













视频大数据时代,真的来了!
刚刚,李飞飞的斯坦福团队同谷歌合作,推出了用于生成逼真视频的扩散模型W.A.L.T。
这是一个在共享潜在空间中训练图像和视频生成的,基于Transformer的扩散模型。

论文:https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
英伟达高级科学家Jim Fan转发评论道:2022年是影像之年,2023是声波之年,而2024,是视频之年!
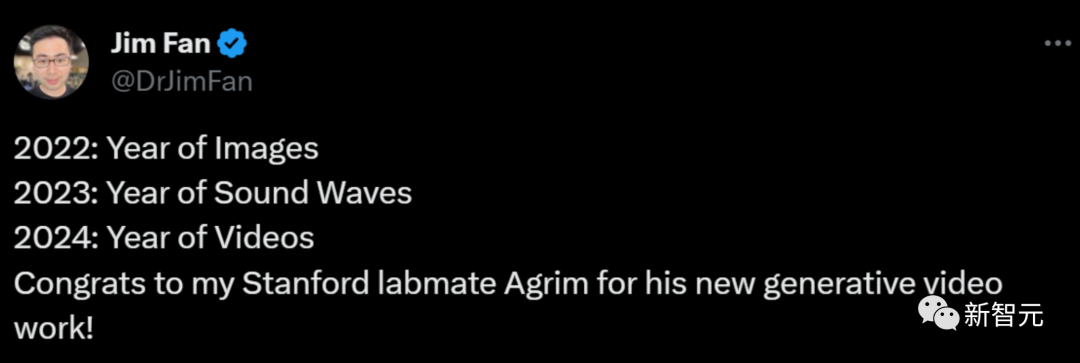
首先,研究人员使用因果编码器在共享潜在空间中压缩图像和视频。
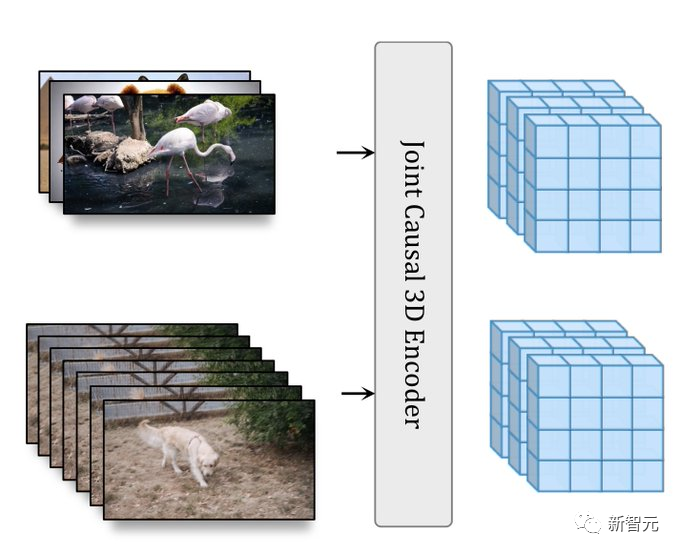
其次,为了提高记忆和训练效率,研究人员使用基于窗口注意的变压器架构来进行潜在空间中的联合空间和时间生成建模。
研究人员的模型可以根据自然语言提示生成逼真的、时间一致的运动:

A Teddy bear skating carefully in Times Square,Slow Motion/一只泰迪熊在时代广场上优雅的滑冰,慢动作

Pouring chocolate sauce over vanilla ice cream in a cone, studio lighting/将巧克力酱倒在香草冰淇淋甜筒上,工作室灯光

An stronaust riding a horse/一名宇航员骑着马

A squirrel eating a burger/一只松鼠在吃汉堡

A panda taking a selfie/一只正在自拍的熊猫

An elephant wearing a birthday hat walking on the beach/一头戴着生日帽的大象在海滩上行走

Sea lion admiring nature, river, waterfull, sun, forest/海狮欣赏自然,河流,瀑布,阳光,森林

Pouring latte art into a silver cup with a golden spoon next to it/在银杯中进行拿铁拉花,旁边放着金勺子

Two knights dueling with lightsabers,cinematic action shot,extremely slow motion/两个骑士用光剑决斗,电影动作镜头,极其慢动作
A swarm of bees flying around their hive/一群蜜蜂在他们的蜂巢周围飞翔
这个结构还可以用图片生成视频:

