













撰稿 | 清竹
出品 | 51CTO技术栈(微信号:blog51cto)
2023年底,AI圈似乎已经被“文生视频”模型攻占了!
11月底 AI 文生视频工具 Pika 1.0 横空出世、风头一时无两,日前斯坦福大学 AI 科学家李飞飞团队联合谷歌推出AI 视频生成模型 W.A.L.T(Window Attention )继续炸圈,近日,腾讯团队带着新作品来炸场了!
1、吊打黑马AnimateDiff,实力碾压
AnimateZero 是腾讯AI团队发布的一款视频生成模型,它通过改进预训练的视频扩散模型(Video Diffusion Models),将视频生成当作一种零样本的图像动画问题,能够更精确地控制视频的外观和运动。
据介绍,该模型的效果秒杀 Animatediff,并且能够更好地兼容现有的SD生态。口说无凭,先来看看 AnimateZero 生成的视频效果如何?
AnimateZero 展示了在多个 T2I 模型上生成的个性化视频。
比如由动漫人物的图片生成的视频,人物动作流畅,还融入了眼睛变色、头发蓬蓬的小细节:

再看看自然景观的生成,沙滩上浪花的涌动、烟花的绚烂绽放、闪电袭来的氛围感,都有种身临其境的感觉。

AnimateZero 还演示了一种通过插入文本嵌入来控制视频的动态效果:由图像生成视频后,再增加如“快乐+微笑”、“愤怒而严肃”、“张开嘴”、“非常悲伤”等文本,视频人物就能呈现对应的情绪和动作。

除了在现有模型上生成个性化视频,AnimateZero 是如何“秒杀”AnimateDiff 的?
AnimateZero 方面表示, AnimateDiff (AD)的一种常见用途是协助 ControlNet (CN) 进行视频编辑,但它仍然存在域间隙问题。AnimateZero (AZ)在这方面具有明显的优势,即生成主观质量更高、与给定文本提示匹配度更高的视频。
AnimateZero 官方也给出了视频效果对比:根据原视频生成在熔岩中游泳的女孩,AnimateDiff 的视频画面比较模糊,熔岩的效果几乎看不出来,对比之下,AnimateZero 的视频无论是与文本的契合度还是画面的美感,明显优于AnimateDiff。

如果要将原视频中的黑色汽车变成红色呢?效果也显而易见:

再来看看要求将原视频变成在森林的草地上奔跑的小女孩,AnimateDiff生成的视频既没有呈现森林也没有看到草地,只是在背景墙和小女孩的头发上呈现一些绿色,这显然不符合要求;而AnimateZero的效果就好多了,和主题词完美契合。

