在自然语言处理任务中取得显著成就的大型语言模型(LLMs)尽管表现出色,但在实时信息获取、外部工具利用和精确数学推理方面仍显不足。
为了应对这些挑战,来自UCLA等机构的研究人员打造了全新的Chameleon框架,其独特的即插即用模型融合了多种工具,包括LLMs、视觉模型、网络搜索引擎、Python功能及基于规则的模块。

项目链接:https://chameleon-llm.github.io/
论文链接:https://arxiv.org/abs/2304.09842
代码链接:https://github.com/lupantech/chameleon-llm
解读:https://www.youtube.com/watch?v=EWFixIk4vjs&ab_channel=WorldofAI
Chameleon的核心在于通过LLM规划器生成自然语言程序,从而找到最佳工具组合,并依次执行这些工具来得出结论。
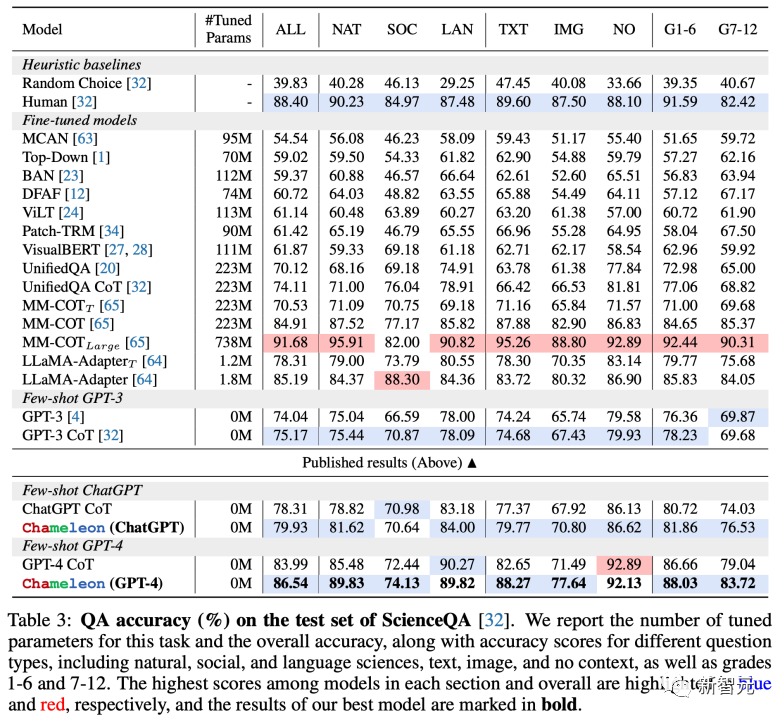
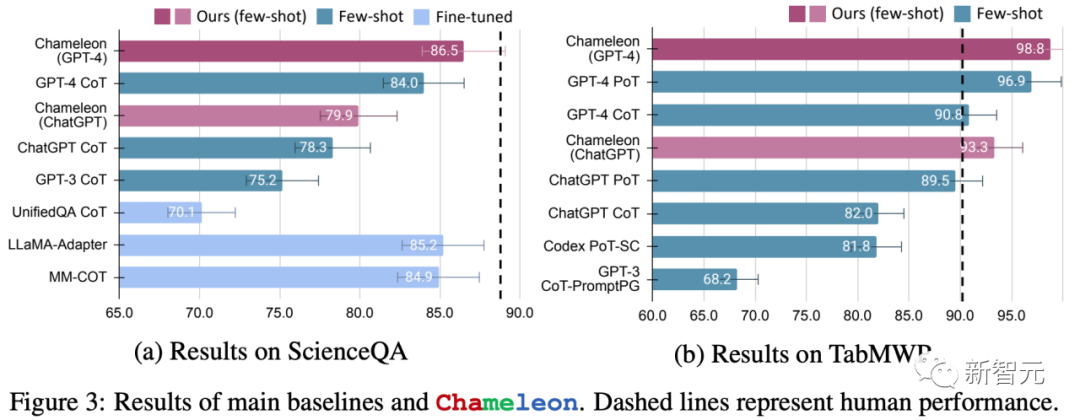
在科学问答任务ScienceQA和表格数学推理任务TabMWP上,Chameleon展示了其卓越性能,其中在ScienceQA中,模型以86.54%的准确率超越了现有的少样本模型,而在TabMWP中更是达到了惊人的98.78%准确率,远超现有模型。
Chameleon之名源于变色龙的适应和融合能力,象征着大型语言模型在执行外部工具组合推理任务时的多功能性和适应性。
自发布以来,Chameleon引起了广泛关注,GitHub项目收藏近1000次,学术界引用近100次。在1682篇AI论文中脱颖而出,被AlphaSignal评为「周最佳论文」。

此外,一位著名学术博主在YouTube上深入解析了Chameleon,视频播放量已超过1万次。

源自变色龙的灵感
在实际应用中,我们经常会面临各种类型和领域的不同工具,比如来自Hugging Face和GitHub的开源模型、像谷歌和必应这样的网络搜索服务、维基百科等知识库、生成式人工智能模型、Python函数、语言翻译和图像生成等等。
一个引人注目的问题是,如何将这些多样的工具与大型语言模型相结合,以解决复杂的任务。
答案就在于工具增强(Tool-Augmented)的大型语言模型或大型语言模型代理(LLM Agent)!
