1、避免使用多个 If-else 语句
我们在代码中使用条件语句进行决策。条件语句不应该被过度使用。如果我们使用太多条件 if-else 语句,则会影响性能,因为 JVM 每次都必须比较条件。
如果在 for 循环、while 循环等循环语句中使用相同的内容,情况可能会变得更糟。
如果业务逻辑中有太多条件,请尝试对条件进行分组并获取布尔结果并在 if 语句中使用它。
另外,如果可能的话,我们可以考虑使用 switch 语句来代替多个 if-else。Switch 语句比 if-else 具有性能优势。下面提供了示例作为示例,应避免如下情况:
例子:
if(条件1){
if(条件2){
if (条件3 || 条件4) { 执行..}
else{执行..}注意: 应避免使用上述示例,并按如下方式使用:
布尔结果 = (条件1 && 条件2) && (条件3 || 条件4)。
2、避免使用字符串对象进行连接
字符串是一个不可变类,由 String 创建的对象不能被重用。因此,如果我们需要创建一个大字符串,那么使用“+”运算符连接 String 对象是不好的做法。
这将导致创建多个 String 对象,从而导致更多的堆内存使用。
在这种情况下,我们可以使用 StringBuilder 或 StringBuffer,前者优于后者,因为它由于非同步方法而具有性能优势。
示例如下:
String str = str1+str2+str3;注意: 应避免使用上述示例,并按如下方式使用:
StringBuilder strBuilder = new StringBuilder(“”);
strBuilder.append(str1).append(str2).append(str3);
字符串查询 = strBuilder.toString();3、避免编写长方法
这些方法不应该太长,并且应该特定于执行单一功能。编写代码时使用单一职责原则。
这对于维护和性能都有好处,因为在类加载和方法调用期间,方法会加载到堆栈内存中。
如果方法很大且处理量过多,它们将消耗内存以及 CPU 周期来执行。
尝试在适当的逻辑点将这些方法分解为更小的方法。
我建议在 IDE 中使用Find Bug 或 Sonar Cube插件。它们基本上表明了方法的认知复杂性何时从阀值开始增加。
4、避免在循环中获取集合的大小
迭代任何集合时,都会在循环之前获取集合的大小,而不会在迭代期间获取它。下面提供了示例作为示例,应避免如下情况:
例子:
List<String> empListData = getEmpData ();
for ( int i = 0 ; i < empListData.size ( ); i++)
{
执行代码 ..
}注意:应避免使用上述示例,并按如下方式使用:
List<String> empListData= getEmpData();
int size = empListData.size();
for (int i = 0; i < 大小; i++) {
执行代码..
}5、避免使用BigInteger 和BigDecimal 类
BigDecimal 类为十进制值提供准确的精度。过度使用该对象会极大地影响性能,特别是当使用该对象来计算循环中的某些值时。
BigInteger 和 BigDecimal在 long 或 double 上使用大量内存来执行计算。
如果精度不是问题,或者如果我们确定计算值的范围不会超过 long 或 double,我们可以避免使用 BigDecimal,而应该使用 long 或 double 并进行适当的转换。
6、尽可能使用原始类型
使用原始数据类型比对象更好,因为原始类型数据存储在堆栈内存中,而对象存储在堆内存中。
如果可能,我们可以使用原始数据类型而不是对象,因为从堆栈内存访问数据比堆内存更快。
因此,使用 double 优于 Double 或使用 int 优于 Integer 总是有益的。
7、使用存储过程代替查询
最好编写存储过程而不是复杂而大的查询并在处理时调用它们。
存储过程作为对象存储在数据库中并进行预编译。与具有相同业务逻辑的查询相比,存储过程的执行时间更短,因为每次通过应用程序调用查询时都会编译和执行查询。
此外,存储过程在数据传输和网络流量方面具有优势,因为我们不需要每次都将复杂的查询传输到数据库服务器来执行。
8、避免经常创建大对象
有某些类在应用程序中充当数据持有者。这些对象很重,应避免多次创建它们。
例如用户登录后的数据库连接对象或会话对象。这些对象在创建时使用了大量资源。
我们应该重用这些对象,而不是创建它们,因为创建会由于更多的内存使用而极大地影响应用程序的性能。
我们应该尽可能使用单例模式来创建对象的单个实例,并在需要时重用它,或者克隆该对象而不是创建一个新对象。
9、在 Java 应用程序中谨慎使用“包含”
Lists、ArrayList 和Vectors都有一个 contains 方法,允许程序员检查集合是否已经有类似的对象。可能正在迭代一个大样本,并且经常需要在样本中查找唯一对象的列表。代码可能如下所示:
ArrayList al = new ArrayList();