A giant dragon sitting in a snow covered landscape, breathing fire/一条巨大的龙盘踞在冰雪覆盖的大地上,喷吐着火焰

A cute panda skateboarding in the sky, over snow covered mountains, with a dreamy and whimsical atmosphere/一只可爱的熊猫在天空中滑滑板,越过雪山,充满梦幻和异想天开的气氛

An asteroid collides with Earth, massive explosive, slow motion/小行星撞上地球,大规模爆炸,慢动作
以及,生成一致性很高的3D相机运动的视频。

Cameraturns around a cute bunny, studio lighting, 360 rotation/相机围绕一只可爱的兔子旋转,工作室灯光,360度旋转

Camera turns around utah teapot,studio lighting,360 rotation/相机围绕茶壶旋转,工作室灯光,360度旋转

Camera turns around a burger on a plate,studio lighting,360 rotation/相机围绕盘子中的汉堡旋转,工作室灯光,360度旋转
网友们惊叹道,这些天好像已经人手一个LLM或者图像生成器。
今年简直是AI发展的煽动性的一年。

两个关键决策,组成三模型级联
W.A.L.T的方法有两个关键决策。
首先,研究者使用因果编码器在统一的潜在空间内联合压缩图像和视频,从而实现跨模态的训练和生成。
其次,为了提高记忆和训练效率,研究者使用了为空间和时空联合生成建模量身定制的窗口注意力架构。
通过这两个关键决策,团队在已建立的视频(UCF-101 和 Kinetics-600)和图像(ImageNet)生成基准测试上实现了SOTA,而无需使用无分类器指导。
最后,团队还训练了三个模型的级联,用于文本到视频的生成任务,包括一个基本的潜在视频扩散模型和两个视频超分辨率扩散模型,以每秒8帧的速度,生成512 x 896分辨率的视频。
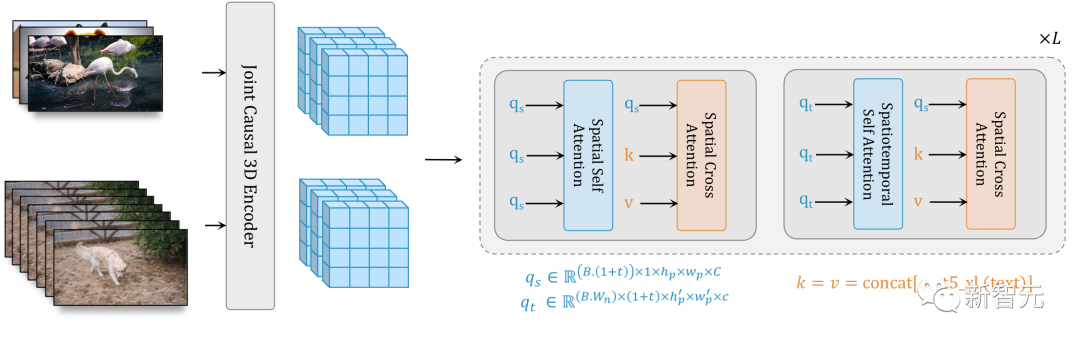
W.A.L.T的关键,是将图像和视频编码到一个共享的潜在空间中。
Transformer主干通过具有两层窗口限制注意力的块来处理这些潜在空间——空间层捕捉图像和视频中的空间关系,而时空层模拟视频中的时间动态,并通过身份注意力掩码传递图像。
而文本调节,是通过空间交叉注意完成的。
W.A.L.T解决视频生成建模难题
Transformer是高度可扩展和可并行的神经网络架构,是目前最当红的构架。
这种理想的特性也让研究界越来越青睐Transformer,而不是语言 、音频、语音、视觉、机器人技术等不同领域的特定领域架构。
这种统一的趋势,使研究人员能够共享不同传统领域的进步,这样就造就了有利于Transformer的模型设计创新和改进的良性循环。
然而,有一个例外,就是视频的生成建模。
扩散模型已成为图像和视频生成建模的领先范例。然而,由一系列卷积层和自注意力层组成的U-Net架构一直是所有视频扩散方法的主流。
这种偏好源于这样一个事实:Transformer中完全注意力机制的记忆需求,与输入序列的长度呈二次方缩放。
在处理视频等高维信号时,这种缩放会导致成本过高。

