














业务上云过程中,势必会涉及到企业内部自建中间件等服务的迁移上云的需求,本文介绍下自建ES服务迁移上云的一些迁移方案以及如何根据业务场景选取适合的迁移方案
迁移方案
1、OSS快照
原理:以OSS为中转存储介质,使用elasticsearch-repository-oss插件关联两个集群,源集群备份数据,目标集群恢复数据(云厂商的托管ES集群默认都安装了oss插件),因为是快照模式,数据一致性得到保证,数据恢复速度也快
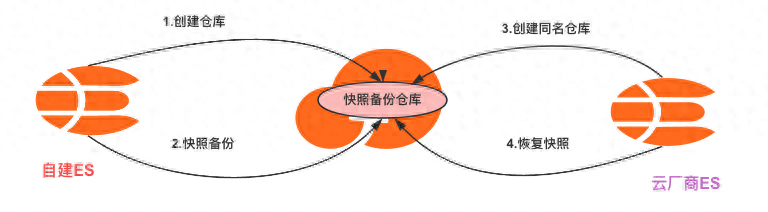
OSS迁移原理
迁移步骤拆解
源集群
- 创建OSS Bucket、设置ak、sk等信息
- 在自建集群安装安装elasticsearch-repository-oss插件,插件版本保证和集群版本一致
- 为需要迁移的索引创建快照,并将快照备份到已创建的仓库中
目标集群
- 使用snapshot API创建一个与自建Elasticsearch集群相同的快照备份仓库
- 将仓库中已备份的快照恢复到目标集群,完成数据迁移
- 快照恢复后,查看恢复的索引和索引数据
注意事项
- 这个方案的需要对原集群安装同步插件,插件有跨度过大版本兼容性问题,版本兼容性可以看插件说明文档
- 原集群备份是支持增量的,速度比较快;目标集群恢复是全量恢复,不支持增量,即目标集群每次恢复是先创建索引,在恢复数据(目标集群不能出现同名索引,否则恢复任务会失败)
- OSS备份的是主分区的数据,恢复过程也是主分区数据,副本分片的数据恢复是集群内部恢复逻辑。即:恢复任务完成时,是不包括副本数据恢复时间的。如果索引配置了写一致性,需要等副本也恢复完成才能写入成功
2、logstash
原理:logstash通俗的讲:就是一个管道,连接两端不同数据源。它的工作原理就是读取源端数据(input),经过处理(filter)发送到目标端(output),可以使用它的这个特性连接两个集群,迁移数据
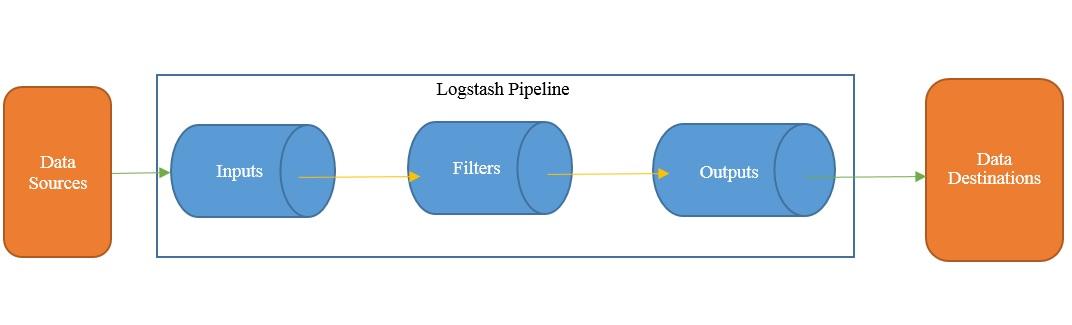
logstash工作原理
迁移步骤拆解
- 安装部署logstash
- 配置并运行logstash管道,核心配置如下
input {
elasticsearch {
hosts => ["http://<自建Elasticsearch Master节点的IP地址>:9200"]
user => "elastic"
index => "*,-.monitoring*,-.security*,-.kibana*"
password => "your_password"
docinfo => true
schedule => "*/30 * * * *" #每30分钟同步一次
}
}
filter {
}
output {
elasticsearch {
hosts => ["http:<云资源暴露的endpoint地址>//:9200"]
user => "elastic"
password => "your_password"
index => "%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"
}
}注意事项
logstash不能感知对索引的delete操作,即原集群中文档数据被删除了,目标集群不会跟着删除,update操作是支持同步的
对实时性要求不高的场景比较适用。
使用技巧:
- 确保源端数据的ID和目标端ID一致的增量同步需求的话,可以在logstash中配置schedule定时任务。
- index字段支持正则表达式和取反匹配,可以通过这个特性控制迁移的索引。
3、elasticsearch-dump
