今天我们聊个知识点为什么Redis使用哈希槽而不是一致性哈希。
先看文章大纲,提前了解本期内容
 图片
图片
往期回顾
之前小许用图文并茂的方式用一期内容让大家快速了解了一致性哈希算法,看过的朋友应该还有印象,没看过的朋友可以点击这里看一遍《五分钟了解一致性哈希算法》。
看明白这篇一致性哈希算法基础,会对本期内容有更好的认识和对比性。
这里我们再简单回顾下:
一致性哈希算法就很好地解决了分布式系统在扩容或者缩容时,发生过多的数据迁移的问题。
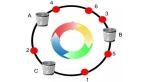
算法是对 2^32 进行取模运算的结果值虚拟成一个圆环,环上的刻度对应一个 0~2^32 - 1 之间的数值。
通过虚拟节点的方式很好的处理了数据不平衡问题。
 图片
图片
不同的计算方式
不知道朋友们记不记得Redis Cluster的实现,也是用了Hash的方式将键值按照一定算法分配到各个节点的,但是却没有使用一致性哈希算法,而是引入了哈希槽的概念!
这是为什么呢?🤔🤔
我们先看下一致性哈希和哈希槽在计算上的区别
 图片
图片
图中A、B、C表示的是三个节点,k1和k2表示的是key:
🔔 一致性哈希是经过 hash() 函数计算后对 2^32 取模的值虚拟成一个圆环
🔔 哈希槽是将每个key通过CRC16计算得到一个16bit的值,然后16bit值再对16384取模来决定放置哪个槽
虽说在计算方式上有区别,好像都解决了数据均衡的问题,应该都是不错的选择。
OK,本文将先对Redis集群节点增减时如何进行哈希槽的分配进行分享,再回过头看为什么Redis 集群没有使用一致性hash,而是引入了哈希槽的概念的原因究竟是什么!
Redis Cluster集群
Redis集群是一种分布式数据库方案,通过服务器分片技术进行数据管理,我们来对它进行一个归纳总结。
哈希槽
集群将数据划分为 16384 (2^14)个槽位(哈希槽),每个Redis服务节点分配了一部分槽位,因为槽位的信息存储于每个节点中,客户端请求的key通过CRC16校验后对16384取模来决定放置哪个槽,这样也就定位到指定的节点中。
 图片
图片
上图中 key 【小许】和【code】经过 CRC16 计算后再对哈希槽总个数 16384 取模,得到哈希槽位置分别是在888的节点A上和10924的节点C上面。
🚩 重点:每个节点都会记录哪些槽分配给了自己,哪些槽被分配给了其他节点
增加节点
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot(槽)到D上,会变成这样:
 图片
图片
此时服务A、B、C、D通过分配各自有了对应的哈希槽,新增节点后集群会自动进行哈希槽的重新平均分配,比如上图中四个节点中每个节点的槽位数是:18384 / 4 = 4096。
当然这个你使用命令 【cluster addslots】为每个节点自定义分配槽的数量,这里有个特点,如果我们节点的机器性能有差异,那就可以为性能好的,配置更多槽位,更好的利用机器性能。
减少节点
如果减少一个节点C,redis cluster同样会自动进行槽数量的重新计算分配,然后后变成下面样子:
 图片
图片
删除节点C之后,此时服务A、B节点中每个节点的槽位数是:18384 / 2 = 8192
客户端访问节点数据
Redis cluster的主节点各自负责一部分槽,我们来看下来自客户端的请求的key是如何定位到具体的节点,然后返回对应的数据的。
 图片
图片
来自Redis-Cli客户端的请求连接到的是集群中的任何一个节点
- 1. 首先检查当前key是否存在集群中的节点
- • 通过CRC16(key)/ 16384计算出slot
- • 查询负责该slot负责的节点是否存在
- 1. 在该节点的话就直接就直接返回key对应的结果
- 2. 不在该节点的话,那么会 MOVED重定向(包含槽位和目标地址)指引客户端转向至正确的节点,并再次发送之前执行的命令
☀️☀️ 相信你也和小许一样觉得这种方式弊端很明显,每次执行命令前都可能现在Redis节点上进行MOVED重定向才能找到要执行命令的节点,额外增加了IO开销。
✏️ 不过大多数开发语言的Redis客户端都采用 Smart客户端 支持集群协议,让整个访问就更高效。
我们来看下是如何实现的!
smart客户端
开发语言写的Redis客户端都会采用Smart客户端来支持访问集群。
主要是在内部维护哈希槽--节点的映射关系,这样就可以在Smart客户端实现键到节点的查找,避免了再进行MOVED重定向。
不过第一步还是初始化时会选择一个运行节点,初始化槽和节点映射关系。
我们看下图:
 图片
图片
上面我们简单讲了下Redis-Cluster中哈希槽和增删节点槽位的转移分配,回归正题。
🚩 为什么Redis是使用哈希槽而不是一致性哈希呢?
有人可能会说是当节点太少时,一致性哈希容易数据分布不均匀更容易导致雪崩。
但是看过我开头分享的一致性哈希文章,通过引入虚拟节点是基本可以避免这个问题的
如果非要说极限情况,那么Redis哈希槽,也有可能某些hash 区间的值特别多,然后导致该节点导访问过于集中的问题。
抛开这些极端情况,通过上面对哈希槽的总结,以下这些是更值得信服的回答:
- • 当发生扩容时候,Redis可配置映射表的方式让哈希槽更灵活,可更方便组织映射到新增server上面的slot数,比一致性hash的算法更灵活方便。
- • 在数据迁移时,一致性hash 需要重新计算key在新增节点的数据,然后迁移这部分数据,哈希槽则直接将一个slot对应的数据全部迁移,实现更简单
- • 可以灵活的分配槽位,比如性能更好的节点分配更多槽位,性能相对较差的节点可以分配较少的槽位
为什么Redis Cluster哈希槽数量是16384?
我们知道一致性哈希算法是对2的32次方取模,而哈希槽是对2的14次方取模
✏️ Redis作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
Redis作者的回答在这里:why redis-cluster use 16384 slots? · Issue #2576 · redis/redis
 图片
图片
总结起来主要有以下因素
- • Redis节点间通信时,心跳包会携带节点的所有槽信息,它能以幂等方式来更新配置。如果采用 16384 个插槽,占空间 2KB (16384/8);如果采用 65536 个插槽,占空间 8KB (65536/8)。
- • Redis Cluster 不太可能扩展到超过 1000 个主节点,太多可能导致网络拥堵。
- • 16384 个插槽范围比较合适,当集群扩展到1000个节点时,也能确保每个master节点有足够的插槽
这也就是为什么哈希槽的数量是16384了!