译者 | 李睿
审校 | 重楼
车联网(IoV)是汽车行业与物联网相结合的产物。预计车联网数据规模将越来越大,尤其是当电动汽车成为汽车市场新的增长引擎。问题是:用户的数据平台准备好了吗?本文展示了车联网的OLAP解决方案。

车联网的数据有什么特别之处?
车联网的理念很直观:创建一个网络,让车辆之间或与城市交通基础设施共享信息。通常没有充分解释的是每辆车的内部网络。车联网连接的每辆汽车都有一个控制器区域网络(CAN),作为电子控制系统的通信中心。对于每辆行驶在道路上的汽车来说,CAN是其安全性和功能性的保证,因为它负责:
- 车辆系统监测:CAN是车辆系统的中枢神经。例如,传感器将检测到的温度、压力或位置发送到CAN;控制器通过CAN向执行器发出命令(例如调整阀门或驱动电机)。
- 实时反馈:传感器通过CAN将车速、转向角度、刹车状态等信息发送给控制器,控制器及时对车辆进行调整,以确保车辆安全。
- 数据共享和协调:CAN允许各种设备之间的数据交换(例如状态和命令),因此整个系统可以更加高性能和高效。
- 网络管理和故障排除:CAN监视系统中的设备和组件。它可以识别、配置和监视设备,以便进行维护和故障排除。
由于CAN如此繁忙,可以想象每天通过CAN传输的数据大小。本文讨论的是一家汽车制造商将400万辆汽车通过CAN连接在一起,每天必须处理1000亿条CAN数据。
车联网的数据处理
将这些庞大的数据转化为指导产品开发、生产和销售的具有价值的信息是有趣的部分。与大多数数据分析工作负载一样,这归结为数据写入和计算,这也是存在挑战的地方:
- 大规模数据写入:传感器无处不在:车门、座椅、刹车灯……此外,许多传感器收集的信号不止一个。这400万辆汽车加起来的数据吞吐量达到数百万TPS,这意味着每天要处理几十TB字节的数据。随着汽车销量的增长,这一数字仍在增长。
- 实时分析:这可能是“时间就是生命”的最佳体现。汽车制造商从他们的车辆上收集实时数据,以识别潜在的故障,并在任何损坏发生之前修复它们。
- 低成本的计算和存储:谈到庞大的数据规模,必然提到成本。而更低的成本使得大数据处理可持续发展。
从Apache Hive到Apache Doris:向实时分析的过渡
就像罗马不是一天建成的那样,实时数据处理平台也不是一天建成的。一家汽车制造商过去依赖于批处理分析引擎(Apache Hive)和一些流框架和引擎(Apache Flink、Apache Kafka)的组合来获得接近实时的数据分析性能。直到实时性成为一个问题,他们才意识到他们如此迫切地需要实时性。
近实时数据分析平台
下图是这家汽车制造商在过去的做法:
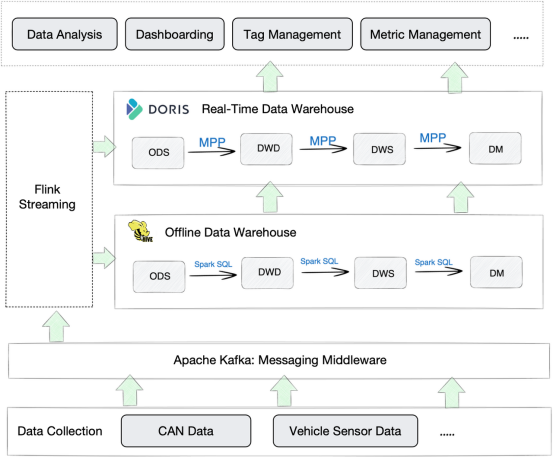
来自CAN和车辆传感器的数据通过4G网络上传到云网关,云网关将数据写入Kafka。然后,Flink处理这些数据并将其转发给Hive。通过Hive中的几个数据仓库层,将聚合的数据导出到MySQL。最后,Hive和MySQL为应用层提供数据,用于数据分析、Dashboard等。
因为Hive主要是为批处理而不是实时分析而设计的,所以可以在这个用例中看出它的不匹配。
- 数据写入:由于数据量如此之大,从Flink到Hive的数据摄取时间明显很长。此外,Hive只支持分区粒度的数据更新,这在某些情况下是不够的。
- 数据分析:基于Hive的分析解决方案提供了高查询延迟,这是一个多因素问题。首先,Hive在处理拥有10亿行的大型表时比预期的要慢。其次,在Hive内部,数据通过执行Spark SQL从一层提取到另一层,这可能需要一些时间。第三,由于Hive需要与MySQL合作来满足应用端的所有需求,Hive和MySQL之间的数据传输也增加了查询延迟。
实时数据分析平台
