NeurIPS 是当前全球最负盛名的 AI 学术会议之一,全称是 Neural Information Processing Systems,神经信息处理系统大会,通常在每年 12 月由 NeurIPS 基金会主办。大会讨论的内容包含深度学习、计算机视觉、大规模机器学习、学习理论、优化、稀疏理论等众多细分领域。
12 月 10 日,NeurIPS 2023 在美国路易斯安那州新奥尔良市拉开帷幕。根据官网博客公布的数据,今年大会收到的论文投稿数量创造了新纪录,达到 13321 篇,由 1100 名领域主席、100 名高级领域主席和 396 名伦理审稿人审查,其中 3584 篇论文被接收。
刚刚,NeurIPS 官方公布了 2023 年度的获奖论文,包括时间检验奖、两篇杰出论文、两篇杰出论文 runner-up、一个杰出数据集和一个杰出基准,其中大部分论文都是围绕大型语言模型(LLM)展开的工作。值得注意的是,十年前发布的 word2vec 相关论文摘得了时间检验奖,可谓实至名归。

以下是获奖论文的具体信息。
时间检验奖
今年的时间检验奖颁给了十年前的 NeurIPS 论文「Distributed Representations of Words and Phrases and their Compositionality」。

这篇论文由当时都还在谷歌的 Tomas Mikolov、Ilya Sutskever、Kai Chen、Greg Corrado、Jeffrey Dean 等人撰写,被引量超过 4 万次。

论文地址:https://arxiv.org/pdf/1310.4546.pdf
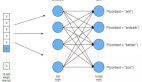
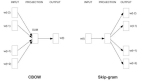
NeurIPS 官方给出的颁奖理由是:这项工作引入了开创性的词嵌入技术 word2vec,展示了从大量非结构化文本中学习的能力,推动了自然语言处理新时代的到来。
在机器之心原创技术分析文章《从 word2vec 开始,说下 GPT 庞大的家族系谱》中,我们曾介绍过 word2vec 的重要性。Word2Vec 和 Glove 等词嵌入方法可以说是当前最为热门的 GPT 家族老祖级别的研究,引领了后续庞大的 NLP「家族集团」,也为整个 NLP 技术的蓬勃发展奠定了坚实的基础。

从 Word2Vec 等词嵌入技术开始到后续的重要模型

机器之心整理的重要 NLP 模型发展脉络
所以说,在大模型备受关注的 2023 年,Word2vec 获得 NeurIPS 的时间检验奖也实至名归了。
这里补充一句,其实提到 Word2vec,首篇论文应该是 Tomas Mikolov 等同一作者的「Efficient Estimation of Word Representations in Vector Space」。而投稿到当年 NeurIPS 这篇「Distributed Representations of Words and Phrases and their Compositionality」算是真正让 Word2vec 被广泛应用的改进论文。
如果有读者想要详细了解、学习 Word2vec,也可以查阅机器之心原创技术分析文章《词嵌入的经典方法,六篇论文遍历 Word2vec 的另类应用》。
Main Track 杰出论文奖
获奖论文 1:Privacy Auditing with One (1) Training Run

- 论文地址:https://arxiv.org/abs/2305.08846
- 机构:Google
摘要:本文提出了一种通过单次训练来检查差分隐私机器学习系统的方案。该方案利用了差分隐私机器学习系统能够独立添加或删除多个训练示例的并行性。研究者们从这一点入手,分析了差分隐私和统计泛化的联系,从而避免了群体隐私的成本。这种方案对算法的假设要求极低,可应用于黑盒或白盒环境。研究者们在 DP-SGD 中运用了这项方案,以检验其有效性。在 DP-SGD 中,本文中提出的框架只需要训练一个模型,就能实现有意义的经验隐私下界。相比之下,标准方法需要训练数百个模型。
获奖论文 2:Are Emergent Abilities of Large Language Models a Mirage?

