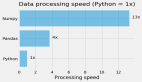
NVIDIA的RAPIDS cuDF是一个Python GPU DataFrame库,可用于加载、连接、聚合、过滤以及其他数据处理操作。cuDF基于libcudf这一非常高效的C++/CUDA dataframe库,以Apache Arrow的列式存储,并且提供了一个GPU加速的Pandas API,依赖于NVIDIA CUDA进行低级计算优化,从而可充分利用GPU并行性和高带宽内存速度。如下图所示。
同时,cuDF包含一个“零代码修改”的Pandas加速器(cudf.pandas),可在GPU上执行Pandas代码,支持类似于Pandas的API,并且可以在需要时自动切换到CPU上的pandas执行其它操作。
总而言之,cuDF比较好的一个使用场景就是「代替并行」,在Pandas处理比较慢的时候,切换到cuDF,就不用写繁琐的并行了。
如下所示是一段使用cuDF加速Pandas API进行数据处理操作的示例代码。
%load_ext cudf.pandas # 启用Pandas API的GPU加速功能
import pandas as pd
"""
在GPU上对列进行数学运算、分组计算以及滚动求和操作,利用GPU加速
"""
df = pd.read_csv("/path/to/file")
df["col_a"] = df["col_b"] * 100
df.groupby("col_a").mean()
df.rolling(window=3).sum()
"""
这是一个cuDF不支持的操作,会自动切换到CPU执行
"""
df.apply(set, axis=1)接下来,以Python 3.10和Nvidia T4 GPU运行整个代码为例说明cuDF的使用。
环境准备
- Cuda 11.2+
- Nvidia驱动程序 450.80.02+
- Pascal架构或更高版本(算力 >=6.0)
验证设置
首先,需要验证是否正在使用NVIDIA GPU。
!nvidia-smi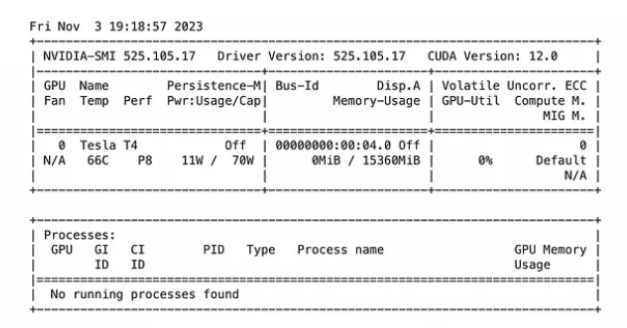
安装cuDF库
!pip install cudf-cu11 --extra-index-url=https://pypi.nvidia.com导入库
import cudf
cudf.__version__下载数据集
!wget https://data.rapids.ai/datasets/nyc_parking/nyc_parking_violations_2022.parquet使用标准的Pandas库进行数据分析
import pandas as pd
# 读取指定的5列数据
df = pd.read_parquet(
"nyc_parking_violations_2022.parquet",
columns=["Registration State", "Violation Description", "Vehicle Body Type", "Issue Date", "Summons Number"]
)
# 查看随机抽样的10行数据,并将结果显示出来
df.sample(10) 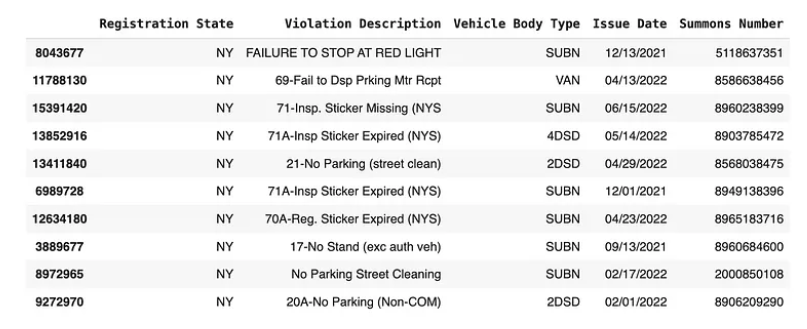
在代码块中添加执行时间计算。
%%time #用于计算下面的代码块的执行时间
# 读取指定的5列数据
df = pd.read_parquet(
"nyc_parking_violations_2022.parquet",
columns=["Registration State", "Violation Description", "Vehicle Body Type", "Issue Date", "Summons Number"]
)
"""
对"Registration State"和"Violation Description"这两列进行计数,
并按照"Registration State"分组,
选择每个分组中出现次数最多的"Violation Description",
最后,对结果进行排序并重置索引
"""
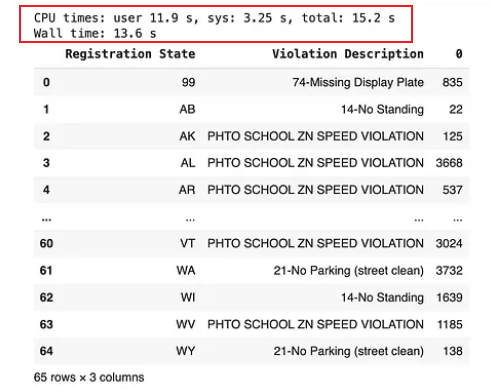
(df[["Registration State", "Violation Description"]]