潜在扩散模型可以通过在从自动编码器派生的低维潜在空间中运行,来降低计算要求。
在这种情况下,一个关键的设计选择,就是所使用的潜在空间的类型:空间压缩 (每帧潜在) 与时空压缩。
空间压缩通常是首选,因为它可以利用预训练的图像自动编码器和LDM,它们在大型成对图像文本数据集上进行训练。
然而,这种选择增加了网络复杂性,并限制了Transformer作为骨干网的使用,尤其是由于内存限制而生成高分辨率视频时。
另一方面,虽然时空压缩可以缓解这些问题,但它排除了配对图像文本数据集的使用,后者比视频数据集更大、更多样化。
因此,研究者提出了窗口注意力潜在Transformer (W.A.L.T) :一种基于Transformer的潜在视频扩散模型 (LVDM) 方法。
该方法由两个阶段组成。
首先,自动编码器将视频和图像映射到统一的低维潜在空间中。这种设计能够在图像和视频数据集上联合训练单个生成模型,并显著减少生成高分辨率视频的计算负担。
随后,研究者提出了一种用于潜在视频扩散建模的Transformer块的新设计,由在非重叠、窗口限制的空间和时空注意力之间交替的自注意力层组成。
这种设计有两个主要好处——
首先,使用局部窗口注意力,可以显著降低计算需求。
其次,它有利于联合训练,其中空间层独立处理图像和视频帧,而时空层致力于对视频中的时间关系进行建模。
虽然概念上很简单,但团队的方法让Transformer在公共基准上潜在视频传播中表现出了卓越的质量和参数效率,这是第一个经验证据。
具体来说,在类条件视频生成 (UCF-101) 、帧预测 (Kinetics-600) 和类条件图像生成 (ImageNet)上, 不使用无分类指导,就取得了SOTA。
最后,为了证明这种方法的可扩展性和效率,研究者还生成了逼真的文本到视频生成效果。
他们训练了由一个基本潜在视频扩散模型和两个视频超分辨率扩散模型组成的级联模型,以每秒8帧的速度生成512X896分辨率的视频,并且在UCF-101基准测试中,取得了SOTA的zero-shot FVC分数。

学习视觉符号
视频生成建模中的一个关键设计决策,就是潜在空间表征的选择。
理想情况下,需要一个共享且统一的压缩视觉表征,可用于图像和视频的生成建模。
统一的表征很重要,这是因为由于标记视频数据(例如文本视频对)的稀缺,联合的图像-视频学习更可取。
为了实现视频和静态图像的统一表征,第一帧始终独立于视频的其余部分进行编码。
为了将这个设计实例化,研究者使用了MAGVIT-v2分词器的因果3DCNN编码器-解码器。
通常,编码器-解码器由常规D卷积层组成,它们无法独立处理第一帧。
而因果3D卷积层解决了这个问题,因为卷积核仅对过去的 帧进行操作。
帧进行操作。
这就确保了每个帧的输出仅受前面帧的影响,从而使模型能够独立标记第一帧。

