












Hugging Face 技术负责人 Philipp Schmid 表示:“代码自动补全工具,如 GitHub Copilot,已被超过一百万开发者使用,帮助他们的编码速度提高了 55%。看到像 Magicoder 和 OSS-INSTRUCT 这样的开源创新超越了 OpenAI 的 GPT-3.5 和 Google DeepMind 的 Gemini Ultra,真是令人振奋。这些进步不仅展示了人工智能技术的快速发展,也突显了开源社区在推动这一领域创新中的重要角色。”
代码生成(也称为程序合成)一直是计算机科学领域的挑战性课题。在过去几十年,大量的研究致力于符号方法的研究。最近,基于代码训练的大型语言模型(LLM)在生成准确满足用户意图的代码方面取得了显著突破,并已被广泛应用于帮助现实世界的软件开发。
最初,闭源模型如 GPT-3.5 Turbo (即 ChatGPT) 和 GPT4 在各种代码生成基准和排行榜中占据主导地位。为了进一步推动开源 LLM 在代码生成领域的发展,SELF-INSTRUCT 被提出来引导 LLM 的指令遵循能力。在代码领域,从业者通常使用更强大的教师模型(如 ChatGPT 和 GPT-4)设计合成编码指令,然后用生成的数据微调更弱的学生模型(如 CODELLAMA)以从教师那里提炼知识。
我们以 Code Alpaca 为例,它包含了通过在 ChatGPT 上应用 SELF-INSTRUCT 生成的 20,000 个代码指令,使用了 21 个种子任务。为了进一步增强 LLM 的编码能力,Luo et al. 2023b 提出了 Code Evol-Instruct,该方法采用各种启发式方法来增加种子代码指令 (如 Code Alpaca) 的复杂性,在开源模型中取得了 SOTA 结果。
虽然这些数据生成方法能有效提高 LLM 的指令遵循能力,但它们在内部依赖于一系列狭义的预定义任务或启发式方法。比如采用 SELF-INSTRUCT 的 Code Alpaca 仅依赖于 21 个种子任务,使用相同的提示模板生成新的代码指令。而 Code Evol-Instruct 以 Code Alpaca 为种子,仅依赖于 5 个启发式方法来演化数据集。如 Yu et al.,2023 和 Wang et al., 2023a 论文中所提到的,这样的方法可能会明显继承 LLM 中固有的系统偏见以及预定义任务。
在本文中,来自伊利诺伊大学香槟分校(UIUC)的张令明老师团队提出了 OSS-INSTRUCT,用以减少 LLM 的固有偏见并释放它们通过直接从开源学习创造高质量和创造性代码指令的潜力。

