随着 ChatGPT、GPT-4 等大型语言模型(LLM)的出现,提示工程(Prompt Engineering)变得越来越重要。很多人将 prompt 视为 LLM 的咒语,其好坏直接影响模型输出的结果。
如何写好 prompt,已经成为 LLM 研究的一项必修课。
引领大模型发展潮流的 OpenAI,近日官方发布了一份提示工程指南,该指南分享了如何借助一些策略让 GPT-4 等 LLM 输出更好的结果。OpenAI 表示这些方法有时可以组合使用以获得更好的效果。

指南地址:https://platform.openai.com/docs/guides/prompt-engineering
六个策略,获得更好的结果
策略一:写清楚指令
首先用户要写清楚指令,因为模型无法读懂你的大脑在想什么。举例来说,如果你希望模型的输出不要太简单,那就把指令写成「要求专家级别的写作」;又比如你不喜欢现在的文本风格,就换个指令明确一下。模型猜测你想要什么的次数越少,你得到满意结果的可能性就越大。
只要你做到下面几点,问题不会太大:
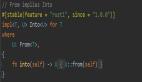
首先是提示中尽量包含更详细的查询信息,从而获得更相关的答案,就像下面所展示的,同样是总结会议记录,采用这样的提示「用一个段落总结会议记录。然后写下演讲者的 Markdown 列表以及每个要点。最后,列出发言人建议的后续步骤或行动项目(如果有)。」结果会比较好。

其次是用户可以提供示例。例如,当你想让模型模仿一种难以明确描述的回答风格时,用户可以提供少数示例。

第三点是指定模型完成任务时所需的步骤。对于有些任务,最好指定步骤如步骤 1、2,显式地写出这些步骤可以使模型更容易地遵循用户意愿。

第四点是指定模型输出的长度。用户可以要求模型生成给定目标长度的输出,目标输出长度可以根据单词、句子、段落等来指定。

第五点是使用分隔符来明确划分提示的不同部分。"""、XML 标签、小节标题等分隔符可以帮助划分要区别对待的文本部分。

第六点是让模型扮演不同的角色,以控制其生成的内容。

策略 2 提供参考文本
语言模型会时不时的产生幻觉,自己发明答案,为这些模型提供参考文本可以帮助减少错误输出。需要做到两点:
首先是指示模型使用参考文本回答问题。如果我们可以为模型提供与当前查询相关的可信信息,那么我们可以指示模型使用提供的信息来组成其答案。比如:使用由三重引号引起来的文本来回答问题。如果在文章中找不到答案,就写「我找不到答案」。

其次是指示模型从参考文本中引用答案。

策略 3:将复杂的任务拆分为更简单的子任务
正如软件工程中将复杂系统分解为一组模块化组件一样,提交给语言模型的任务也是如此。复杂的任务往往比简单的任务具有更高的错误率,此外,复杂的任务通常可以被重新定义为更简单任务的工作流程。包括三点:
- 使用意图分类来识别与用户查询最相关的指令;
- 对于需要很长对话的对话应用,总结或过滤以前的对话;
- 分段总结长文档并递归的构建完整摘要。
由于模型具有固定的上下文长度,因此要总结一个很长的文档(例如一本书),我们可以使用一系列查询来总结文档的每个部分。章节摘要可以连接起来并进行总结,生成摘要的摘要。这个过程可以递归地进行,直到总结整个文档。如果有必要使用前面部分的信息来理解后面的部分,那么另一个有用的技巧是在文本(如书)中任何给定点之前包含文本的运行摘要,同时在该点总结内容。OpenAI 在之前的研究中已经使用 GPT-3 的变体研究了这种过程的有效性。
策略 4:给模型时间去思考
对于人类来说,要求给出 17 X 28 的结果,你不会立马给出答案,但随着时间的推移仍然可以算出来。同样,如果模型立即回答而不是花时间找出答案,可能会犯更多的推理错误。在给出答案之前采用思维链可以帮助模型更可靠地推理出正确答案。需要做到三点:
首先是指示模型在急于得出结论之前找出自己的解决方案。
其次是使用 inner monologue 或一系列查询来隐藏模型的推理过程。前面的策略表明,模型有时在回答特定问题之前详细推理问题很重要。对于某些应用程序,模型用于得出最终答案的推理过程不适合与用户共享。例如,在辅导应用程序中,我们可能希望鼓励学生得出自己的答案,但模型关于学生解决方案的推理过程可能会向学生揭示答案。
inner monologue 是一种可以用来缓解这种情况的策略。inner monologue 的思路是指示模型将原本对用户隐藏的部分输出放入结构化格式中,以便于解析它们。然后,在向用户呈现输出之前,将解析输出并且仅使部分输出可见。
最后是询问模型在之前的过程中是否遗漏了任何内容。
策略 5:使用外部工具
通过向模型提供其他工具的输出来弥补模型的弱点。例如,文本检索系统(有时称为 RAG 或检索增强生成)可以告诉模型相关文档。OpenAI 的 Code Interpreter 可以帮助模型进行数学运算并运行代码。如果一项任务可以通过工具而不是语言模型更可靠或更有效地完成,或许可以考虑利用两者。
- 首先使用基于嵌入的搜索实现高效的知识检索;
- 调用外部 API;
- 赋予模型访问特定功能的权限。
策略 6:系统的测试变化
在某些情况下,对提示的修改会实现更好的性能,但会导致在一组更具代表性的示例上整体性能变差。因此,为了确保更改对最终性能产生积极影响,可能有必要定义一个全面的测试套件(也称为评估),例如使用系统消息。
更多内容,请参考原博客。