












我们今天的AI能做到哪些事情?
AI画图、AI作曲、AI生成视频、AI写小说、AI做主播......
然而,在最近的NeurIPS大会上,来自GrapheneX-UTS的研究人员带来了更震撼的应用场景——AI读心术BrainGPT!

论文地址:https://arxiv.org/pdf/2309.14030v2.pdf
如果AI能知道你心中所想,会发生什么事情?小编可不敢想象。
视频里研究团队为大家展示了AI读心术的现场。
参加测试的人在心中默念一个文本段落,通过一套传感器采样脑电波,然后由一个名为DeWave的AI模型,将脑电波翻译成语言,并投射到屏幕上。
整个过程有点科幻的味道了,尤其是背景音乐,让小编莫名想到了《星际穿越》。
这项研究被选为今年NeurIPS会议的焦点论文(Spotlight ),研究团队来自悉尼科技大学的GrapheneX-UTS(以人为本的人工智能中心)。
UTS计算机科学学院杰出教授,兼GrapheneX-UTS HAI中心主任Chin-Teng Lin教授表示,这项研究代表了将原始脑电波直接翻译成语言的开创性努力,标志着该领域的重大突破。
「这是第一个将离散编码技术纳入脑到文本翻译过程的方法,引入了一种创新的神经解码方法,与大型语言模型的集成也为神经科学和人工智能开辟了新的领域。」

——还好还好,需要戴个头套,AI才能「听见」人类心里在想什么,这要是能隔空摄取意念可就麻烦了。
如果是小编参加这个测试,估计压力挺大的,
——毕竟不知道默念文本和心里的想法是不是一回事,AI会不会把我脑袋里的其他想法也顺道给读出来?

小编不由得想起了霍金老前辈,也许在某个平行世界里,他老人家可以用上这样的一套BrainGPT吧。
而小编我呢?还需要面对着电脑屏幕敲键盘吗?不需要了!小编只需躺在床上,动动脑子,就把这班给上了。
在这项工作中,模型把脑电波信号分割成不同的单元,从中捕获特定的特征和模式。
DeWave模型通过从大量脑电数据中学习,获得了将脑电图信号转换为单词和句子的能力。
除了可以帮助因疾病或受伤(中风、瘫痪等)而无法说话的人进行交流,BrainGPT还可以实现人与机器之间的无缝通信,例如仿生手臂或机器人的操作。
以前将大脑信号转换为语言的技术,要么需要手术在大脑中植入电极(例如马斯克的Neuralink),要么在MRI机器中扫描。
前者为侵入性,而后者体积大,价格昂贵,且难以在日常生活中使用。
另外,这些方法一般需要眼动追踪等额外辅助工具,来帮助将大脑信号转换为单词级片段,而BrainGPT并没有这个限制。