原理:这是一个索引迁移工具,比较轻量化,基本原理也是定义input和output,从原集群查询数据写入到目标集群,类型于logstash,但是不支持数据过滤功能
迁移步骤拆解
elasticdump --input 原集群es地址/索引 --output 目标集群es地址/索引
# type:指定迁移的类型,支持mapping、、analyzer、data
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=data注意事项
- 适合数据量不大,迁移索引个数不多的场景,如果目标集群索引不存在,需要迁移analyzer/mapping/data等索引属性信息和数据
- 不支持增量迁移,每次都需要停机迁移,而且同步效率不高,操作步骤繁琐
4、跨集群在线融合
原理:通过将自建集群和云上集群这两个本身独立的集群融合为一个大集群,并结合ES集群自带的分片分配、迁移特性 来完成数据的迁移工作
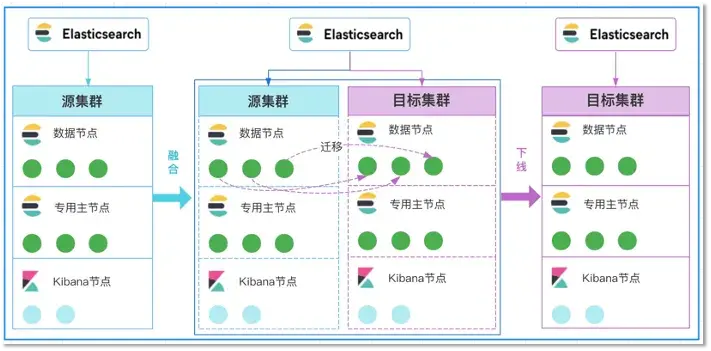
在线融合迁移方案
迁移步骤拆解
- 融合:首先我们需要在腾讯云ES控制台上申请一套和自建ES集群同等规模的空集群,即上图2中的目标集群,然后将云上的集群全量重启后加入到自建的ES集群中,使得两个集群融合成一个大集群。
- 迁移:融合完成后,通过对ES集群cluster/settings设置exclude属性来进行分片的迁移,当执行了如下API后,ES集群就会自动将自建集群节点上的分片逐步驱逐到云上的节点上来。从而完成分片的搬迁和集群数据的迁移工作。
- 下线:当自建集群节点上的分片都已经全部迁移完成后,再将自建集群节点全部停机下线,这样便完成了整个集群的迁移上云过程。我们可以通过如下API来查看自建节点上的分片数是否为0。
注意事项
- 受云厂商是否支持限制(腾讯云支持、阿里云不支持)
- 自建ES集群版本不能大于目标集群版本。主要原因是云上低版本的集群节点无法加入高版本的自建集群中。另外对于版本号,最好是两个集群大版本号一致
- 自建ES集群的插件需要和云ES集群插件保持一致,因为融合到同一个集群,需保证插件兼容
- 自建ES集群不能开启security认证,带有认证会导致融合失败
5、reindex
原理:reindex是ES提供的一个api接口,可以把数据从一个集群迁移到另外一个集群,reindex的核心做跨索引、跨集群的数据迁移,比如我们的某个索引分片过大,我们就可以创建新索引,在使用reindex API迁移数据。
迁移步骤拆解
目标集群设置whilelist白名单。
reindex.remote.whitelist: ["10.0.xx.xx:9200","10.15.xx.xx:9200","10.15.xx.xx:9200","10.15.xx.xx:9200"]目标集群调用reindex api配置迁移任务。
POST _reindex
{
"source": {
"remote": {
"host": "http://x.x.x.1:9200"
},
"index": "test1"
},
"dest": {
"index": "test2"
}
}注意事项
- Reindex 不会尝试设置目标索引。 它不会复制源索引的设置。 您应该在运行 _reindex 操作之前设置目标索引,包括设置映射、分片计数、副本等。
- 源端数据量较小,且对迁移速度要求不高的场景。
6、跨集群复制CCR
原理:跨集群复制 (CCR) 功能支持将特定索引从一个 ElasticSearch 集群复制到一个或多个 ElasticSearch 集群。除了跨数据中心复制之外,CCR 还有许多其他用例,包括数据本地化,或者将数据从 Elasticsearch 集群复制到中央报告集群。
备注:6.7及以后的版本支持,CCR 是一项白金级功能(付费功能)。
迁移方案如何选?
