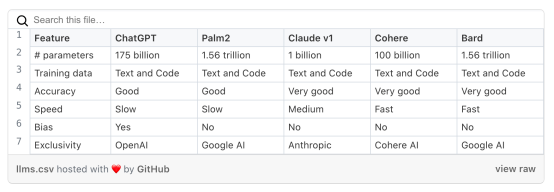
下表展示了各种LLM之间的比较情况。
使用大型语言模型生成IaC
为了测试当前LLM工具在IaC领域的性能,我们设计了一个测试性质的应用程序。此案例的最终目标是使用基于Python的服务器端FastAPI框架在虚拟机中构建一个API,该框架允许客户端使用HTTP方法在Elasticsearch集群中执行搜索和删除任务。
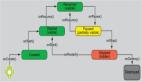
此集群将由三个节点组成,每个节点都位于自己的虚拟机中;在另一台机器中安装Kibana,这是一个支持可视化的集群管理工具。当然,此实验案例设计的一切都必须安装在AWS云环境中。下图显示了此案例的体系结构:
 设计用于测试LLM生成IaC的可行性的应用案例
设计用于测试LLM生成IaC的可行性的应用案例
开发过程中,具有挑战性的任务在于使用LLM工具成功完成以下三项任务。在本文中,我们使用了OpenAI公司的ChatGPT模型。
- 编写Terraform声明式编码,以便在AWS云平台中使用五个虚拟机构建基础设施。
- 编写FastAPI应用程序的源代码,通过基于API的HTTP方法执行文档搜索和删除操作。
- 编写Ansible自动化管理代码,用于在三个节点上部署和安装Elasticsearch集群、在另一个节点上安装Kibana以及在其余节点上安装FastAPI应用程序的可靠代码。
挑战任务#1
对于上面的挑战1,我们针对ChatGPT模型使用了英文提示,翻译成中文后大致意思是:
“我需要通过Terraform在您想使用的公共云提供商处创建五个虚拟机。这些虚拟机的用途如下:其中三个用于部署Elasticsearch集群,该集群每天将接收2G的数据;另一个是Kibana;最后一个是部署FastAPI应用程序。您应该为每个虚拟机选择硬件,并为每个虚拟机器选择云提供商。对于您不知道的变量,使用变量作为占位符即可。最后,请推荐使用廉价的应用实例。”
ChatGPT模型最初的响应很好,但是我们需要不断迭代。例如,我们希望在一个单独的文件中定义所有变量,这导致了下面的配置代码。
variable "region" {
description = "Region where the resources will be provisioned"
default = "us-west-1"
}
variable "instance_type_elasticsearch" {
description = "Instance type for Elasticsearch nodes"
default = "t2.micro"
}
variable "instance_type_kibana" {
description = "Instance type for Kibana"
default = "t2.micro"
}
variable "instance_type_fastapi" {
description = "Instance type for FastAPI application"
default = "t2.micro"
}
variable "ami" {
description = "AMI ID for the virtual machines"
default = "ami-0f8e81a3da6e2510a"
}
variable "my_ip" {
description = "Your public IP address"
default = "0.0.0.0/0"
}
variable "ssh_port" {
description = "Port for SSH access"
default = 22
}
variable "http_port" {
description = "Port for HTTP access"
default = 80
}
variable "https_port" {
description = "Port for HTTPS access"
default = 443
}
variable "key_name" {
description = "Name of the SSH key pair"
default = "my-key-pair"
}文件variables.tf的部分代码摘录,其中包含要配置的变量
同样,我们希望知道部署的IP地址,并且我们希望此配置位于一个单独的文件中。
output "elasticsearch_ips" {
value = aws_instance.elasticsearch.*.public_ip
}
output "kibana_ip" {
value = aws_instance.kibana.*.public_ip
}
output "fastapi_ip" {
value = aws_instance.fastapi.*.public_ip
}文件output.tf的代码摘录,包含新提供的虚拟机的IP地址
人工智能在描述我们想要的实例方面做得很好,并为每个实例配置了所需的安全组。
resource "aws_instance" "elasticsearch" {
count = 3
ami = var.ami
instance_type = var.instance_type_elasticsearch
security_groups = [aws_security_group.ssh_sg.name]
key_name = aws_key_pair.ssh_key.key_name
}
resource "aws_instance" "kibana" {
count = 1
ami = var.ami
instance_type = var.instance_type_kibana
security_groups = [aws_security_group.ssh_sg.name]
key_name = aws_key_pair.ssh_key.key_name
}
resource "aws_instance" "fastapi" {
count = 1
ami = var.ami
instance_type = var.instance_type_fastapi
security_groups = [aws_security_group.ssh_sg.name]
key_name = aws_key_pair.ssh_key.key_name
}
resource "aws_security_group" "ssh_sg" {
ingress {
from_port = var.ssh_port
to_port = var.ssh_port
protocol = "tcp"
cidr_blocks = [var.my_ip]
}
}
resource "aws_security_group" "http_sg" {
ingress {
from_port = var.http_port
to_port = var.https_port
protocol = "tcp"
cidr_blocks = [var.my_ip]
}
}