这项研究测试了29名参与者。因为脑电波因人而异,所以BrainGPT所表现出的解码技术更强大、适应性也更强。
当然,比起向大脑植入电极,通过这种外部设备接收到的脑电图信号会更嘈杂,——不过从翻译结果来看,准确率也很不错。
BrainGPT在BLEU-1的翻译准确率得分,目前约为40%。
(BLEU分数是一个介于0和1之间的数字,用于衡量机器翻译文本与一组高质量参考翻译的相似性。)
研究人员认为这套系统将来有望把准确率做到接近90%,——这将是与传统语言翻译,或语音识别程序相当的水平。
论文作者认为,目前的模型更擅长匹配动词,而涉及到名词时可能不够精确。这是因为当大脑处理这些单词时,语义上相似的单词可能会产生相似的脑电波模式。
论文细节
论文引入了一个新的框架——DeWave,它将离散编码序列集成到开放词汇的脑电图到文本的翻译任务中。
DeWave使用量化变分编码器来派生离散的编码,并将其与预先训练的语言模型对齐。
这种离散表示有两个优点:1)通过引入文本-脑电对比对齐训练,实现了无标记原始波的平移;2)通过不变的离散编码,减轻了脑电波个体差异引起的干扰。
利用离散编码,DeWave是第一个实现原始脑电波到文本翻译的工作,同时引入了自监督波编码模型,和基于对比学习的脑电到文本对齐,以提高编码能力。
DeWave模型在使用ZuCo数据集的测试中,BLEU-1分数达到了41.35,Rouge-F分数达到了33.71,比之前的基线分别高出了3.06%和6.34%
另外,论文首次在没有单词级顺序标记(例如,眼睛注视)的情况下,进行了整个脑电图信号周期的翻译测试,分别获得了20.5(BLEU-1)和29.5(Rouge-1)。
研究方法
DeWave的整个过程如下图所示,原始EEG特征被矢量化为嵌入的序列,并送到离散的编码中,语言模型基于离散的编码表示形式生成翻译输出。
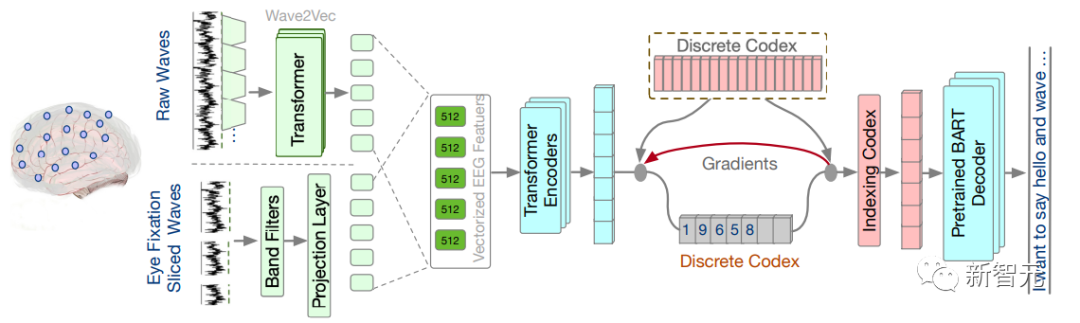
DeWave模型结构涉及将词级脑电图特征,或原始脑电图波矢量化为嵌入,然后将矢量化的特征编码为一个潜在变量,该变量通过索引转换为离散的编码。最后,预先训练的BART模型将这种离散的编码表示转换为文本。
给定一系列单词级脑电图特征E,目的是解码相应的开放词汇文本标记W。这些脑电图文本对(E、W)是在自然阅读期间收集的,
这里设置两个训练任务:(1)单词级脑电图到文本翻译,其中脑电图特征序列E被分割,并根据序列W中的每个单词的标记,进行重新排序;
(2)原始脑电波到文本翻译,其中脑电特征序列E直接矢量化为嵌入序列进行翻译,没有任何事件标记。
离散编码
DeWave是第一个将离散编码引入EEG信号表示的工作。
离散表示有利于词级脑电图特征和原始脑电波转换。将离散编码引入脑电波可以带来两个方面的优势:
第一点,脑电图特征在不同人类受试者之间具有很强的数据分布差异。同时,由于数据收集的费用,数据集只能包含来自少数人类受试者的样本,这严重削弱了基于脑电图的深度学习模型的泛化能力。
而通过引入离散编码,可以在很大程度上缓解输入方差。
第二点,编码包含较少的时间属性,可以缓解事件标记(如眼睛注视)和语言输出之间的顺序不匹配问题。
脑电图矢量化
为了得到带有事件标记的单词级脑电图特征,首先根据注释中给出的单词序列的眼动追踪标记,将脑电波切片。
这里计算了4个频段滤波器的统计结果(Theta波段(5-7Hz)、Alpha波段(8-13Hz)、Beta波段(12-30Hz)和Gamma波段(30Hz-)),得到每个片段的统计频率特征。
需要注意的是,尽管不同的片段可能具有不同的脑电图窗口大小,但统计结果是相同的(嵌入大小840)。
应用多头Transformer层将嵌入投影到大小为512的特征序列中。
使用自监督脑电波编码器,将原始脑电信号转换为一系列嵌入:
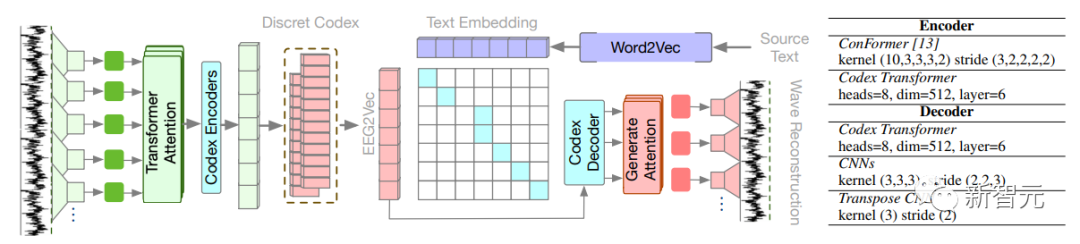
上图展示了原始波的自监督预训练过程。左边的子图详细介绍了通过对比学习,利用自我重建和文本对齐来引导编码器的策略。
这里有两个指导原则:一个是自我重建,训练编码器能力的同时,也从离散编码中重建原始波形;
另一个是文本对齐,编码在语义上与词向量对齐。
在结构方面,采用了基于一致性的多层编码器,这个编码器具有专门设计的超参数。
一维卷积层用来处理脑电波以生成嵌入序列,然后将脑电通道融合为每个周期的唯一嵌入。这里将双向Transformer注意力层应用于序列以捕获时间关系。
通过这种方式,该模型不仅可以学习重建脑电图信号,还可以学习与相应文本嵌入一致的信号的鲁棒表示。
这种跨模态学习可以弥合脑电图信号和文本语义内容之间的差距,并改善翻译系统。
实验结果
DeWave利用ZuCo 1.0和2.0进行实验。该数据集同时记录了正常阅读(NR)和特定任务阅读(TSR)任务期间的文本和脑电图语料库。
脑电波是用128通道系统,在500Hz的采样率下通过0.1Hz至100Hz的频带滤波器收集的。不过在降噪之后,只有105个通道用于翻译。
实验中根据眼睛注视对脑电波进行切片,并计算频率特征。对于原始脑电波,信号被归一化为0-1的值范围以进行解码。
阅读任务的数据分别分为训练(80%)、发展(10%)和测试(10%),句子数量分别为10874、1387和1387个,没有交集。
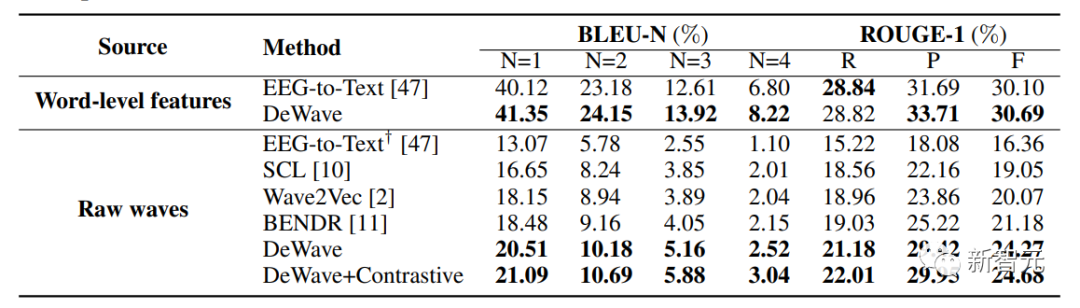
这里使用NLP指标BLEU和ROUGE评估翻译性能,如上表所示。
对于单词级脑电图特征,将结果与脑电图转文本进行比较,以保持一致的语言模型。
在缺乏原始脑电波的方法的情况下,通过使用200毫秒的时间窗口和100毫秒的重叠,将整个脑电波分割成序列嵌入,来建立基线(脑电图到文本)。
实验中将最初为语音识别开发的Wave2Vec改编为脑电波,并将其与DeWave进行比较。
此外,实验还采用无监督的原始脑电波分类方法BENDR和SCL,使用SSL预训练和特征提取进行比较,强调了离散编码的影响。
因为跨学科性能对于实际应用至关重要,所以这里进一步提供了与基线方法,和具有代表性的元学习方法MAML的比较。