通过规划和整合多个工具和资源到大型语言模型框架中,我们可以创建一个更加多功能和强大的系统,以便处理各种领域的复杂任务。

因此,UCLA的研究人员提出了Chameleon-变色龙推理框架。Chameleon的灵感来自自然界中的变色龙,就像变色龙能够通过改变皮肤颜色来适应周围环境一样,Chameleon模型可以根据不同的输入问题,组合和使用各种不同的工具来完成相应的复杂推理。
例如,在解决多模态任务ScienceQA时,Chameleon模型会为不同的问题生成不同的程序,以灵活组合各种工具,并按照一定的顺序执行它们,从而最终得出答案。这种灵活性和适应性使Chameleon成为解决复杂任务的强大工具。
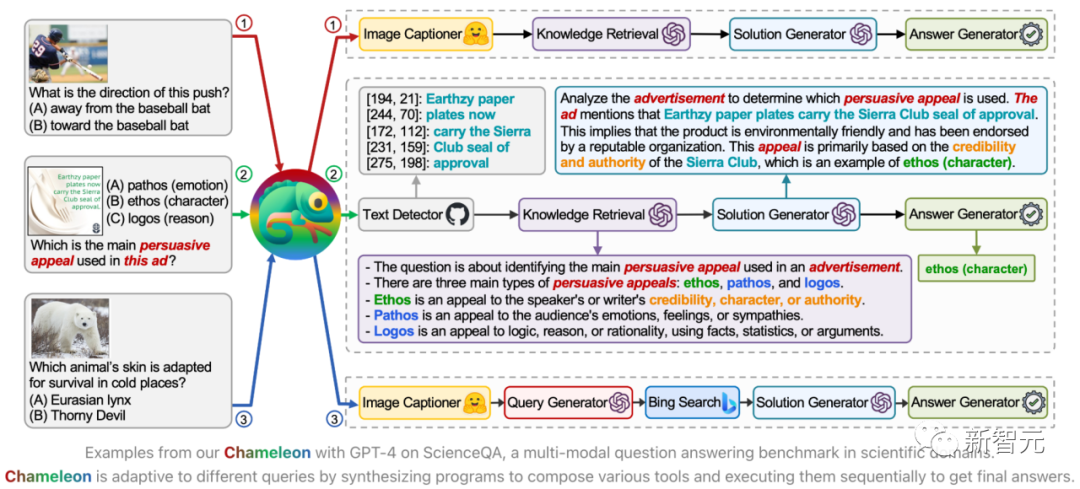
Chameleon模型与相关工作的比较
与相关工作相比,Chameleon模型在工具多样性和调用灵活性方面具有显著优势。首先,Chameleon支持LLM模型、视觉模型、网络搜索引擎、Python函数以及基于规则的模块,这些不同工具之间能够通过自然语言进行通信。
与此不同,已有的工作如Toolformer仅支持少量工具,如问答、计算器、机器翻译、WikiSearch和日历查询,而HuggingGPT仅适用于视觉处理相关的模型。
其次,Chameleon模型允许以类似自然语言的方式生成不同工具的调用组合,无需设计复杂格式的程序。而在已有的工作中,如ViperGPT,则需要生成精心设计、符合特定格式的Python代码,这对编程水平有限的用户来说并不友好。
