真实世界模拟器来啦!
还在发愁训练出的大模型无法适应真实的物理世界吗?
AI Agent想要进入我们的生活还有多远的距离?
——UC伯克利、谷歌DeepMind、MIT和阿尔伯塔大学的研究人员告诉你答案。
在NeurlPS 2023上,研究人员将展示他们最新的工作:真实世界模拟器UniSim。

视频演示:https://universal-simulator.github.io/unisim/

论文地址:https://arxiv.org/pdf/2310.06114.pdf
当今的生成式大模型彻底改变了文本、图像和视频内容的创建方式。
那么,生成式AI的下一步会是什么呢?
也许是模拟现实体验,——以响应人类、机器人和其他交互式代理所采取的行动。
要达到这个目标,就需要用到真实世界模拟器。
真实世界模拟器有很多应用场景,比如游戏和电影中的可控内容创建,或者训练可以直接部署在现实世界中的具身代理。
长视距模拟
UniSim的真正价值在于模拟长事件,通过搜索、规划、最佳控制或强化学习来优化决策。下面的视频演示了UniSim如何模拟长视距的交互式体验。
使用UniSim进行强化学习(RL)
RL代理可以在UniSim提供的模拟世界中进行有效训练,之后可以直接转移到真实的机器人上,避免了在现实世界中搭建昂贵而复杂的训练环境。

经过上面在UniSim中的训练之后,可以零样本部署到真实机器人上:

使用UniSim进行长期规划
输入长期指令,使用UniSim推理和生成视频。然后,生成的视频和说明可用于训练视觉语言模型 (VLM) ,生成模拟计划,并零样本转移到真实机器人。

代表真实世界的模拟器,显然需要大量真实世界的数据。
研究人员发现,可用于学习的自然数据集通常包含很多维度,比如图像数据中的丰富对象,机器人数据中的密集采样动作,以及导航数据中的不同运动。
通过对各种数据集的精心编排,每个数据集都提供了整体体验的不同方面。
UniSim 可以通过模拟高级指令(如「打开抽屉」)和低级控件(如「按 x、y 移动」)的视觉结果,来模拟人类或代理与世界的交互方式。
UniSim可以用来训练高级视觉语言规划器,和低级强化学习策略,并且能够做到零样本(zero-shot)迁移到真实世界的应用中。
此外,其他类型的AI(如视频字幕模型)也可以从UniSim提供的模拟体验中获益。
从汽车在街上行驶,到家具的组装和饭菜的准备,通过全面的真实世界模拟器,人类可以与不同的场景和物体进行交互,
机器人可以从模拟经验中学习而不必担心物理损坏的风险,并且可以模拟大量真实世界数据来训练其他类型的机器智能。
不过,想要构建这样一个真实世界的模拟器,一个障碍就是可用的数据集。
虽然互联网上有数十亿个文本、图像和视频片段,但不同的数据集涵盖了不同的信息轴,必须将这些轴汇集在一起以模拟世界的真实体验。
例如,成对的文本图像数据包含丰富的场景和物体,但没有运动数据,
视频字幕和问答数据包含丰富的高级活动描述,但很少有低级运动细节,
人类活动数据包含丰富的人体动作,但没有机械运动信息,
机器人数据包含丰富的机器人动作,但数据集本身很有限。
由于不同的数据集是由不同的工业或研究社区,针对不同的任务策划的,所以信息的差异是自然的,很难克服。
本文的工作迈出了通过生成式建模,构建真实世界交互通用模拟器(UniSim)的第一步。
论文细节
研究人员将大量数据(互联网文本图像和导航、操作、人类活动、机器人技术以及模拟和渲染的数据)组合在一个有条件的视频生成框架中。