- 论文地址:https://arxiv.org/pdf/2312.02120.pdf
- 项目地址:https://github.com/ise-uiuc/magicoder
- 试玩链接:https://huggingface.co/spaces/ise-uiuc/Magicoder-S-DS-6.7B (贪吃蛇 / 奥赛罗 /…)
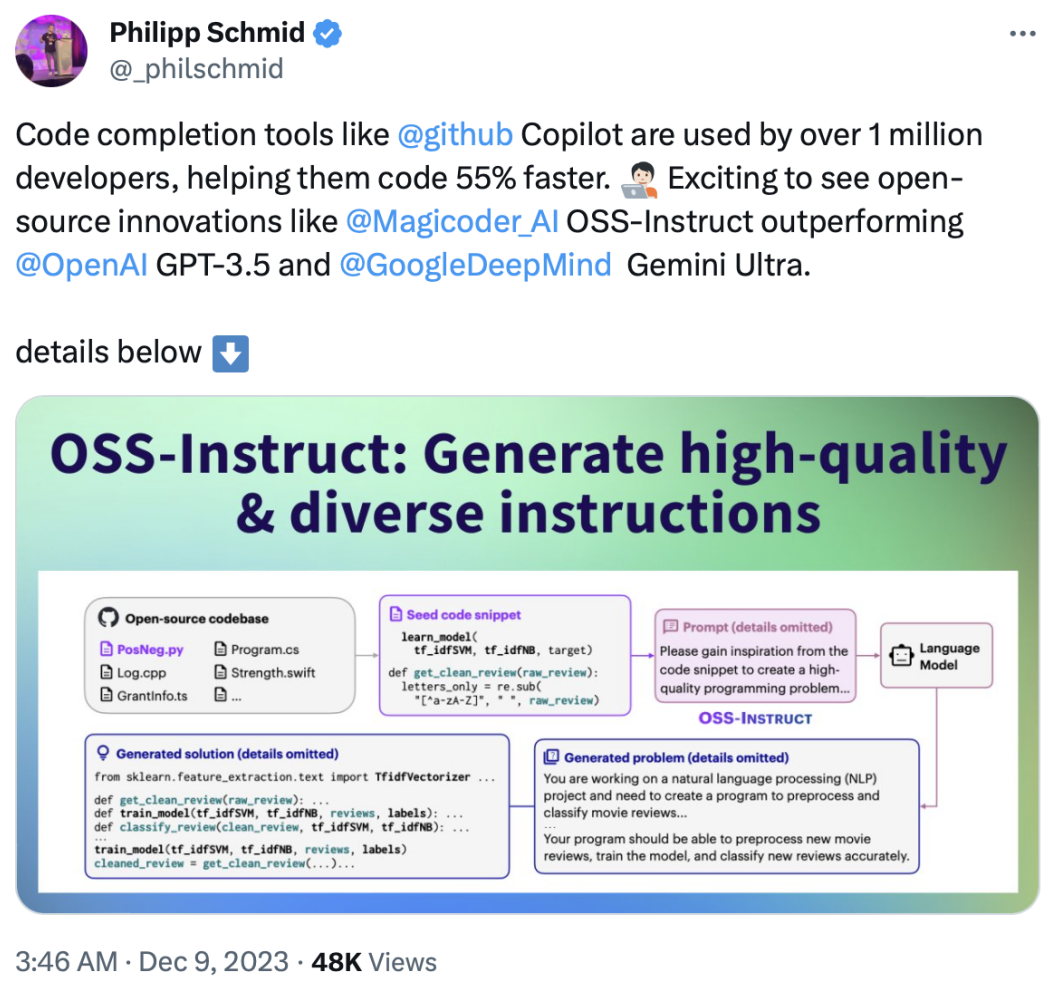
如下图 1 所示,OSS-INSTRUCT 利用强大的 LLM,通过从开源环境收集的任意随机代码片段中汲取灵感,自动生成新的编码问题。在这个例子中,LLM 受到来自不同函数的两个不完整代码片段的启发,成功地将它们关联起来并创造出了逼真的机器学习问题。
由于现实世界近乎无限的开源代码,OSS-INSTRUCT 可以通过提供不同的种子代码片段直接产生多样化、逼真且可控的代码指令。研究者最终生成了 75,000 条合成数据来微调 CODELLAMA-PYTHON-7B,得到 Magicoder-CL。OSS-INSTRUCT 虽然简单但有效,与现有的数据生成方法正交,并可以结合使用以进一步拓展模型编码能力的边界。因此,他们持续在一个包含 110,000 个条目的开源 Evol-Instruct 上微调 Magicoder-CL,产生了 MagicoderS-CL。

