













上个月,微软 CEO 纳德拉在 Ignite 大会上宣布自研小尺寸模型 Phi-2 将完全开源,在常识推理、语言理解和逻辑推理方面的性能显著改进。

今天,微软公布了 Phi-2 模型的更多细节以及全新的提示技术 promptbase。这个仅 27 亿参数的模型在大多数常识推理、语言理解、数学和编码任务上超越了 Llama2 7B、Llama2 13B、Mistral 7B,与 Llama2 70B 的差距也在缩小(甚至更好)。
同时,小尺寸的 Phi-2 可以在笔记本电脑、手机等移动设备上运行。纳德拉表示,微软非常高兴将一流的小语言模型(SLM)和 SOTA 提示技术向研发人员分享。

今年 6 月,微软在一篇题为《Textbooks Are All You Need》的论文中,用规模仅为 7B token 的「教科书质量」数据训练了一个 1.3B 参数的模型 ——phi-1。尽管在数据集和模型大小方面比竞品模型小几个数量级,但 phi-1 在 HumanEval 的 pass@1 上达到了 50.6% 的准确率,在 MBPP 上达到了 55.5%。phi-1 证明高质量的「小数据」能够让模型具备良好的性能。
随后的 9 月,微软又发表了论文《Textbooks Are All You Need II: phi-1.5 technical report》,对高质量「小数据」的潜力做了进一步研究。文中提出了 Phi-1.5,参数 13 亿,适用于 QA 问答、代码等场景。
如今 27 亿参数的 Phi-2,再次用「小身板」给出了卓越的推理和语言理解能力,展示了 130 亿参数以下基础语言模型中的 SOTA 性能。得益于在模型缩放和训练数据管理方面的创新, Phi-2 在复杂的基准测试中媲美甚至超越了 25 倍于自身尺寸的模型。
微软表示,Phi-2 将成为研究人员的理想模型,可以进行可解释性探索、安全性改进或各种任务的微调实验。微软已经在 Azure AI Studio 模型目录中提供了 Phi-2,以促进语言模型的研发。
Phi-2 关键亮点
语言模型规模增加到千亿参数,的确释放了很多新能力,并重新定义了自然语言处理的格局。但仍存在一个问题:是否可以通过训练策略选择(比如数据选择)在较小规模的模型上同样实现这些新能力?
微软给出的答案是 Phi 系列模型,通过训练小语言模型实现与大模型类似的性能。Phi-2 主要在以下两个方面打破了传统语言模型的缩放规则。
首先,训练数据的质量在模型性能中起着至关重要的作用。微软通过重点关注「教科书质量」数据将这一认知发挥到了极致,他们的训练数据中包含了专门创建的综合数据集,教给模型常识性知识和推理,比如科学、日常活动、心理等。此外通过精心挑选的 web 数据进一步扩充自己的训练语料库,其中这些 web 数据根据教育价值和内容质量进行过滤。
其次,微软使用创新技术进行扩展,从 13 亿参数的 Phi-1.5 开始,将知识逐渐嵌入到了 27 亿参数的 Phi-2 中。这种规模化知识迁移加速了训练收敛,并显著提升了 Phi-2 的基准测试分数。
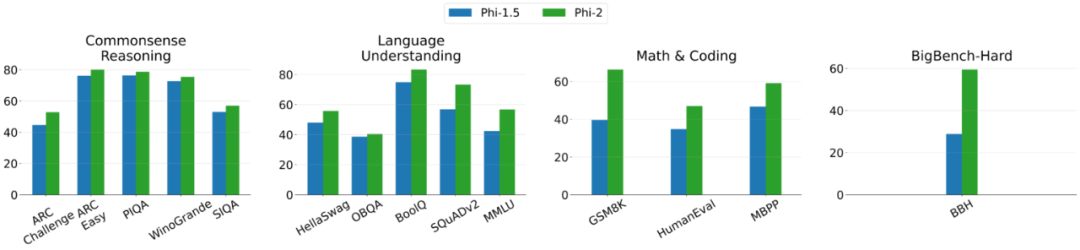
下图 2 为 Phi-2 与 Phi-1.5 之间的比较,除了 BBH(3-shot CoT)和 MMLU(5-shot)之外,所有其他任务都利用 0-shot 进行评估。
训练细节
Phi-2 是一个基于 Transformer 的模型,旨在预测下一个单词,在用于 NLP 与编码的合成数据集和 Web 数据集上进行训练,在 96 个 A100 GPU 上花费了 14 天。
Phi-2 是一个基础模型,没有通过人类反馈强化学习 (RLHF) 进行对齐,也没有进行指令微调。尽管如此,与经过调整的现有开源模型相比,Phi-2 在毒性和偏见方面仍然表现得更好,如下图 3 所示。

实验评估
首先,该研究在学术基准上对 Phi-2 与常见语言模型进行了实验比较,涵盖多个类别,包括:
- Big Bench Hard (BBH) (3 shot with CoT)
- 常识推理(PIQA、WinoGrande、ARC easy and challenge、SIQA)、
- 语言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、SQuADv2(2-shot)、BoolQ)
- 数学(GSM8k(8 shot))
- 编码(HumanEval、MBPP(3-shot))
Phi-2 仅有 27 亿个参数,却在各种聚合基准上性能超越了 7B 和 13B 的 Mistral 模型、Llama2 模型。值得一提的是,与大 25 倍的 Llama2-70B 模型相比,Phi-2 在多步骤推理任务(即编码和数学)方面实现了更好的性能。
此外,尽管模型较小,但 Phi-2 的性能可与最近谷歌发布的 Gemini Nano 2 相媲美。
由于许多公共基准可能会泄漏到训练数据中,研究团队认为测试语言模型性能的最佳方法是在具体用例上对其进行测试。因此,该研究使用多个微软内部专有数据集和任务对 Phi-2 进行了评估,并再次将其与 Mistral 和 Llama-2 进行比较,平均而言,Phi-2 优于 Mistral-7B,Mistral-7B 优于 Llama2 模型(7B、13B、70B)。


此外,研究团队还针对研究社区常用的 prompt 进行了广泛的测试。Phi-2 的表现与预期一致。例如,对于一个用于测试模型解决物理问题的能力的 prompt(最近用于评估 Gemini Ultra 模型),Phi-2 给出了以下结果:






























