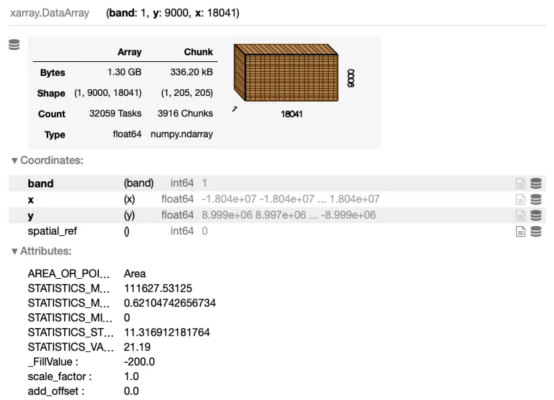
译者 | 朱先忠
审校 | 重楼
我经常看到网上流传着美丽的人口地图;然而,我也常常会遇到一些技术问题,比如可视化本文中显示的其他的地图片段,或者将大规模光栅数据转换为更便于计算的向量格式。在本文中,我将通过两个主要全球人口数据来源的实践来尝试克服这其中的一些问题。

另一方面,同样要注意,除了它们的美学价值外,显示它们的人口数据和地图是人们可以为任何城市发展或位置智能任务收集和整合的最基本和有价值的信息之一。它们在规划新设施、选址和集水区分析、估计城市产品规模或分析不同社区等实践应用中特别有用。
1.数据来源
在本文试验中,我将依赖以下两个细粒度的人口估计数据源,您可以通过所附链接来下载这些文件:
- 欧盟委员会的GHSL(全球人类住区层:https://ghsl.jrc.ec.europa.eu/ghs_pop2019.php)——用于测量每个网格单元的人口水平。从该数据源中可以找到整体描述以及我在他们2023年的报告中使用的空间分辨率为100米的特定集合。
- WorldPop中心。我将以德国为例,使用分辨率为100米的受限条件下的独立国家数据集。你可以在链接https://hub.worldpop.org/geodata/listing?id=78处查找到完整的国家列表数据,还可以在链接https://hub.worldpop.org/geodata/summary?id=49789处查找到德国数据。
2.可视化全球人类住区层
2.1.导入数据
我第一次看到这个数据集是在“体系结构性能”部分的Datashader教程处。在复制了他们的可视化结果之后,在将其扩展到全球地图时我遇到了一些麻烦,这些问题促使我开展了本文有关的研究工作。所以,接下来我将向您展示我是如何找到破解上述难题的解决方案的!
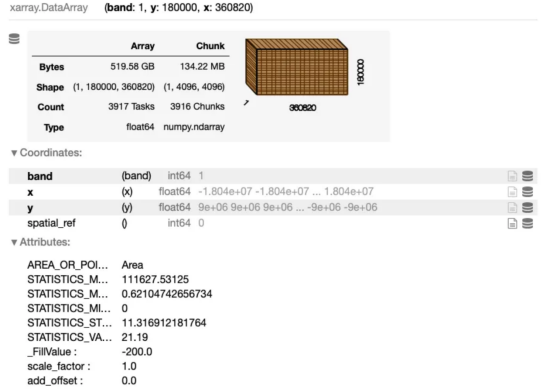
首先,我使用xarray包来解析光栅文件,代码如下:
此代码片断的输出结果是对数据集的一段详细描述:
2.2.可视化数据段
我们已经看到,对于大多数标准笔记本电脑来说,这是一个非常具有挑战性的数据量。无论如何,让我们试着使用Datashader来可视化数据,这是一个非常方便的工具,适用于这种规模的地理空间数据集的展示:
虽然这段代码在技术上看起来还可以,但我的2021款带有16GB RAM的M1 Macbook Pro出现了一个糟糕的内存溢出错误。因此,让我们裁剪一下图像以便查看数据!为此,我关注上述数据源的“体系结构性能”部分,并专注于欧洲数据,这是我暂时关注的内容,因为这样的选择确实有效。
然而,我稍后要回答的主要问题是,尽管内存有限,但我们如何在使用本地机器的情况下可视化整个地球的数据呢?请先等一等!