通过对不同维度的丰富数据进行精心编排,UniSim成功地合并了各种不同的体验信息,并在数据之外进行了泛化,通过对其他静态场景和对象的细粒度运动控制,来实现丰富的交互。
此外,UniSim融合了条件视频生成,与部分可观测马尔可夫决策过程(POMDP),可以跨视频生成边界,一致地模拟长视距交互。
交互式真实世界模拟器
对比一般的视频生成模型,交互式真实世界模拟器需要支持一组不同的操作和长期交互。
要训练这样的模拟器,首先需要从广泛的数据中提取信息。
这里的重点数据是对世界的视觉观察,以及导致这些视觉观察发生变化的行动。
将来自不同类型数据集的观察和行动提取并融合成一种通用格式,
然后用一个将视频和文本联系起来的通用接口,来融合不同数据集之间的信息。
模拟执行和渲染
虽然为真实世界的视频注释动作很昂贵,但模拟引擎能够渲染各种各样的动作,可以使用从模拟引擎收集的数据集来训练UniSim。
对于模拟的连续控制操作,通过语言嵌入对其进行编码,并将文本嵌入与离散化的控制值连接起来。
真实的机器人数据
真实机器人执行视频数据往往与任务描述配对,尽管机器人之间的低级控制操作通常不同,但任务描述可以作为UniSim中的高级操作。
人类活动视频
有很多纪录人类活动的数据集,如Ego4D、EPIC-KITCHENS和Something-Something,这些活动视频包含人类与世界互动的高级动作。
文中将视频标签转换为文本操作,并对视频进行子采样,以帧速率构建观察块,以捕获有意义的操作。
全景扫描
目前有大量的3D扫描(比如Matterport3D)数据。这些静态扫描不包含操作,但可以通过截断全景扫描来构建动作(比如左转),还可以利用两张图像之间相机姿势变化等信息。
互联网文本图像数据
成对的文本图像数据集(如LAION),包含丰富的静态对象,但没有动作。
不过,文本标签通常会包含运动信息,例如“一个人在走路”。此外,与上述其他数据集相比,互联网文本图像数据可以描述更丰富的对象集。
为了在UniSim中使用文本图像数据,这里将单个图像视为单帧视频,将文本标签视为操作。
有了从这些数据集中提取的观测和行动数据,就可以训练一个扩散模型来预测当前条件下的下一个观察帧。
根据扩散模型的原理,首先将包含时间信息的高斯噪声添加到先前观测值中,然后以输入动作为条件, UniSim学习将先前的噪声观测值降噪到下一个观测值。
由于来自不同环境的观察结果都已转换为视频,而不同模态的动作(文本描述、运动控制、相机角度等)都已转换为连续嵌入,因此UniSim可以利用所有的数据集学习单个世界模型。
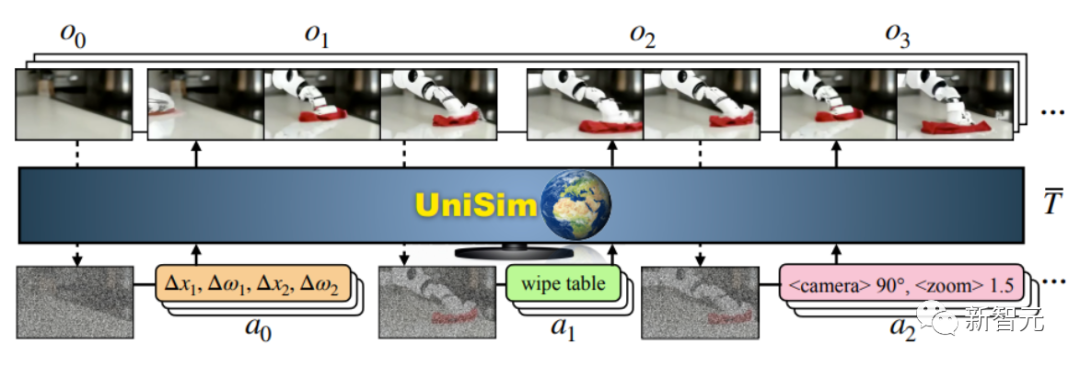
上图展示了UniSim的训练和推理。UniSim(T)是一个视频扩散模型,给定前一个观测(o)和动作输入(a)的噪声版本,UniSim可以预测下一个(可变长度的)观察帧(o)。
UniSim可以处理不同模态的动作,例如不同长度的电机控制指令、动作的语言描述,以及从相机运动和其他来源中提取的动作。
通过POMDP实现长期交互
结合不同的数据可以实现丰富的交互,但UniSim的真正价值在于模拟长期交互。
UniSim中的推理类似于在部分可观察的马尔可夫决策过程(POMDP)中执行部署,能够使用已建立的算法学习决策策略。
POMDP可以定义一个由状态、动作和观测空间以及奖励、转换和观测发射函数组成的元组。
POMDP可以表征与现实世界的交互,而UniSim作为过渡函数。