resource "aws_key_pair" "ssh_key" {
key_name = var.key_name
public_key = file("~/.ssh/id_rsa.pub") # Provide the path to your public key file
}文件main.tf的代码摘录,其中包含要配置的虚拟机
它还为我们想要的安全组创建了必要的资源,并在将各种端口定义为变量时使用占位符。请参考前面文件main.tf中与使用的安全组部分相关的代码。
总的来说,ChatGPT在完成这项任务方面做得很好。然而,我们花了一段时间才获得可行的配置,并保证网络配置是正确的。例如,我们希望连接到每个已配置的虚拟机,并通过进一步的提示词来提出对这方面的要求,翻译成中文的大致意思是:
我希望通过ssh从我的笔记本电脑访问所有这些实例,而且,Kibana实例需要从我的手提电脑上以http和https两种方式进行访问。
上面的提示产生了一个几乎正确的代码,出现小问题的原因是AI与入口和出口策略混淆了。然而,这很容易发现并修复。
在能够访问虚拟机之后,由于缺乏权限,我们遇到了无法连接到它们的问题。这导致了与ChatGPT更长的对话,最终我们自己也通过很容易地添加少量修改内容解决了问题。
挑战任务#2
对于上面的挑战2,我们针对ChatGPT使用了以下提示,翻译成中文后的大致意思是:
“我需要创建一个FastAPI应用程序。这些API的目的是提供在Elasticsearch集群中存储单个Json文档、存储多个文档并删除它们的方法。Elasticsearch集群部署在3个节点中,具有用户“tecnalia”和密码“iac-llm”的基本身份验证。”
这一提示的结果非常成功。该应用程序使用Elasticsearch Python包,与Elasticsearch集群进行交互,而且经测试是完全有效的。只是我们必须记住,我们需要更改部署集群的节点的IP地址。在下图中,创建了第一个方法,用于在Elasticsearch中插入单个文档。
from fastapi import FastAPI, HTTPException
from elasticsearch import Elasticsearch
app = FastAPI()
# 使用集群节点初始化Elasticsearch客户端
es = Elasticsearch(
['node1:9200', 'node2:9200', 'node3:9200'],
http_auth=('tecnalia', 'iac-llm'))
@app.post("/store-single-document/")
async def store_single_document(document: dict):
try:
# Index a single document into Elasticsearch
response = es.index(index='your_index_name', body=document)
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))存储单个文档方法的代码摘录
然后,第二个方法用于在单个调用中创建各种文档的大容量插入。
@app.post("/store-multiple-documents/")
async def store_multiple_documents(documents: list):
try:
#将多个文档批量插入Elasticsearch
actions = [{"_op_type": "index", "_index": 'your_index_name', "_source": doc} for doc in documents]
response = es.bulk(actions)
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))存储多个文档方法的代码摘录
最后的一种方法可以用于从Elasticsearch集群中删除单个文档。
@app.delete("/delete-document/{document_id}")
async def delete_document(document_id: str):
try:
#按文档ID删除文档
response = es.delete(index='your_index_name', id=document_id)
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))删除文档方法的代码摘录
我们认为这个实验非常成功,因为它正确地选择了一个合适的库来完成任务。然而,要将这些代码转化为可用于生产环境的软件的话,还需要进一步的手动改进。
挑战任务#3
对于上面的挑战3,我们使用了以下提示,翻译成中文后的大致意思是:
“生成Ansible配置代码,用于在三个节点上安装Elasticsearch集群。还请添加一个连接到集群的Kibana节点。”
这个提示在生成所需的Ansible脚本方面做得很好。它在将源代码组织成各种文件方面做得很好。首先,包含所有节点详细信息的清单。请记住,此文件需要使用任务#1中生成的正确IP地址进行调整。
[elasticsearch]
node1 ansible_host=192.168.56.101
node2 ansible_host=192.168.56.102
node3 ansible_host=192.168.56.103
[elasticsearch:vars]
ansible_user=vagrant文件inventory.ini的代码摘录
然后,下面显示了安装Elasticsearch的主要脚本。这是它的摘录,完整的示例可以在Github存储库([参考资料11])中找到。
---
- name: Install Elasticsearch Cluster
hosts: elasticsearch
become: yes
tasks:
- name: Add Elasticsearch GPG Key
apt_key:
url: https://artifacts.elastic.co/GPG-KEY-elasticsearch
state: present
- name: Add Elasticsearch APT Repository
apt_repository:
repo: "deb https://artifacts.elastic.co/packages/7.x/apt stable main"
state: present
filename: "elastic-7.x"
- name: Update apt cache
apt:
update_cache: yes
- name: Install OpenJDK
apt:
name: openjdk-11-jdk
state: present
- name: Install Elasticsearch
apt:
name: elasticsearch
state: present
- name: Configure Elasticsearch Cluster
template:
src: elasticsearch.yml.j2