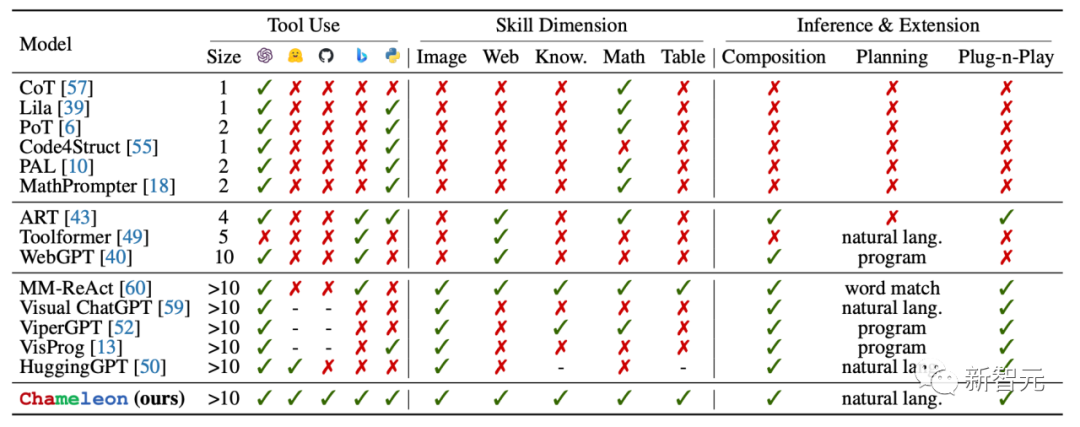
基于LLM的工具规划器
Chameleon模型与以往方法的不同之处在于其能够合成各种工具的组合,以适应不同类型的推理问题。
该模型由两个主要组成部分构成:工具箱(Module Inventory)和LLM规划器(LLM Planner)。工具箱包含了多种工具,使Chameleon模型具备了多样性和多维度的推理能力。
LLM规划器基于大型语言模型实现,可以根据不同的输入问题生成自然语言形式的程序,从而实现对工具箱中的工具进行组合和调用。
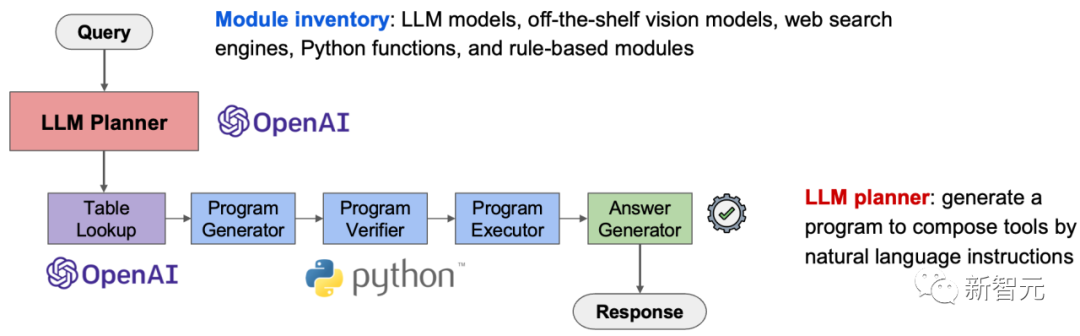
LLM规划器的实现非常简洁高效,充分利用了大型语言模型的提示学习(Prompt Learning)和语境学习(In-Context Learning)能力。LLM规划器的输入提示描述了需要生成不同工具组合序列的情境,同时定义了工具箱中的所有工具。

LLM规划器的提示还提供了一些语境示例,以指导大型语言模型如何根据输入信息生成正确的程序。

基于这些描述和示例,大型语言模型,如ChatGPT和GPT-4,能够学习如何针对新的输入问题生成适当的程序,以组合和调用工具箱中的不同工具,从而完成涉及复杂推理的输入问题。
Chameleon模型的一大优势在于为用户提供了丰富的灵活性,只需提供语言描述,就能让大型语言模型与外部工具协同工作,覆盖多种类型和技能维度。此外,它具有即插即用的特性,允许用户无缝更新底层大型语言模型、添加新工具,并适应新的任务。