上图展示了UniSim对于各种动作的模拟,可以同一初始帧开始,根据指令推理出不同的发展。

上图展示了UniSim按顺序自回归模拟8次交互,长期交互中保持了时间一致性,正确地保留了对象和位置。
在初始帧中指示一个人执行各种厨房任务(左上角),按下不同的开关(右上角)或导航场景(底部)。
除了支持丰富的动作和长视距交互外,UniSim还可以支持高度多样化和随机的环境转换。
比如物体颜色和位置的多样性,以及现实世界的可变性,例如风和摄像机角度的变化。
可以使用语言动作来指定不同物体的外观,并利用视频生成的随机采样过程,来支持风和摄像机角度等环境随机性。
由于扩散模型在捕获多模态分布方面非常灵活,因此可以生成代表高度随机环境的各种样本。

上图显示了UniSim的多样化随机模拟。
UniSim的应用
下面展示使用UniSim通过模拟高度逼真的体验,来训练其他类型的机器智能。
视觉语言规划器
通过在UniSim中对每个轨迹进行3-5次部署,从UniSim创建总共10k个长期轨迹,其中每个部署对应于一个类似于原始数据集的脚本语言指令。
然后使用每个长期部署的最后一帧作为目标输入,并使用脚本语言指令作为训练VLM策略的监督。
下图显示了VLM生成的语言计划、UniSim根据语言计划生成的视频,以及在真实机器人上的执行。在UniSim中训练的策略可以以零样本的方式直接在现实世界中执行远距离任务。
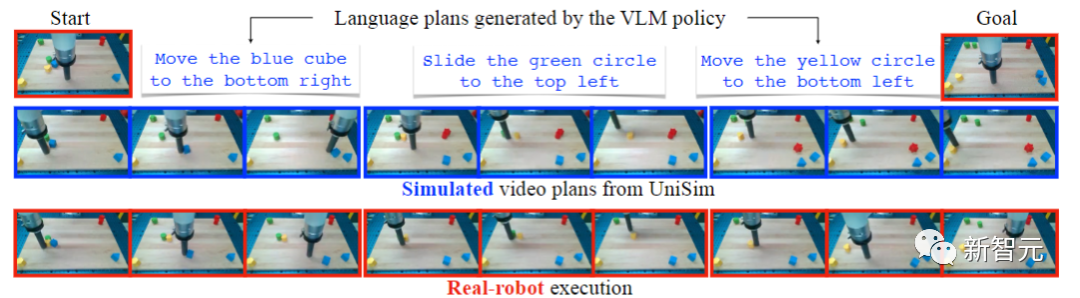
根据UniSim的数据进行训练的VLM,可以通过成功移动三个块(蓝色、绿色、黄色)来匹配它们在目标图像中的目标位置,从而规划长期任务。
强化学习策略
UniSim可以通过为智能体提供可以并行访问的逼真模拟器,来实现对RL智能体的有效训练。

在上图中,通过重复应用低级控制动作,来评估UniSim在模拟真实机器人执行中的质量,在20-30个步骤中向左、向右、向下、向上和对角线移动色块,RL策略可以成功完成「将蓝色立方体移动到绿色圆圈」的任务。