for (int i=0; i < vars.size(); i++)
{
String obj = (String) vars.get(i);
if (!al.contains(obj))
{
al.add(obj);
}
}从功能上讲,这段代码很好,但从性能的角度来看,需要在循环的每次迭代中检查 ArrayList 是否包含该对象。contains 方法每次都会扫描整个 ArrayList。因此,随着 ArrayList 变大,性能损失也会增加。
最好先将所有样本添加到 ArrayList,进行一次重复检查,使用本质上提供唯一性的集合(例如 HashSet),然后创建唯一的 ArrayList 一次。现在不必对 ArrayList 进行数千次包含检查,而是进行一次性重复检查。
ArrayList al = new ArrayList();
…
for (int i=0; i < vars.size(); i++)
{
String obj = (String) vars.get(i);
al.add(obj);
}
al = removeDuplicates(al);
…
static ArrayList removeDuplicates(ArrayList list)
{
if (list == null || list.size() == 0)
{
return list;
}
Set set = new HashSet(list);
list.clear();
list.addAll(set);
return list;
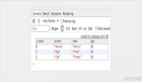
}下表显示了我们的原始代码和上面修改的代码之间的时间差:
比较 | 100 | 1000 | 10000 | 100000 |
原始代码 | 0ms | 5ms | 171ms | 49820ms |
修改代码 | 0ms | 1ms | 7ms | 28ms |
10、使用PreparedStatement代替Statement
在通过应用程序执行 SQL 查询时,我们使用 JDBC API 和类来实现同样的目的。
对于参数化查询执行来说, PreparedStatement比Statement更有优势,因为preparedStatement 对象编译一次并执行多次。
另一方面,Statement 对象在每次调用时都会被编译和执行。此外,准备好的语句对象是安全的,可以避免 SQL 注入攻击。
11、在查询中选择所需的列
在从数据库获取数据时,我们使用选择查询来获取数据。避免选择不需要进一步处理的列。
仅选择我们需要进一步处理或在前端显示的那些列。选择太多列会导致数据库端的查询执行延迟。
从数据库中选择数据时避免使用“*”。
此外,它还会增加从数据库到应用程序的网络流量,这是应该避免的。下面提供了示例作为示例,应避免如下情况:
例子:
select * from employee where emp_id = 100;注意:应避免使用上述示例,并按如下方式使用:
从员工中选择 emp_name、emp_age、emp_gender、emp_ocupation、emp_address,其中 emp_id = 100;
12、使用不必要的日志语句和不正确的日志级别
日志记录是任何应用程序不可或缺的一部分,需要有效实施,以避免由于不正确的日志记录和日志级别而导致性能下降。
我们应该避免将大对象记录到代码中。日志记录应限于特定参数。
此外,日志记录级别应保持在较高级别,例如 DEBUG、ERROR,而不是 INFO。下面提供了示例作为示例,应避免如下情况:
例子:
Logger.debug ( "员工信息:" + emp.toString ( ));
Logger.info ( "设置员工数据调用的方法:" + emp.getData ( ));注意:应避免使用上述示例,并按如下方式使用:
Logger.debug(“员工信息:” + emp.getName() + ”:登录ID:” + emp.getLoginId());
Logger.info(“设置员工数据所调用的方法”)。
13、使用join连接获取数据
从多个表获取数据时,有必要在表上正确使用join联接。如果未正确使用联接或表未标准化,则会导致查询执行延迟,从而导致应用程序性能下降。
避免使用子查询而不是连接,因为子查询比连接花费更多的执行时间。
在表中经常使用的列上创建索引,以提高查询执行的性能并减少应用程序的延迟。
在 join 或 where 子句中始终首先使用主键。
14、使用 EntrySet 而不是 KeySet
如果在地图上进行大量迭代,那么EntrySet会比KeySet更好。EntrySet 可以在一秒钟内比 KeySet 多运行 9000 次操作,因此将通过这种方式获得更好的性能。
15、EnumSet 是枚举值的最佳选择
如果正在使用 Enum 值,那么使用EnumSet更有意义。它允许比其他方法更快的计算。
EnumSet 的值以可预测的顺序存储,而其他方法(如 HashSet)需要更长的时间才能产生相同的结果。