Chameleon工具箱的多样技能
为满足多样的推理需求,Chameleon的工具箱中包含了各种不同技能的工具,包括图像理解、知识理解、数学推理、表格推理和问答。
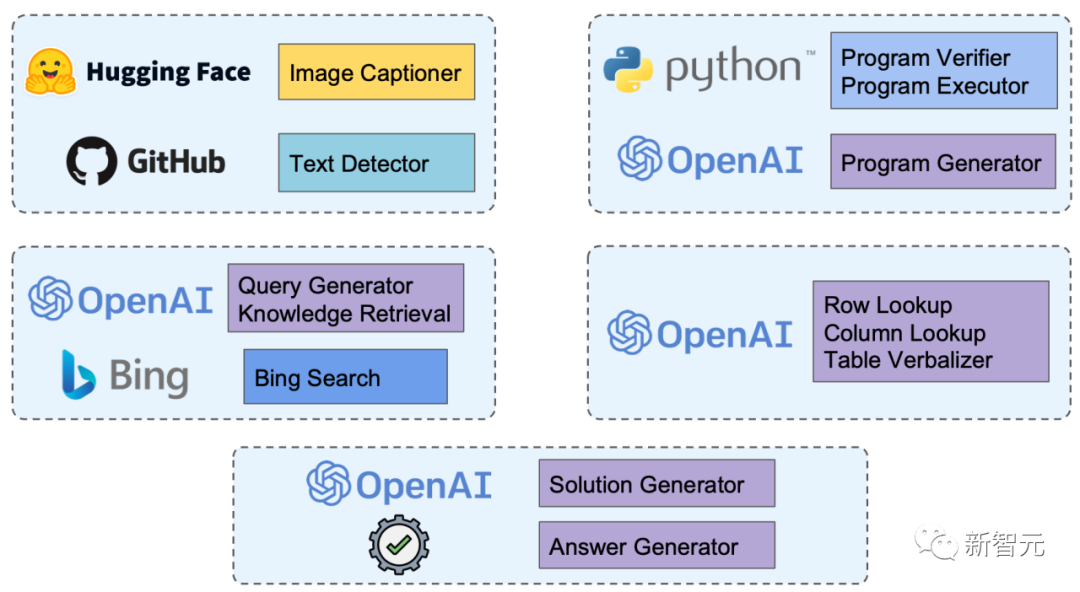
基于LLM的工具实现
需要强调的是,Chameleon的工具箱中包括了基于LLM(大型语言模型)的工具。
以「知识检索(Knowledge Retrieval)」工具为例。在帮助系统解决复杂问题时,检索额外的知识至关重要。
这个工具模块利用大型语言模型强大的生成能力来获取特定领域的知识。这在处理专业领域问题,如科学和数学时尤为有用。

举例来说,如果问题涉及理解税表,这个模块可以生成与税务相关的背景知识,这对后续的推理步骤至关重要。
最近的研究表明,程序辅助方法可以提高大型语言模型在逻辑和数学推理方面的能力。
因此,工具箱中还包括了「程序生成(Program Generator)」工具,它利用大型语言模型的语境学习和代码生成能力,结合输入问题,生成可以有效解决给定问题的Python程序。
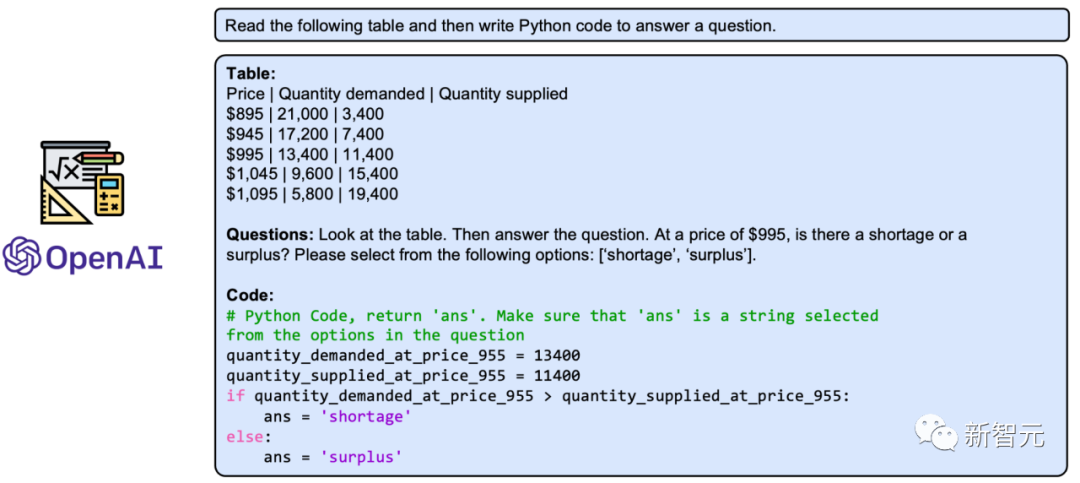
此外,还可以构建「解答生成(Solution Generator)」工具,它能指导大型语言模型充分利用输入问题、上下文信息和历史工具执行的中间结果,生成多步且详细的解答。
Chameleon模型的评测表现
Chameleon模型在两个复杂的多模态推理任务上进行了实验评估,分别是ScienceQA和TabMWP。