2、AnimateZero 到底强在哪?
AnimateZero是一种基于视频扩散模型的零样本图像动画生成器。传统的视频扩散模型(VDM)存在以下几个问题:
- 黑匣子:生成过程不透明
- 低效且不可控:要获得满意的结果,需要大量的试错
- 域差距:受训练期间使用的视频数据集的域限制
AnimateZero 利用一种分步生成视频的方法,将外观和运动过程解耦,解决了传统文本到视频(T2V)扩散模型缺乏精确控制的问题。通过零样本修改,还能将T2V模型转换为I2V模型,使其成为零样本图像动画生成器。
- 解耦:视频生成过程解耦为外观(T2I)和运动过程(I2V)
- 高效可控:T2I 生成相比 T2V 更加可控、高效,在 I2V 生成视频之前可以获得满意的图像
- 缓解域差距问题:可以微调 T2I 模型的域以与实际域保持一致,这比调整整个视频模型更有效
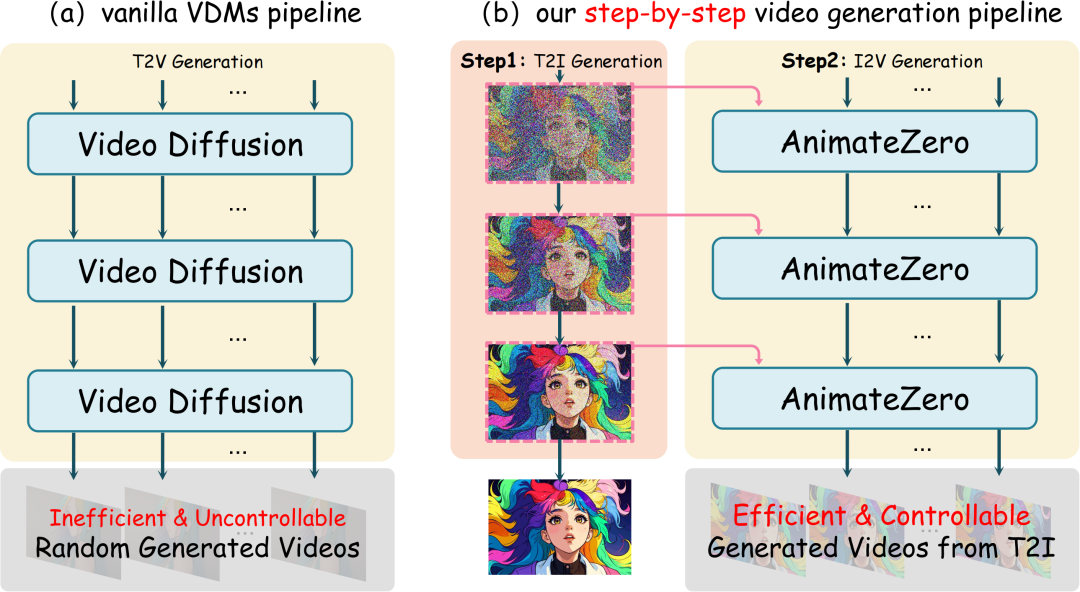
传统视频扩散模型(a) 和 AnimateZero 视频生成模型 (b) 的对比
除了本身的创新之外,相比AnimateDiff,AnimateZero 有哪些优势呢?
- 更高的一致性:在文本描述与生成视频之间,以及T2I(文本到图像)域与生成视频之间,AnimateZero展示了更高的一致性。
- 多样化应用:相比于AnimateDiff,AnimateZero支持更广泛的个性化图像域,并且能够在不同风格(如真实风格、动漫风格)中表现更好。
- 更强的动画效果:在动画质量和风格一致性方面,AnimateZero优于AnimateDiff,尤其在处理复杂运动和不常见对象时表现出更好的性能。
再完美的模型也会有它的局限性,AnimateZero的性能受限于其基础模型AnimateDiff的运动先验。对于一些复杂运动(如体育运动)或不常见对象的动画,AnimateZero的表现可能不尽如人意。另外由于AnimateZero是基于AnimateDiff的改进,因此其性能和应用范围受到基础模型的限制。
3、AI视频生成模型大爆发
1年以前,ChatGPT 以迅雷不及掩耳之势席卷全球,为文本创作领域带来重大的变革;一年后,文生视频赛道已成爆发态势,国内外的玩家都纷纷“开卷”。
先看国外的科技巨头:
11 月 3 日,Runway 宣布其 AI 视频生成工具 Gen-2 更新,一周后,Runway 又发布运动画笔功能,强化视频局部编辑能力;
11 月 16 日,科技巨头 Meta 推出了文生视频模型 Emu Video,首先生成以文本为条件的图像,然后生成以文本和生成的图像为条件的视频。
Stability AI 当然也毫不示弱。11 月 29 日,Stability AI 推出了名为 Stable Video Diffusion 的视频生成模型,提供 SVD 和 SVD-XT 两个模型。
更有最近火爆出圈的 AI 创企 Pika Labs 推出网页版 Pika 1.0,直接甩出体验链接引爆市场。
国内方面,11月12日,中国科学院等机构的研究者11 月 21 日提出了一个无需训练的文本生成视频框架 GPT4Motion;11 月 18 日,字节跳动推出了文生视频模型 PixelDance,提出了基于文本指导 + 首尾帧图片指导的视频生成方法,使得视频生成的动态性更强;12月1日,阿里的研究团队提出新框架 Animate Anyone,支持从静态图像 AI 生成动态视频;12月5日,美图公司发布的 AI 视觉大模型 MiracleVision 的 4.0 版本,主打设计和视频能力。
4、纷纷加码,“开卷”背后有何玄机?
那么,AI视频生成的技术和产品加速爆发,背后说明了什么?
从技术层面来看,文生图和文生视频的人工智能模型有较高相似性,文生图的技术和经验可供文生视频加以运用和参考是一个重要原因。
从市场情绪来看,近日95后女生以4人团队打造Pika Labs,快速出圈刷屏,成立半年就获得5500万美元融资,估值2亿美元。紧接着,也在A股上演了“父凭女贵”的戏码,其父亲所在的上市公司在这款工具爆火后连续收获3个涨停。可见文生视频领域的吸金能力空前巨大。
此外,国内头部企业的技术积累已经具备条件。湖南大学信息科学与工程学院博士生导师、教授张大方分析称,文生视频的人工智能模型参数为10亿级别至100亿级别,国内头部企业已能熟练掌握上述技术。在加快改进模型、清洗学习数据、调整操作界面、优化内部参数的共同推动下,文生视频技术已逐步克服诸多不足,并快速进入商业化应用。
同时,从应用角度方面来看,AI生成视频的前景毋庸置疑,影视、游戏以及广告等领域都是其落地的重要场景。艾媒咨询CEO兼首席分析师张毅表示:“个性化的视频制作更麻烦、成本更高,甚至超出了雇用程序员编程。不少行业都渴望有一款简单的视频生成工具。”
根据月狐iAPP统计的数据,从2022年Q2到今年6月,在移动互联网的所有类别的APP中,短视频的使用时长占比均高达30%以上,为所有类别中最高。这样的需求,也一定程度表明在视频制作领域蕴含着一个巨大增量的“蓄水池”。
客观来看,虽然各大厂商企业竞相加码,但相关应用的优化迭代速度和商业化进程都较慢,大公司与初创团队势均力敌,文生视频应用的潜力还没有彻底被开发。如何找到视频生成时长、效果、成本之间的平衡点,这依旧需要在各自不断的实践中寻求最优解。
参考链接:
https://vvictoryuki.github.io/animatezero.github.io/
https://www.chinaz.com/2023/1212/1582268.shtml
https://baijiahao.baidu.com/s?id=1785065486791669561&wfr=spider&for=pc




