研究者在广泛的编程任务中对 Magicoder 和 MagicoderS 进行评估,包括 Python 文本到代码生成的 HumanEval 和 MBPP、多语言代码生成的 MultiPL-E,以及解决数据科学问题的 DS-1000。他们进一步采用了 EvalPlus,包括增强的 HumanEval+ 和 MBPP + 数据集,用于更严格的模型评估。据实验证实,在 EvalPlus 增强的测试下,ChatGPT 和 GPT-4 等代码大模型的实际准确率比在之前在 HumanEval 和 MBPP 等广泛使用数据集上的评估平均下降将近 15%。有趣的是,EvalPlus 同样也是张令明老师团队的近期工作,短短半年的时间已经被业界广泛采纳、并已经在 GitHub 上拥有 500 Star。更多模型在 EvalPlus 上的评估可以参考 EvalPlus 排行榜:https://evalplus.github.io/。
结果显示,Magicoder-CL 和 MagicoderS-CL 都显著提升基础的 CODELLAMA-PYTHON-7B。此外,Magicoder-CL 在所有测试基准上都超过了 WizardCoder-CL-7B、WizardCoder-SC-15B 和所有研究过的参数小于或等于 16B 的 SOTA LLM。增强后的 MagicoderS-CL 在 HumanEval 上的 pass@1 结果与 ChatGPT 持平(70.7 vs. 72.6),并在更严格的 HumanEval + 上超过了它(66.5 vs. 65.9),表明 MagicoderS-CL 能够生成更稳健的代码。MagicoderS-CL 还在相同规模的所有代码模型中取得了 SOTA 结果。
DeepSeek-Coder 系列模型在最近表现出卓越的编码性能。由于目前披露的技术细节有限,研究者在第 4.4 节中简要讨论它们。尽管如此,他们在 DeepSeek-Coder-Base 6.7B 上应用了 OSS-INSTRUCT,创建了 Magicoder-DS 和 MagicoderS-DS。
除了与之前以 CODELLAMA-PYTHON-7B 为基础模型的结果保持一致外,Magicoder-DS 和 MagicoderS-DS 还受益于更强大的 DeepSeek-Coder-Base-6.7B。这一优势由 MagicoderS-DS 展示,其在 HumanEval 上取得了显著的 76.8 pass@1。MagicoderS-DS 在 HumanEval、HumanEval+、MBPP 和 MBPP+ 上的表现同样优于 DeepSeek-Coder-Instruct 6.7B,尽管微调 token 减少为 1/8。
OSS-INSTRUCT: 基于开源进行指令调优
从高层次来看,如上图 1 所示,OSS-INSTRUCT 的工作方式是通过为一个 LLM(比如 ChatGPT)输入提示,从而根据从开源环境中收集到的一些种子代码片段(例如来自 GitHub)生成编码问题及其解决方案。种子片段提供了生成的可控性,并鼓励 LLM 创建能够反映真实编程场景的多样化编码问题。
生成代码问题
OSS-INSTRUCT 利用可以轻松从开源环境获取的种子代码片段。本文研究者直接采用 StarCoderData 作为种子语料库,这是用于 StarCoder 训练的 The Stack 数据集的过滤版本,包含以各种编程语言编写的许可证允许的源代码文档。选择 StarCoderData 的原因在于它被广泛采用,包含了大量高质量的代码片段,甚至经过了数据净化的后处理。
对于语料库中的每个代码文档,研究者随机提取 1–15 个连续行作为模型获得灵感并生成编码问题的种子片段。最终共从 80,000 个代码文档中收集 80,000 个初始种子片段,其中 40,000 个来自 Python,还有 40,000 个分别平均来自 C++、Java、TypeScript、Shell、C#、Rust、PHP 和 Swift。然后,每个收集到的种子代码片段都应用于下图 2 所示的提示模板,该模板由教师模型作为输入,并输出编码问题及其解决方案。