在上面我们介绍了可用的跨集群迁移方案,还有两种方式也是经常被提及的,方案那么多,我们怎么去选取适合自己业务场景的迁移方案,是一个值得我们去思考的问题,我整理了一个表格供大家参考:
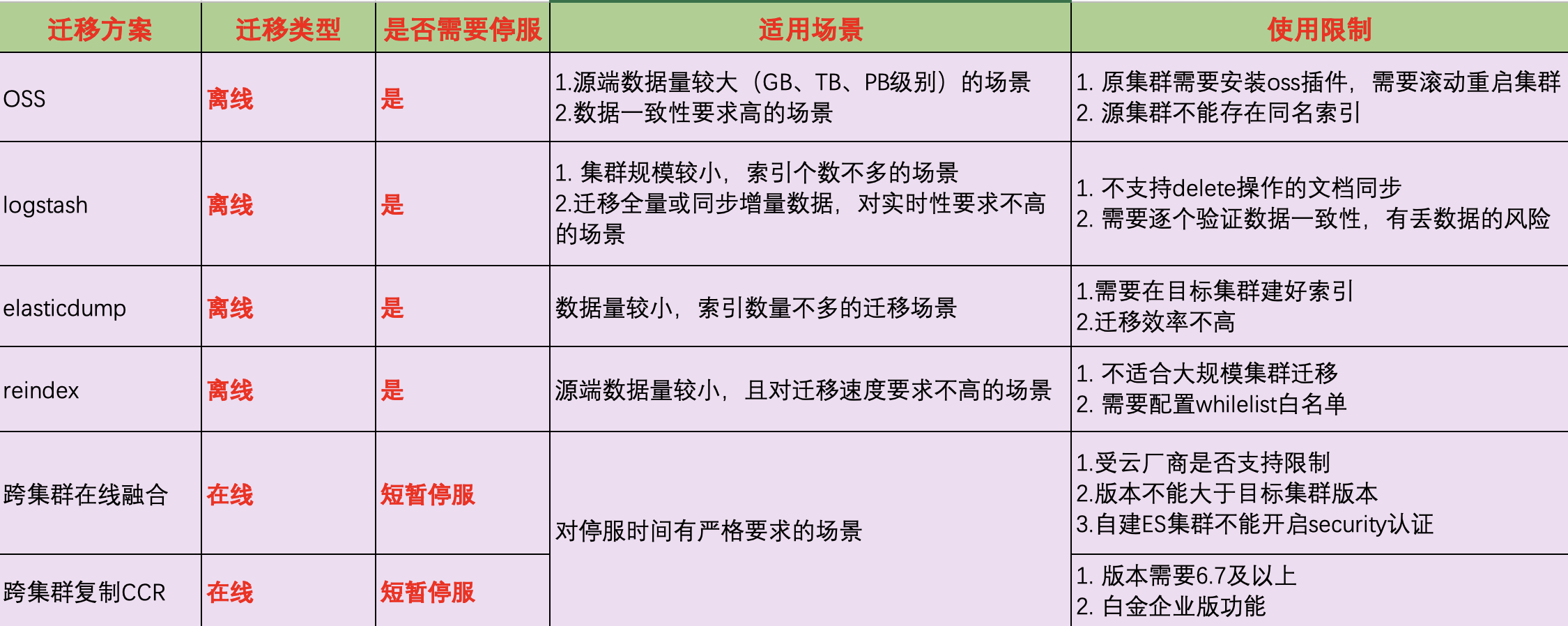
ES集群业界常用迁移方案














