













在Python编程中,序列化与反序列化是处理数据的重要概念。序列化是将数据转换为可存储或传输的格式,而反序列化则是将存储或传输的数据重新转换为程序内部的数据结构。Python提供了许多内置模块来执行这些任务,其中最常用的是JSON和Pickle模块。本文将深入探讨JSON和Pickle模块,详细介绍它们的用法、区别以及最佳实践,帮助更好地理解和应用序列化与反序列化的概念。
序列化与反序列化是Python中处理数据的关键概念。在介绍JSON和Pickle模块之前,让我们先了解一下什么是序列化与反序列化。
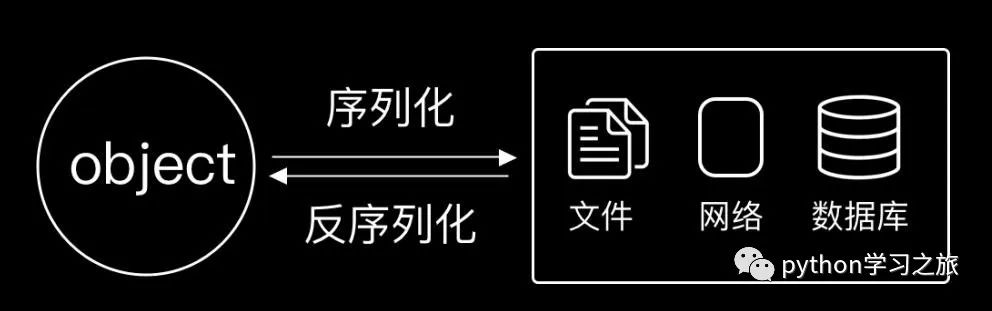
一、什么是序列化与反序列化?
序列化是将数据转换为可存储或传输的格式的过程。它将数据转换为字节流或文本字符串,以便在存储到文件或通过网络传输时使用。反序列化则是将序列化的数据重新转换为程序内部的数据结构。这两个过程对于数据的持久化和跨平台通信至关重要。
二、为何要序列化
为什么要序列化,方便数据传输,不同语言都遵循的一种数据转化格式,即不同语言都使用的特殊字符串。(比如Python的一个列表[1, 2, 3]利用json转化成特殊的字符串,然后再编码成bytes发送给php的开发者,php的开发者就可以解码成特殊的字符串,然后再反解成原数组(列表): [1, 2, 3])。每种语言都有自己的数据结构,为了方便数据传输,所以需要序列化,网络数据传输过程中最常用的数据结构是json。
序列化得到结果,也就是特定的格式的内容有两种用途:
- 可用于存储,用于存档
- 传输给其他平台使用,跨平台数据交互
三、json常用方法
当谈到 JSON(JavaScript Object Notation)模块时,通常是指 Python 中的 json 模块。这个模块提供了处理 JSON 数据的方法,包括加载(load)、加载字符串(loads)、转储(dump)和转储字符串(dumps)等操作。下面是关于这四个方法的详细示例代码:
1.load 方法
用于从文件中读取 JSON 数据,并将其解析为 Python 对象。
import json
# 从 JSON 文件中加载数据
with open('data.json', 'r') as file:
data = json.load(file)
# 打印加载的数据
print(data)2.loads 方法
用于将 JSON 字符串解析为 Python 对象。
import json
# JSON 字符串
json_str = '{"name": "John", "age": 30, "city": "New York"}'
# 将 JSON 字符串加载为 Python 对象
data = json.loads(json_str)
# 打印加载的数据
print(data)3.dump 方法
用于将 Python 对象转储到文件中,将 Python 对象序列化为 JSON 格式并写入文件。
import json
# Python 对象
data = {"name": "John", "age": 30, "city": "New York"}
# 将数据转储到 JSON 文件
with open('output.json', 'w') as file:
json.dump(data, file)4.dumps 方法
用于将 Python 对象转储为 JSON 字符串。
import json
# Python 对象
data = {"name": "John", "age": 30, "city": "New York"}
# 将数据转储为 JSON 字符串
json_str = json.dumps(data)
# 打印生成的 JSON 字符串
print(json_str)如何使用 load、loads、dump 和 dumps 四个方法。但你可以根据需要进行修改和扩展。这些方法在处理 JSON 数据时非常有用,可以轻松地在 Python 对象和 JSON 之间进行转换。
四、序列化与反序列化
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,也易于机器解析和生成。在Python中,可以使用json模块进行JSON格式的序列化和反序列化。如下图所示:

插入一张图片
1. 使用json模块
JSON序列化示例:
import json
data = {'name': 'Alice', 'age': 30, 'city': 'New York'}
# 将Python对象序列化为JSON格式的字符串
json_string = json.dumps(data)
print(json_string)JSON反序列化示例:
import json
json_string = '{"name": "Alice", "age": 30, "city": "New York"}'
# 将JSON格式的字符串反序列化为Python对象
python_obj = json.loads(json_string)
print(python_obj)2. 使用Pickle模块
Pickle模块是Python中用于序列化和反序列化数据的模块,与JSON不同,Pickle可以处理几乎所有Python数据类型。它的序列化形式不可读,但更适合于Python特定对象的持久化。
Pickle序列化示例:
import pickle
data = {'name': 'Bob', 'age': 25, 'city': 'San Francisco'}
# 将Python对象序列化为字节流
pickle_bytes = pickle.dumps(data)
print(pickle_bytes)Pickle反序列化示例:
import pickle
pickle_bytes = b'\x80\x04\x95\x17\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x03Bob\x94\x8c\x03age\x94K\x19\x8c\x04city\x94\x8c\x0fSan Francisco\x94u.'
# 将字节流反序列化为Python对象
python_obj = pickle.loads(pickle_bytes)
print(python_obj)总结
本文介绍了Python中序列化与反序列化的概念,并深入探讨了JSON和Pickle两个常用模块的用法。JSON适用于简单数据结构的序列化和反序列化,而Pickle则更适用于Python特定对象的处理。选择使用JSON还是Pickle取决于需求和数据类型。序列化和反序列化是数据处理中必不可少的技术,在实际应用中,选择合适的模块和方法可以更好地管理和处理数据。