数据清理和净化
研究者在数据清理时,排除了共享相同种子代码片段的样本。虽然在生成的数据中存在其他类型的噪声(比如解决方案不完整),但受到了 Honovich et al. [2023] 的启发,这些噪声并未被移除,它们被认为仍然包含 LLM 可以学习的有价值信息。
最后,研究者采用与 StarCoder Li et al.,2023 相同的逻辑,通过删除包含 HumanEval 和 MBPP 中的文档字符串或解决方案、APPS 中的文档字符串、DS-1000 中的提示或 GSM8K 中问题的编码问题,对训练数据进行净化处理。事实上,净化过程仅过滤掉了额外的 9 个样本。由于种子语料库 StarCoderData 已经经过严格的数据净化,这一观察结果表明 OSS-INSTRUCT 不太可能引入除种子之外的额外数据泄漏。最终的 OSS-INSTRUCT 数据集包含约 75,000 个条目。
OSS-INSTRUCT 的定性示例
下图 3 的一些定性示例展示了:OSS-INSTRUCT 如何帮助 LLM 从种子代码片段获取灵感以创建新的编码问题和解决方案。例如,Shell 脚本示例显示了 LLM 如何利用一行 Shell 脚本创作一个 Python 编码问题。库导入示例演示了 LLM 如何使用几个导入语句创建一个现实的机器学习问题。
与此同时,类签名示例说明了 LLM 从具有 SpringBootApplication 等注释和 bank 等关键词的不完整类定义中获取灵感的能力。基于此,LLM 生成了一个要求基于 Spring Boot 实现完整银行系统的问题。
总体而言,OSS-INSTRUCT 可以激发 LLM 以不同的代码结构和语义来创建各种编码任务,包括算法挑战、现实问题、单函数代码生成、基于库的程序补全、整个程序开发,甚至整个应用程序构建。
 为了研究 OSS-INSTRUCT 生成的数据的类别,研究者使用了 INSTRUCTOR,这是 SOTA embedding 模型之一,可以根据任务指令生成不同的文本 embedding。受到了 OctoPack 和 GitHub 上主题标签的启发,研究者手动设计了 10 个与编码相关的特定类别。如下图 4 所示,他们计算了 OSS-INSTRUCT 中每个样本的 embedding 与这 10 个类别的 embedding 之间的余弦相似度,以获取类别分布。总体而言,OSS-INSTRUCT 在同类别之间表现出多样性和平衡。
为了研究 OSS-INSTRUCT 生成的数据的类别,研究者使用了 INSTRUCTOR,这是 SOTA embedding 模型之一,可以根据任务指令生成不同的文本 embedding。受到了 OctoPack 和 GitHub 上主题标签的启发,研究者手动设计了 10 个与编码相关的特定类别。如下图 4 所示,他们计算了 OSS-INSTRUCT 中每个样本的 embedding 与这 10 个类别的 embedding 之间的余弦相似度,以获取类别分布。总体而言,OSS-INSTRUCT 在同类别之间表现出多样性和平衡。

下图 5 中展示了生成的问题和解决方案的长度分布。横轴表示每个问题 / 解决方案中的 token 数量,纵轴表示相应的样本数量。

为了研究数据生成过程是否产生更多的类 HumanEval 问题或解决方案,研究者将 75,000 个数据集中的每个样本与 164 个 HumanEval 样本中的每个样本配对,并使用 TF-IDF embedding 计算它们的余弦相似度,然后将每个 OSS-INSTRUCT 样本与具有最高相似度分数的 HumanEval 样本关联。
研究者还分别将数据集与 Code Alpaca 和 evol-codealpaca-v1 进行比较 ,前者是一个在代码任务上应用 SELF-INSTRUCT 的 20K 数据集,后者是 Evol-Instruct 的一个包含 110K 编码指令的开源实现。由于官方的 Code Evol-Instruct 数据集尚未发布,研究者使用开源实现。他们还使用了与第 2.2 节中讨论的相同方式对所有数据集进行净化。
下图 6 结果显示,OSS-INSTRUCT 在所有研究的数据生成技术中表现出最低的平均相似性,而 SELF-INSTRUCT 显示出最高的平均相似性。这一发现表明,OSS-INSTRUCT 的改进并不仅仅是由于包含了来自相同分布的数据。