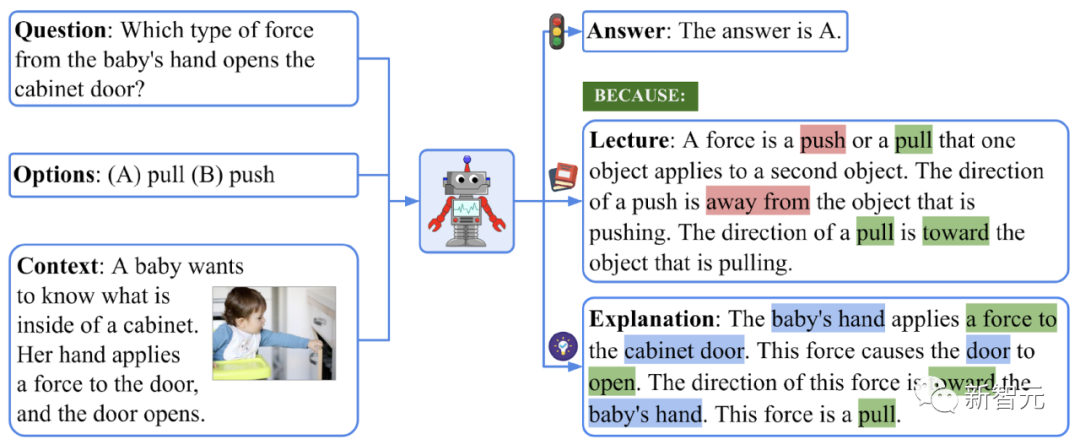
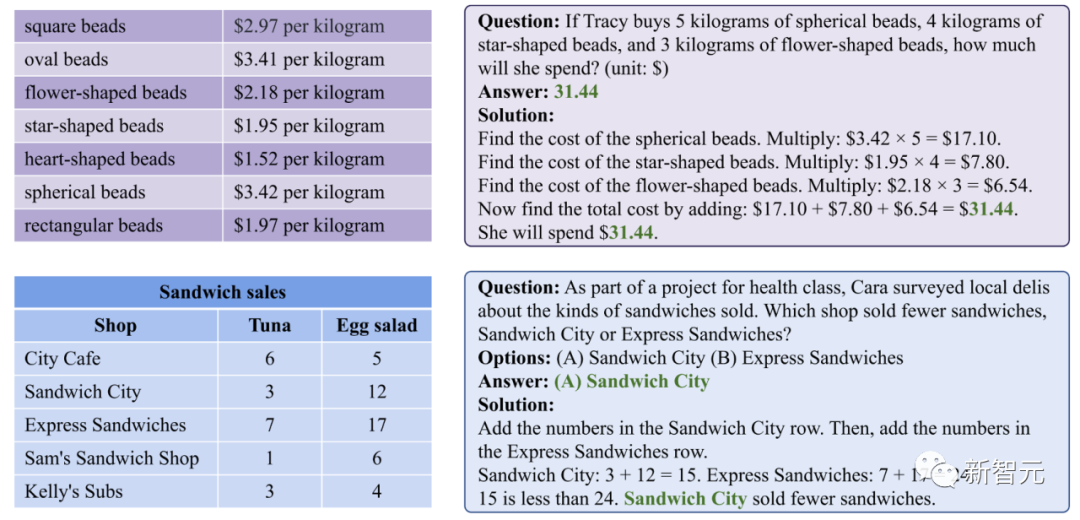
ScienceQA,即科学问答,是一个涵盖广泛科学主题的多模态问答基准测试。如下图的例子所示,回答ScienceQA中的问题需要使用各种知识、工具和技能,例如图像描述、文本检测、知识检索、在线资源搜索,以及视觉推理。这要求模型具备包括视觉和语言推理在内的组合能力。
Chameleon模型中的LLM规划器能够合成程序,以调用不同的工具组合来回答ScienceQA中不同类型的问题。
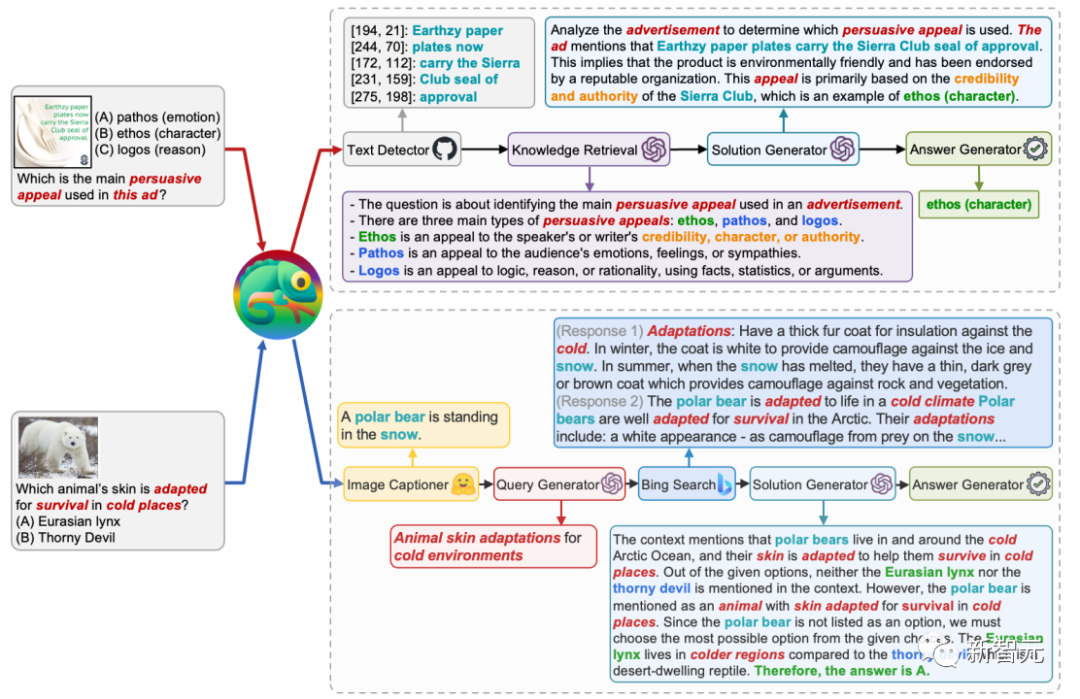
例如,在下图所示的第一个例子中,Chameleon模型识别到输入图像包含广告文本,因此调用了「文本检测(Text Detector)」工具来理解图像中的文字。
随后模型调用「知识检索(Knowledge Retrieval)」工具来检索问题所涉及到的术语「persuasive appeal」的相关背景知识。最后,模型根据输入问题和执行之前工具得到的中间结果得出最终的答案。
第二个问题涉及到识别图像中的动物并回答环境适应性的问题。
Chameleon模型调用了「图像描述(Image Captioner)」工具来理解图像中的动物,并通过调用「必应搜索(Bing Search)」来获取相关的学科背景知识,最终的答案充分利用了这些信息。
详细的评测结果也充分证明了Chameleon模型在ScienceQA任务上的有效性。