dest: /etc/elasticsearch/elasticsearch.yml
notify:
- Restart Elasticsearch
handlers:
- name: Restart Elasticsearch
systemd:
name: elasticsearch
enabled: yes
state: restartedElasticsearch_playbook.yml的代码摘录
另一方面,每个Elasticsearch节点的必要配置已方便地生成为Jinja文件。在这种情况下,我们不得不手动添加path.logs和path.data配置,因为Elasticsearch由于权限问题无法启动。
cluster.name: your_cluster_name
node.name: "{{ ansible_hostname }}"
network.host: 0.0.0.0
discovery.seed_hosts:
- 192.168.56.101
- 192.168.56.102
- 192.168.56.103
cluster.initial_master_nodes:
- 192.168.56.101
path.logs: /var/log/elasticsearch
path.data: /var/lib/elasticsearchelasticsearch.yml.j2的代码摘录
类似地,ChatGPT能够为Kibana实例生成类似的配置。但是,在这种情况下,为了方便起见,我们手动将配置分离到一个单独的.yml文件中。
类似地,引用Kibana实例的Jinja文件看起来也非常不错,尽管IP地址最好参数化。
总的来说,我们发现ChatGPT非常擅长制作项目的框架。然而,要将该框架转化为生产级应用程序,仍然需要执行大量操作。在这方面,需要对所使用的技术有深入的专业知识,以便更好地细化项目。
结论
本文介绍了使用ChatGPT这种大型语言模型来监督应用程序的生命周期的完整过程。接下来,简要讨论一下这种工作方式的利弊。
优点
- 使用LLM来支持应用程序生命周期的各个阶段对启动项目特别有益,尤其是在众所周知的技术中。
- 最初的框架结构良好,这种技术提供了开发团队原本可能不会使用的结构和方法。
不足
- LLM存在与人工智能解决方案的使用相关的偏见风险;在本文实例中,ChatGPT选择了AWS云平台,而不是类似的方案选项。
- 将项目打磨为真正可用的生产环境项目可能会很麻烦,而且有时手动调整代码更容易,这需要对所使用的技术有广泛的了解。
鸣谢
这项工作由巴斯克政府的SIIRSE Elkartek项目资助(适用于Industry 5.0的稳健、安全和合乎道德的智能工业系统:一个规范、设计、评估和监控的先进范例,Elkartek 2022 KK-2022/00007)。
作者贡献
本文概念化、分析、调查和最终成稿是Juan Lopez de Armentia、Ana Torre和Gorka Zárate三人共同努力的结果。
参考资料
- What is Infrastructure as Code (IaC)? (2022). https://www.redhat.com/en/topics/automation/what-is-infrastructure-as-code-iac
- Terraform by HashiCorp. (n.d.). Retrieved October 5, 2023, from https://www.terraform.io
- Pulumi — Universal Infrastructure as Code. (n.d.). Retrieved October 5, 2023, from https://www.pulumi.com/
- The 7 Biggest Benefits of Infrastructure as Code — DevOps. (n.d.). Retrieved October 5, 2023, from https://duplocloud.com/blog/infrastructure-as-code-benefits/
- Diaz-De-Arcaya, J., Lobo, J. L., Alonso, J., Almeida, A., Osaba, E., Benguria, G., Etxaniz, I., & Torre-Bastida, A. I. (2023). IEM: A Unified Lifecycle Orchestrator for Multilingual IaC Deployments ACM Reference Format. https://doi.org/10.1145/3578245.3584938
- Ansible is Simple IT Automation. (n.d.). Retrieved October 5, 2023, from https://www.ansible.com/
- Chef Software DevOps Automation Solutions | Chef. (n.d.). Retrieved October 5, 2023, from https://www.chef.io/
- Puppet Infrastructure & IT Automation at Scale | Puppet by Perforce. (n.d.). Retrieved October 5, 2023, from https://www.puppet.com/
- Kerner, S. M. (n.d.). What are Large Language Models? | Definition from TechTarget. Retrieved October 5, 2023, from https://www.techtarget.com/whatis/definition/large-language-model-LLM
- Sha, A. (2023). 12 Best Large Language Models (LLMs) in 2023 | Beebom. https://beebom.com/best-large-language-models-llms/
- Diaz-de-Arcaya, J., Lopez de Armentia, J., & Zarate, G. (n.d.). iac-llms GitHub. Retrieved October 5, 2023, from https://github.com/josu-arcaya/iac-llms
- Elastic Client Library Maintainers. (2023). elasticsearch · PyPI. https://pypi.org/project/elasticsearch/
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Mastering the Future: Evaluating LLM-Generated Data Architectures leveraging IaC technologies,作者:Josu Diaz de Arcaya