实验
视频生成
研究人员考虑了两个标准视频基准,即类别条件生成的UCF-101和带有5个条件帧的视频预测Kinetics-600。
研究人员使用FVD 作为主要评估指标。在这两个数据集上,W.A.L.T 显著优于之前的所有工作(下表1)。
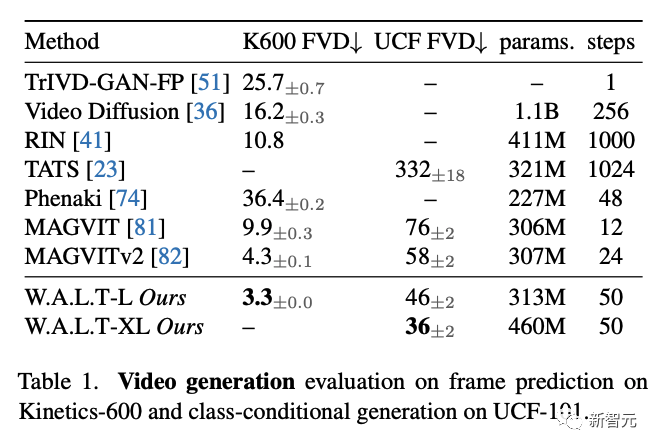
与之前的视频扩散模型相比,研究人员在模型参数更少的情况下实现了最先进的性能,并且需要50个DDIM推理步骤。
图像生成
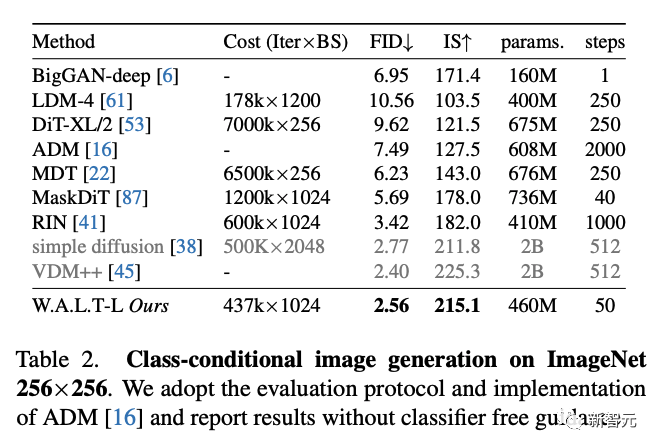
为了验证W.A.L.T在图像领域的建模能力,研究人员训练了一个W.A.L.T版本,用于标准的ImageNet类别条件设置。
在评估中,研究人员遵循ADM并报告在50K样本上用50个DDIM步骤生成的FID和Inception分数。
研究人员将W.A.L.T与256 × 256分辨率的最先进图像生成方法进行比较(下表2)。研究人员的模型在不需要专门的调度、卷积归纳偏见、改进的扩散损失和无分类器指导的情况下优于之前的工作。尽管VDM++的FID分数略有提高,但该模型的参数明显更多(2B)。
消融实验
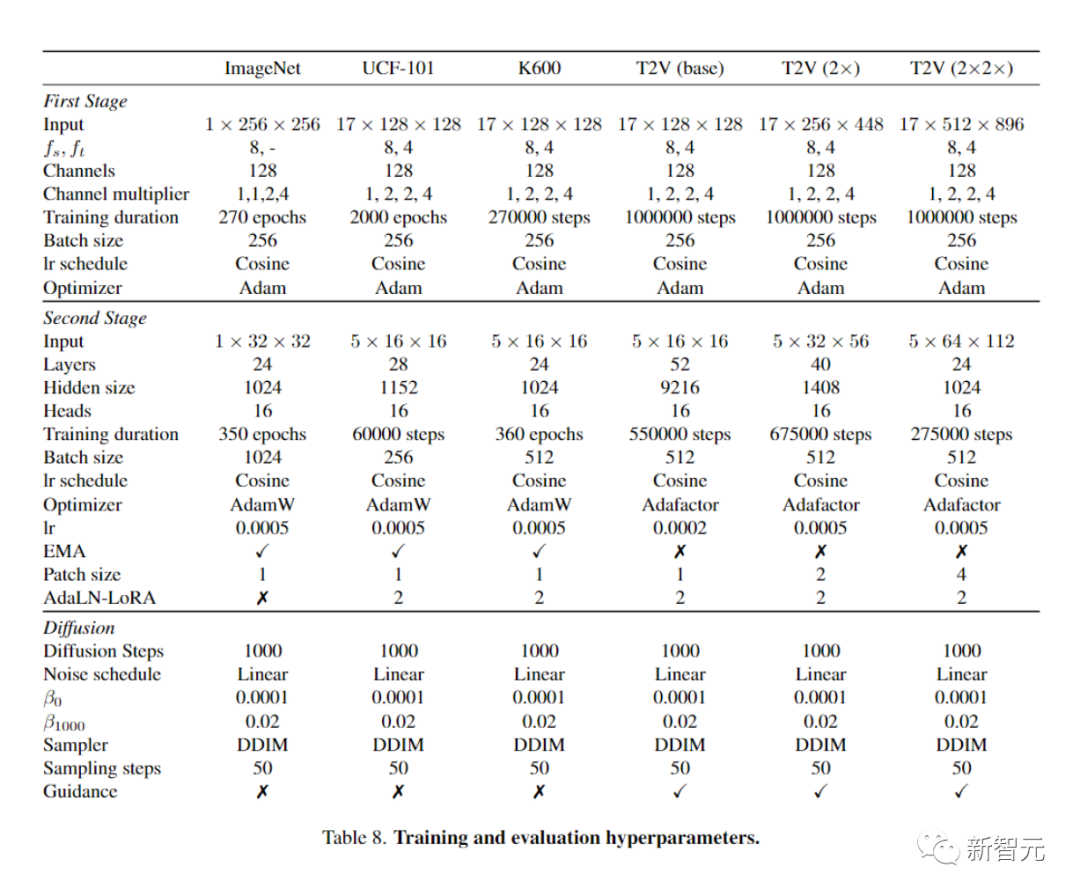
在使用ViT -based模型的各种计算机视觉任务中,已经证明较小的补丁大小p可以始终提高性能。同样,研究人员的研究结果也表明,减小补丁大小可以提高性能(下表3a)。
窗口注意力
研究人员比较了三种不同的STW窗口配置与全自注意(表3b)。研究人员发现,局部自注意力可以在速度上显著更快(高达2倍)并且减少加速器内存的需求,同时达到有竞争力(或更好)的性能。