评估
Python 文本到代码生成
下表 1 展示了不同基准测试上,不同 LLM 在 pass@1 上的结果。从结果中首先可以观察到,Magicoder-CL 相较基础 CODELLAMA-PYTHON7B 有明显的改进,并且除了 CODELLAMA-PYTHON-34B 和 WizardCoder-CL-34B,在 HumanEval 和 HumanEval + 上优于所有其他研究过的开源模型。
值得注意的是,Magicoder-CL 超过了 WizardCoder-SC-15B,并且在 HumanEval 和 HumanEval+ 上相对于 CODELLAMA-PYTHON-34B 有了明显的提升。通过使用正交的 Evol-Instruct 方法进行训练,MagicoderS-CL 进一步实现改进。MagicoderS-CL 在 HumanEval + 上优于 ChatGPT 和所有其他开源模型。
此外,虽然在 HumanEval 上分数略低于 WizardCoder-CL-34B 和 ChatGPT,但在更严格的 HumanEval + 数据集上超过了它们,表明 MagicoderS-CL 可能生成更为稳健的代码。

多语言代码生成
除了 Python 外,研究者在下表 2 中对 Java、JavaScript、C++、PHP、Swift 和 Rust 等 6 种广泛使用的编程语言进行了全面评估,使用的基准测试是 MultiPL-E。

结果表明,在所有研究的编程语言中,Magicoder-CL 相对于基础的 CODELLAMA-PYTHON-7B 有着明显的改进。此外,Magicoder-CL 在半数以上的编程语言上也取得了比 SOTA 15B WizardCoder-SC 更好的结果。此外,MagicoderS-CL 在所有编程语言上进一步提高了性能,在只有 7B 参数的情况下实现了媲美 WizardCoder-CL-34B 的性能。
值得注意的是,Magicoder-CL 仅使用了非常有限的多语言数据,但仍然优于其他具有相似或更大规模的 LLM。此外,尽管评估框架以补全格式评估模型,但 Magicoders 仍然表现出明显的改进,尽管它们只进行了指令微调。这表明 LLM 可以从其格式之外的数据中学习知识。
用于数据科学的代码生成
DS-1000 数据集包含来自 Python 中 7 个流行数据科学库的 1,000 个不同的数据科学编码问题,并为验证每个问题提供单元测试。DS-1000 具有补全和插入两种模式,但在这里仅评估补全,因为基础 CODELLAMA-PYTHON 不支持插入。
下表 3 显示了评估结果,其中包括了最近的 INCODER、CodeGen、Code-Cushman-001、StarCoder、CODELLAMA-PYTHON 和 WizardCoder。
结果表明,Magicoder-CL-7B 优于评估的所有基线,包括最先进的 WizardCoder-CL-7B 和 WizardCoder-SC-15B。MagicoderS-CL-7B 通过在 WizardCoder-SC-15B 的基础上引入 8.3 个百分点的绝对改进,进一步突破了极限。

与 DeepSeek-Coder 的比较
DeepSeek-Coder 是最近发布的一系列模型,展示了卓越的编码性能。由于在撰写时其技术细节和指令数据尚未公开,因此这里简要讨论它。研究者在 DeepSeek-Coder-Base-6.7B 上采用了与在 CODELLAMA-PYTHON-7B 上执行的相同微调策略,得到了 Magicoder-DS 和 MagicoderS-DS。
下表 4 显示了与表 1 相似的趋势,即在应用 OSS-INSTRUCT 后,基础模型可以显著改进。值得注意的是,MagicoderS-DS 变体在所有基准上均超过 DeepSeek-Coder-Instruct-6.7B,而且训练 token 数量减少至 1/8,它还在这些数据集上与 DeepSeek-Coder-Instruct-33B 表现相当。

更多技术细节和实验结果请参阅原论文。
团队介绍
这篇论文的作者均来自伊利诺伊大学香槟分校(UIUC)张令明老师团队,包括:魏宇翔,二年级博士生,研究方向是基于 AI 大模型的代码生成;王者,科研实习生,目前为清华大学大四学生,研究方向是机器学习和自然语言处理;刘佳伟,三年级博士生,研究方向是编程系统和机器学习;丁一峰,二年级博士生,研究方向是基于 AI 大模型的自动软件调试。张令明老师现任 UIUC 计算机系副教授,主要从事软件工程、机器学习、代码大模型的相关研究,更多详细信息请见张老师的个人主页:https://lingming.cs.illinois.edu/。





