这就是当他们添加实时分析引擎时所发生的事情:
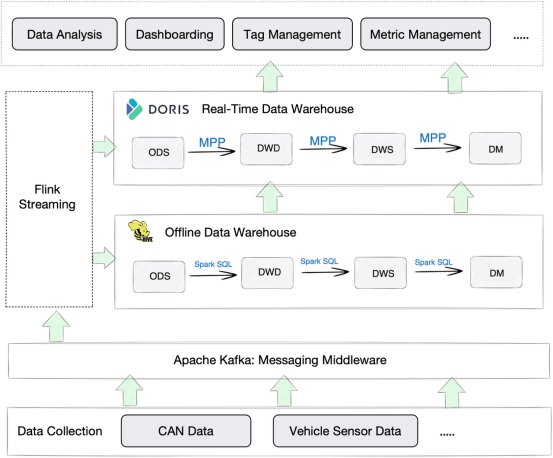
与原有的基于Hive的平台相比,这个新的平台在以下三个方面更高效:
- 数据写入:Apache Doris中的数据写入既快捷又简单,无需复杂的配置和引入额外的组件。它支持各种数据摄取方法。例如,在这种情况下,数据从Kafka通过Stream Load写入Doris,从Hive通过Broker Load写入Doris。
- 数据分析:通过示例展示Apache Doris的查询速度,在跨表连接查询中,它可以在几秒钟内返回1000万行的结果集。此外,它可以作为一个统一的查询网关,快速访问外部数据(Hive、MySQL、Iceberg等),因此分析师不必在多个组件之间切换。
- 计算和存储成本:Apache Doris提供的Z标准算法可以带来3~5倍的数据压缩率。这就是它如何帮助降低数据计算和存储成本的原因。此外,压缩可以单独在Doris中完成,因此它不会消耗Flink的资源。
一个良好的实时分析解决方案不仅强调数据处理速度,它还考虑到数据管道的所有方式,并使它的每一步都变得平滑。以下是两个示例:
(1)CAN数据的排列
在Kafka中,CAN数据是按照CAN ID的维度来排列的。然而,为了进行数据分析,分析人员必须比较来自不同车辆的信号,这意味着将不同CAN ID的数据连接到一个平面表中,并根据时间戳进行对齐。从这个平面表中,他们可以为不同的分析目的派生出不同的表。这种转换是使用Spark SQL实现的,这在原有的基于Hive的体系结构中非常耗时,而且SQL语句的维护成本很高。此外,数据是每天批量更新的,这意味着他们只能获得一天前的数据。
在Apache Doris中,他们所需要的只是用聚合密钥模型构建表,指定车辆识别号 (VIN)和时间戳作为聚合密钥,并通过REPLACE_IF_NOT_NULL定义其他数据字段。使用Doris,他们不必处理SQL语句或平面表,而是能够从实时数据中提取实时见解。

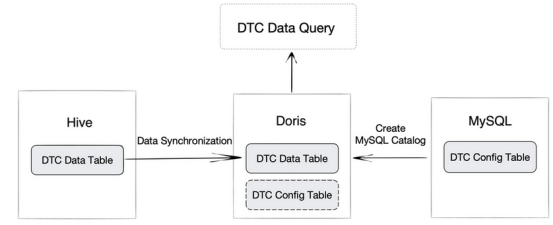
(2)DTC数据查询
在所有CAN数据中,故障诊断码(DTC)值得高度关注和单独存储,因为它可以告诉汽车出了什么问题。每天,制造商收到大约10亿个DTC。为了从DTC获取拯救生命的信息,数据工程师需要将DTC数据与MySQL中的DTC配置表关联起来。
他们以前做的是每天将DTC数据写入Kafka,在Flink中进行处理,然后将结果存储在Hive中。这样,DTC数据和DTC配置表就存储在两个不同的组件中。这造成了一个困境:一个10亿行的DTC表很难写入MySQL,而从Hive进行查询的速度很慢。由于DTC配置表也在不断更新,工程师只能定期将其中的一个版本导入Hive。这意味着他们并不总是能够将DTC数据与最新的DTC配置联系起来。
如上所述,Apache Doris可以作为统一查询网关工作。它的多目录功能支持这一点。他们将他们的DTC数据从Hive导入到Doris中,然后在Doris中创建一个MySQL目录来映射到MySQL中的DTC配置表。当所有这些都完成之后,他们可以简单地连接Doris中的两个表,并获得实时查询响应。
结论
这是一个实际的车联网实时分析解决方案。它是为大规模数据而设计的,现在正在为一家每天接收100亿行新数据的汽车制造商提供支持,以提高驾驶安全性和体验。
构建一个适合自己的用例的数据平台并不容易,希望本文能够帮助用户构建自己的分析解决方案。
原文标题:How Big Data Is Saving Lives in Real Time: IoV Data Analytics Helps Prevent Accidents,作者:Zaki Lu