文生视频
研究者在文本-图像和文本-视频对上,联合训练了文本到视频的W.A.L.T。
使用的是来自公共互联网和内部来源的约970M文本-图像对,和约89M文本-视频对的数据集。
定性评估
W.A.L.T根据自然语言提示生成的示例视频,分辨率为512*896,持续时间为3.6秒,每秒8帧。
W.A.L.T模型能够生成与文本提示一致、时间一致的逼真视频。

研究人员在以1或2个潜在帧为条件的帧预测任务上,联合训练了模型。
因此,模型可用于图像动画(图像到视频)和生成具有连贯镜头运动的较长视频。

定量评价
科学地评估文本条件视频生成系统仍然是一个重大挑战,部分原因是缺乏标准化的训练数据集和基准。
到目前为止,研究人员的实验和分析主要集中在标准学术基准上,这些基准使用相同的训练数据来确保受控和公平的比较。
尽管如此,为了与之前的文本到视频工作进行比较,研究人员还在表 5 中的零样本评估协议中报告了 UCF-101 数据集的结果。
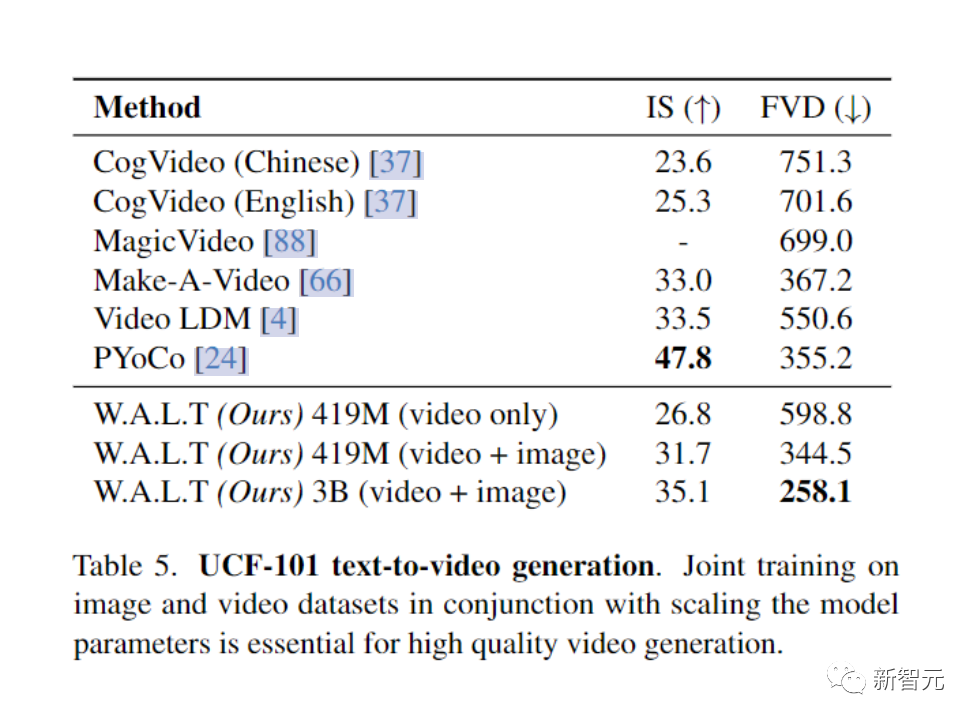
研究人员框架的主要优势是它能够同时在图像和视频数据集上进行训练。
在上表5中,研究人员消除了这种联合训练方法的影响。
具体来说,研究人员使用第5.2 节中指定的默认设置训练了两个版本的W.A.L.T-L (每个版本有 419M 参数)模型。
研究人员发现联合培训可以使这两个指标都有显著改善。