上表展示了18 名人类受试者的平均表现,指标越低越好。我们可以看出DeWave模型在两种设置(直接测试和使用MAML)中都显示出卓越的性能。
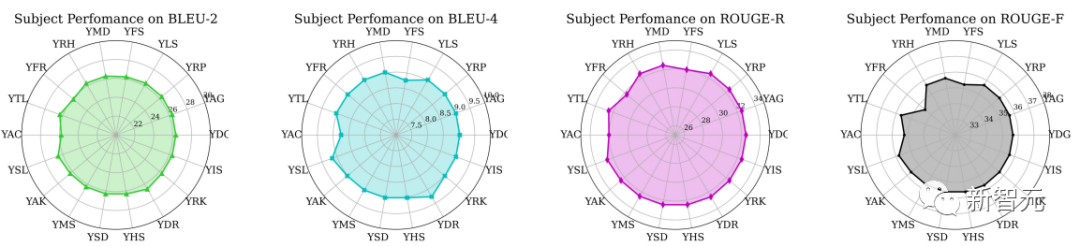
为了进一步说明不同受试者的表现差异,这里仅使用受试者YAG的数据来训练模型,并测试所有其他受试者的指标。
结果如上图所示,我们可以从雷达图中看出,对于不同受试者,模型的表现比较稳定。