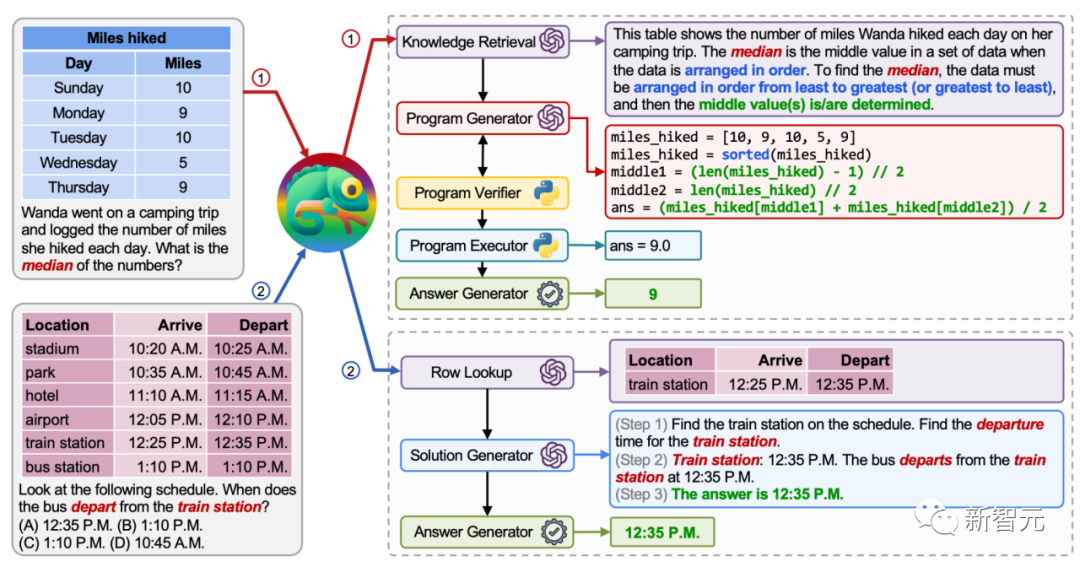
Chameleon模型在表格推理任务TabMWP中同样展现了其出色的灵活性和有效性。TabMWP是一个基于表格上下文的数学推理任务,要求模型理解多种形式的表格并执行精确的数值计算。
在下图的第一个示例中,涉及对计数表格进行数学推理。Chameleon模型调用「知识检索(Knowledge Retrieval)」工具来理解如何计算列表的中位数。然后,它依赖于程序辅助工具进行精确计算。
第二个示例需要在较大的表格上下文中定位到一个单元格。
为此,Chameleon模型调用工具箱中的「行查找(Row Lookup)」工具来准确定位表格中的相关行。接下来,Chameleon模型只需理解简化的表格,然后生成最终的自然语言答案,而无需生成Python代码来增强数学推理。
类似地,Chameleon模型在TabMWP任务中也展现了强大的推理能力。
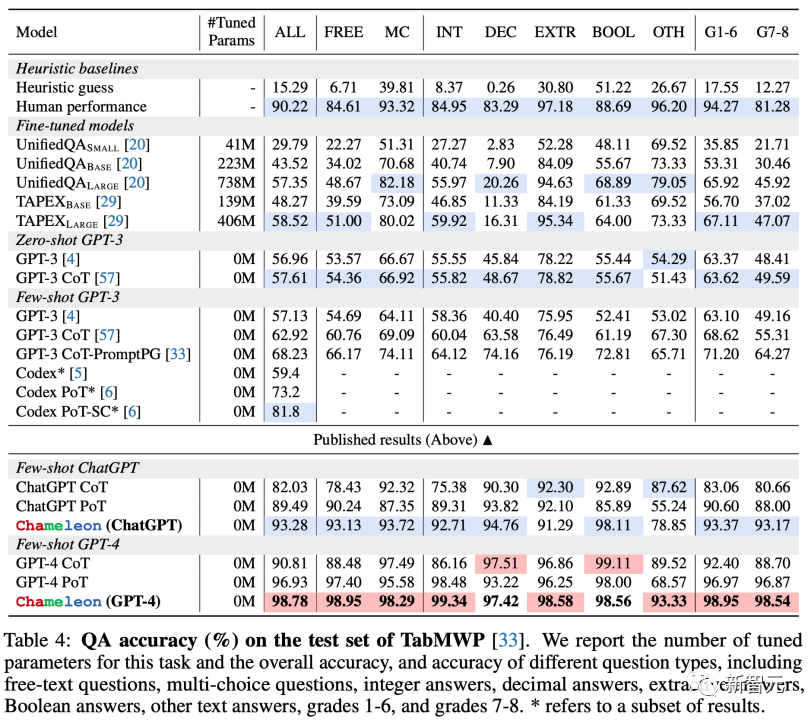
下图突显了这两个任务中的关键基准模型。在ScienceQA任务中,Chameleon模型与GPT-4合作,实现了86.5%的准确率,是当前最优秀的few-shot模型。
同样地,Chameleon在TabMWP数据集上实现了98.8%的准确率,领先最先进模型17.0%的性能。
消融实验揭示Chameleon的关键模块
研究人员进行了消融实验,分析了当禁用生成程序中的关键模块时,Chameleon模型的准确率下降情况。
