本文介绍了如何使用Python的pdfplumber库来提取PDF文档中的表格数据,并将提取出的数据保存为Excel文件。
pdfplumber是一个功能强大的Python库,可以用于解析PDF文档并提取其中的文本、表格和图像等内容。
通过使用pdfplumber库,我们可以轻松地从PDF文档中提取表格数据,并将其保存为Excel文件,以便进一步分析和处理。

1. 引言
在日常工作和研究中,我们经常需要从PDF文档中提取表格数据,并进行进一步的分析和处理。
然而,由于PDF文档的复杂性和格式多样性,提取表格数据并保存为Excel文件可能会变得复杂和困难。
为了解决这个问题,我们可以使用Python的pdfplumber库来简化这个过程。
2. 安装pdfplumber库
首先,我们需要安装pdfplumber库。
可以使用pip命令来安装pdfplumber库:
pip install pdfplumber3. 提取PDF文档中的表格数据
接下来,我们将使用pdfplumber库来提取PDF文档中的表格数据。
首先,我们需要导入pdfplumber库:
import pdfplumber然后,我们可以使用pdfplumber的open方法打开PDF文档,并使用pages属性获取文档的所有页面:
with pdfplumber.open('example.pdf') as pdf:
pages = pdf.pages接下来,我们可以使用extract_table方法来提取每个页面中的表格数据。
该方法将返回一个二维列表,其中每个元素代表一个单元格的内容:
tables = []
for page in pages:
table = page.extract_table()
tables.append(table)4. 保存表格数据为Excel文件
最后,我们可以使用Python的pandas库将提取出的表格数据保存为Excel文件。
首先,我们需要导入pandas库:
import pandas as pd然后,我们可以使用pandas的DataFrame类来创建一个数据框,将提取出的表格数据填充到数据框中:
data = pd.DataFrame(table)接下来,我们可以使用to_excel方法将数据框保存为Excel文件:
data.to_excel('output.xlsx', index=False)5.完整代码示例
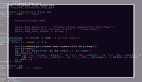
下面是一个完整的示例代码,演示了如何使用pdfplumber库提取PDF文档中的表格数据并保存为Excel文件:
import pdfplumber
import pandas as pd
# 打开PDF文档
with pdfplumber.open('example.pdf') as pdf:
pages = pdf.pages
# 提取表格数据
tables = []
for page in pages:
table = page.extract_table()
tables.append(table)
# 保存为Excel文件
data = pd.DataFrame(table)
data.to_excel('output.xlsx', index=False)6. 总结
本文介绍了如何使用Python的pdfplumber库来提取PDF文档中的表格数据,并将提取出的数据保存为Excel文件。
通过使用pdfplumber库,我们可以轻松地从PDF文档中提取表格数据,并进行进一步的分析和处理。
希望本文能够帮助读者更好地利用Python来处理PDF文档中的表格数据。