.value_counts()
.groupby("Registration State")
.head(1)
.sort_index()
.reset_index()
)
%%time #计算下面的代码块的执行时间
"""
按照"Vehicle Body Type"进行分组,
并使用agg方法对"Summons Number"进行计数,
然后将计数结果重命名为"Count",
最后,按照计数结果降序排序。
"""
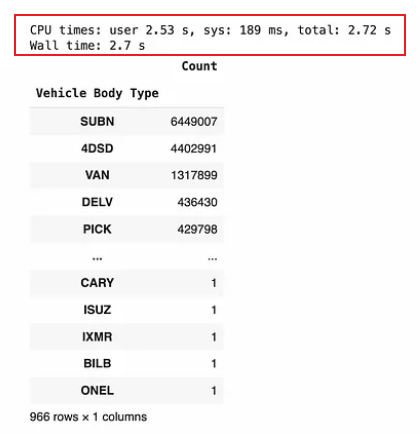
(df
.groupby(["Vehicle Body Type"])
.agg({"Summons Number": "count"})
.rename(columns={"Summons Number": "Count"})
.sort_values(["Count"], ascending=False)
)
使用cudf.pandas库进行数据分析
接下来,使用cudf.pandas扩展重新运行之前的Pandas代码。通常情况下,在Notebook中加载cudf.pandas扩展应该在导入模块之前进行。因此,为了模拟类似的操作,建议重新启动内核。
get_ipython().kernel.do_shutdown(restart=True)
%load_ext cudf.pandas
%%time
import pandas as pd
df = pd.read_parquet(
"nyc_parking_violations_2022.parquet",
columns=["Registration State", "Violation Description", "Vehicle Body Type", "Issue Date", "Summons Number"]
)
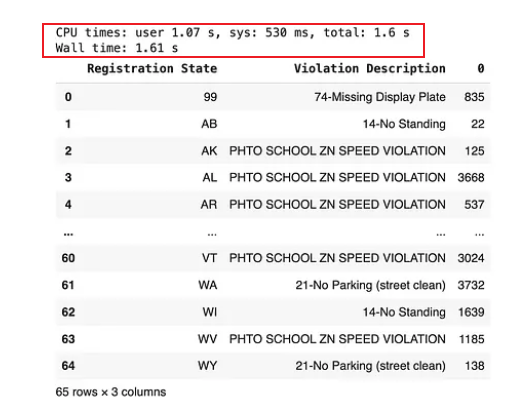
(df[["Registration State", "Violation Description"]]
.value_counts()
.groupby("Registration State")
.head(1)
.sort_index()
.reset_index()
)由代码块的执行时间可以看出,同样的操作,cudf.pandas的计算速度明显加快!
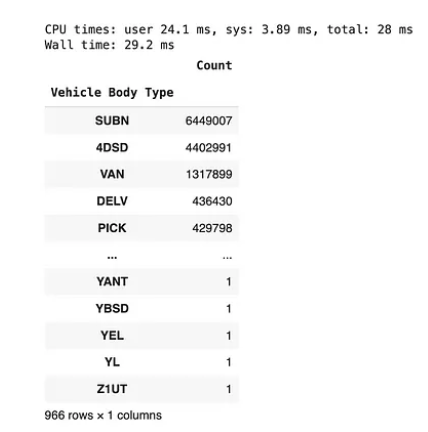
%%time
(df
.groupby(["Vehicle Body Type"])
.agg({"Summons Number": "count"})
.rename(columns={"Summons Number": "Count"})
.sort_values(["Count"], ascending=False)
)
性能分析
性能分析是一种用于评估程序执行效率的方法,通过分析代码的执行时间、资源利用情况和性能瓶颈等方面,帮助开发人员理解和优化程序的性能表现。cudf.pandas也提供了性能分析工具,可以帮助我们确定哪些部分的代码在GPU上执行,哪些部分在CPU上执行,从而更好地利用GPU加速计算的优势。
「注意」:如果在Google Colab上运行,第一次运行性能分析工具可能需要10s以上,这是因为Colab的Debugger需要和用于性能分析的内置Python函数sys.settrace进行交互,再次运行单元格即可解决这个问题。
如下代码使用%%cudf.pandas.profile命令,将代码提交给cudf.pandas的性能分析工具,以便分析代码在GPU上的执行情况,并识别性能瓶颈和优化空间。
%%cudf.pandas.profile
#创建DataFrame small_df
small_df = pd.DataFrame({'a': [0, 1, 2], 'b': ["x", "y", "z"]})
#重复拼接
small_df = pd.concat([small_df, small_df])
axis = 0
#对small_df进行最小值计算,并在循环中改变计算的轴向
for i in range(0, 2):
small_df.min(axis=axis)
axis = 1
#对small_df按照"a"列进行分组,并统计"b"列的计数
counts = small_df.groupby("a").b.count()