实验结果显示,「知识检索(Knowledge Retrieval)」模块在两项任务中都扮演了重要的角色。
对于ScienceQA任务,特定领域的工具,如「必应搜索(Bing Search)」和与视觉相关的工具,起到了关键作用,而在TabMWP任务中,常用的「程序生成(Program Generator)」模块对最终性能的影响也非常显著。

Chameleon模型的工具规划能力
不同工具的使用比例
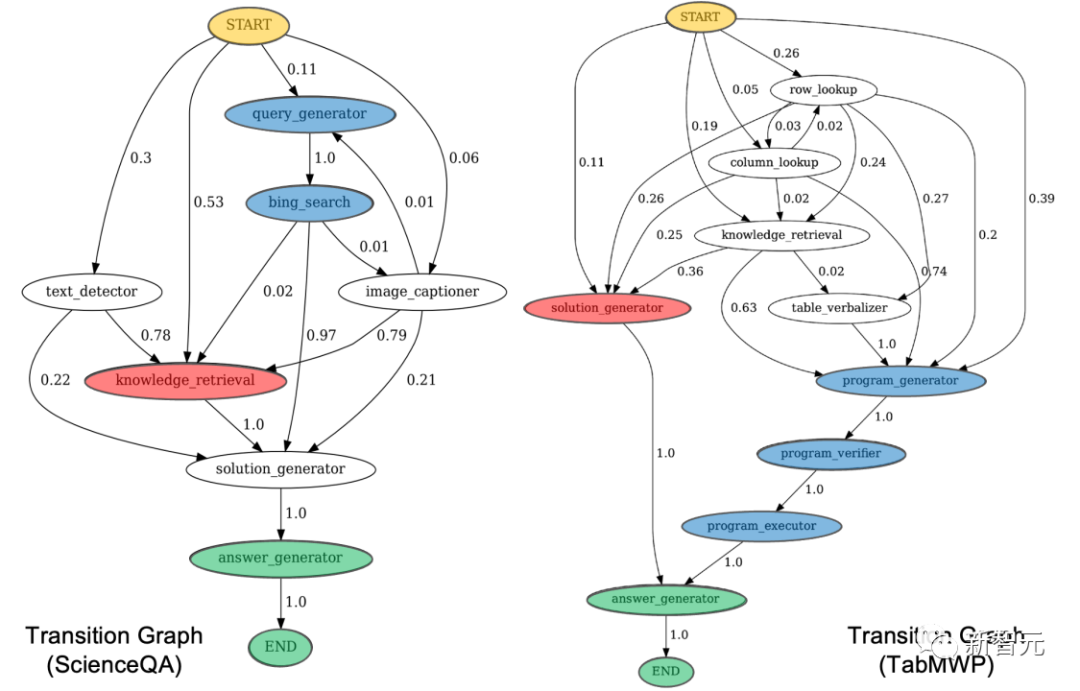
通过可视化Chameleon模型生成的程序中不同工具的使用比例,可以观察到使用不同的语言模型时,LLM规划器表现出不同的规划行为。
通常情况下,ChatGPT对于使用或不使用某些工具有较强的偏好。例如,在回答ScienceQA问题时,ChatGPT倾向于调用「知识检索(Knowledge Retrieval)」,占用比例为72%,而仅在3%的情况下调用「必应搜索(Bing Search)」。
在TabMWP任务中,ChatGPT更依赖「行查找(Row Lookup)」工具,较少调用「列查找(Column Lookup)」。
而GPT-4在工具选择上表现得更加客观和理性。例如,在回答ScienceQA的科学问题时,GPT-4更频繁地调用「知识检索」,并且相对ChatGPT更频繁地调用「Bing搜索」(11% vs. 3%)。

工具调用的转态转移图
通过可视化Chameleon模型生成的程序中不同工具的状态转移图,可以观察到LLM规划器在工具调用中所展现的规律。