此代码块将输出以下的视觉效果:
 欧洲的人口分布图(作者本人提供的图片)
欧洲的人口分布图(作者本人提供的图片)
此绘制中,使用“火”色图似乎是一个行业标准,这是有充分理由的;然而,如果你想把事情搞混,你可以在链接https://colorcet.holoviz.org/处找到其他配色方案,并使用类似于下面的编程方式:
此代码块输出以下形式的视觉效果:
 欧洲的人口分布图另一种色图(作者本人提供的图片)
欧洲的人口分布图另一种色图(作者本人提供的图片)
2.3.可视化全球人口数据
到此,我们已经取得了全球人口数据,但如果你手边仅有一台普通的电脑,仍然想以100米的分辨率可视化整个世界,那该怎么办呢?我将在这里向您展示的解决方法非常简单——我将整个光栅图像分割成大约一百个较小的片断。这样一来,我的计算机就可以一个接一个地很好地处理它们,然后使用一些图像处理技巧将它们合并到一个图像文件中。
然而,在继续介绍之前,还有一个细节需要说明。我们可以通过以下方式对XArray数组降低采样率——然而,我找不到一个合适的降低尺度的方法来处理整个数据集。此外,我不想失去准确性,希望看到整个数据集的真实面貌。
最后的输出结果不错,不亚于之前绘制的data_array:
为了实现将整个光栅图像分割为网格段,首先,获取其边界并将N定义为步长。然后,创建图像片段边界列表。
现在,在每个x和y步骤上迭代,并创建每个图像片段,其中每个图像文件都以其在原始网格中的位置命名。此循环可能需要一段时间。
最后,如果我们拥有所有的图像片段,我们可以使用以下函数快速地把它们组合到一起。对于这段代码,我还要求ChatGPT提供一些提示来加快速度,但和往常一样,这个过程也需要一些手动调整。
最后的结果是,整个全球数据都被成功绘制出来了:
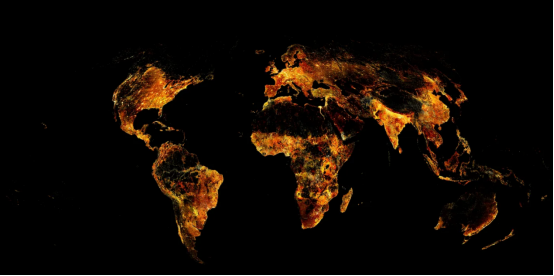 全球人口分布(作者本人的图片)
全球人口分布(作者本人的图片)
3.可视化和转换WorldPop数据
我想向大家展示的第二个数据来源是WorldPop人口数据库,它以不同的分辨率分别列出了各大洲和相应的国家。在这个例子中,为了补充前面绘制的所有大陆和全球级别的数据情况,我在这一部分中主要集中在各国家和相应城市级别数据上。例如,我选择了德国和2020年策划的100米的分辨率,并向您展示如何从整个国家中划出一个城市,并使用GeoPandas库将其转化为易于使用的向量格式。
3.1.可视化WorldPop数据
使用与前面相同的方法,我们可以再次快速可视化这一部分的光栅文件:
此代码片断将输出以下视觉效果:
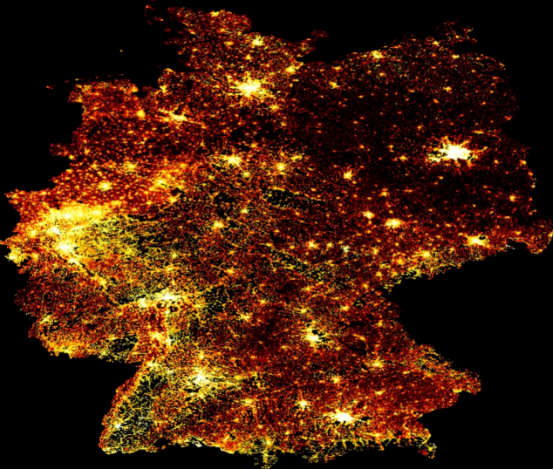 德国的人口分布图(作者本人的图片)
德国的人口分布图(作者本人的图片)
3.2.转换WorldPop数据
在可视化了整个地球、欧洲大陆和德国之后,我想更多地了解一下柏林市信息,并向您展示如何将这些光栅数据转换为向量格式,并使用GeoPandas轻松操作。为此,我在这里以geojson格式访问柏林的行政边界。
这个管理文件包含柏林的行政区,所以首先,我将它们合并为一个整体。
此代码块输出以下所示的视觉效果:
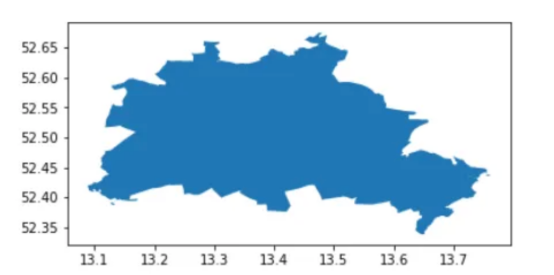 柏林的行政边界图(作者本人的图片)
柏林的行政边界图(作者本人的图片)
现在,将xarray转换为Pandas DataFrame,提取几何体信息,并构建GeoPandas GeoDataFrame。一种方法是:
现在,在此基础上构建一个GeoDataFrame,重点关注柏林信息:
然后,将人口可视化为向量数据:
此部分代码块输出以下视觉效果:
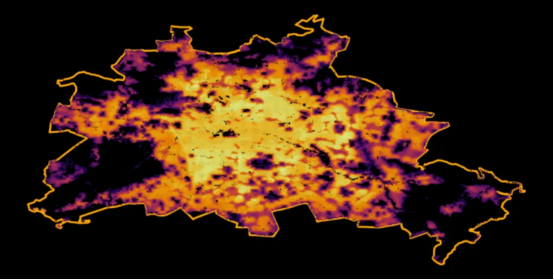 柏林的人口分布图(作者本人的图片)
柏林的人口分布图(作者本人的图片)
最后,我们得到了一个标准的GeoDataFrame,它具有100米分辨率的人口级别,分配给光栅文件中每个像素对应的每个点的几何体。
总结
在这篇文章中,我探索了两个全球人口数据集的可视化展示,它们通过结合各种近似、测量和建模方法,使用光栅网格以100米的显著空间分辨率实现估计人口水平。这类信息对城市发展和位置智能的广泛应用非常有价值,如基础设施规划、选址、社区概况等。从技术层面来看,我展示了三个空间层面的例子,涵盖了整个地球,然后放大到国家,最后是城市。虽然该方法可以处理更小的分辨率,但这一切都发生在一台笔记本电脑上已经令人非常满意。另外注意到,编程实现过程中我使用了几个强大的Python开源库,如Xarray、DataShader和GeoPandas。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Exploring Large-scale Raster Population Data,作者:Milan Janosov