例如,在ScienceQA任务中,Chameleon模型通常会选择使用「知识检索(Knowledge Retrieval)」来获取大型语言模型中的内部知识,或者调用「必应搜索(Bing Search)」来获取互联网上的在线信息。
在TabMWP任务中,我们观察到两种主要的工具调用模式:Chameleon模型要么直接通过自然语言推理来完成回答,要么利用程序生成相关的工具来增强逻辑和数学推理。
Chameleon模型的进一步发展
Chameleon模型通过其简单高效的框架,实现了大型语言模型与多种外部工具的高效协同,从而显著增强了在复杂任务上的推理能力。
在大型语言模型的工具增强领域,未来有许多潜在的发展方向:
(1)扩展工具箱:可以将工具箱扩展到更多工具,包括特定领域的工具,如Wolfram。这将进一步增加Chameleon模型在不同任务和领域中的适用性,使其成为更全面的多功能工具。
(2)改进规划器:可以考虑提出更加准确的规划器,例如能够逐步规划下一步骤的工具,并根据执行结果的反馈进行规划优化。这将有助于提高Chameleon模型在复杂任务中的效率和准确性。
(3)轻量化替代:未来可以考虑将涉及到大型语言模型的部分替换为更轻量级的本地模型,以减小计算资源的消耗,提高模型的响应速度,并降低部署成本。这将使Chameleon模型更适用于实际应用场景。
总之,Chameleon模型的未来发展有望在工具增强领域取得更大的突破,为解决复杂问题提供更强大的支持,并拓展其应用范围。