- 论文地址:https://arxiv.org/abs/2304.15004
- 机构:斯坦福大学
摘要:最近有研究称,大语言模型「涌现」出了在小规模模型中不存在的能力。大模型「涌现」能力之所以吸引人,有两个原因:一是其突现性,这些能力几乎是一瞬间出现的;二是涌现的能力具体将在哪种规模的模型中出现,不可预测。因此,研究者们对涌现能力提出了一种新解释:对于特定的任务和模型家族,在分析固定的模型输出时,「涌现」能力的出现是由于研究者选择了特定的度量标准,而不是模型的表现随规模发生了根本性的变化。
具体来说,非线性或者不连续度量会产生明显的「涌现」能力,而线性或连续度量则会产生平滑、连续、可预测的模型性能变化。研究者们在一个简单的数学模型中提出了这项新解释,并通过三种互补的方式对其进行了检验。首先,他们在 InstructGPT/GPT-3 系列中对声称具有「涌现」能力的任务检验了这项新假设的三项内容;其次,在 BIG-Bench 的涌现能力元分析中制定、测试并证实了两个关于度量标准选择的预测;最后,论文中展示了如何选择度量标准,以在不同深度网络的多个视觉任务中「创造出」前所未有的「涌现」能力。
通过以上的分析,论文证明了所谓的「涌现」能力会随着不同的度量或统计方式消失,而并非人工智能的基本属性得到了扩展。
Main Track 杰出论文 Runner-up 奖
获奖论文 1:Scaling Data-Constrained Language Models

- 论文链接:https://arxiv.org/abs/2305.16264
- 项目链接:https://github.com/huggingface/datablations
- 机构:Hugging Face、哈佛大学、图尔库大学
摘要:增加参数数量、扩大训练数据集的规模是当今语言模型的发展趋势。根据这一趋势推断,训练数据集的规模可能很快就会受互联网上可用文本数据量的限制。受到这一可见趋势的启发,有研究者对数据受限情况下语言模型的拓展进行了探索。
具体来说,他们通过改变数据的重复程度和计算预算,进行了大量的实验。实验中的数据量最高可达 9000 亿个训练 token,模型规模可达 90 亿个参数。研究者发现,在计算预算固定、数据受限的情况下,使用重复数据进行 4 个周期(epoch)的训练,与使用不重复的数据相比,损失的变化可以忽略不计。然而,随着重复次数的增加,增加计算量的价值最终会降至零。研究者们进而提出并实证验证了一个计算最优化的扩展定律(scaling law),该定律考虑了重复 token 和多余参数价值递减的问题。最后,他们尝试了多种缓解数据稀缺性的方法,包括使用代码数据扩充训练数据集或删除常用的过滤器。本研究的模型和数据集可在以下链接中免费获取:https://github.com/huggingface/datablations
获奖论文 2:Direct Preference Optimization: Your Language Model is Secretly a Reward Model

- 论文链接:https://arxiv.org/abs/2305.18290
- 机构:斯坦福大学、 CZ Biohub
摘要:虽然大规模无监督语言模型(LMs)可以广泛地学习世界中的知识,获得一些推理技能,但由于其训练完全不受监督,因此很难实现对其行为的精确控制。目前获得这种可控性通常依靠人类反馈强化学习(RLHF)这种方法实现,收集人类对各种模型生成质量打出的标签,并根据这些偏好对无监督语言模型进行微调。然而,RLHF 是一个复杂并且经常不稳定的过程。它首先需要拟合一个反映人类偏好的奖励模型,然后利用强化学习对大型无监督语言模型进行微调,以最大限度地提高预计中的奖励,同时又不会偏离原始模型太远。
在这项研究中,研究者们通过奖励函数和最优策略之间的映射关系证明了只需进行一个阶段的策略训练,就能精确优化受限奖励的最大化问题。从根本上解决了人类偏好数据的分类问题。研究者们称这种新方法为:直接偏好优化(DPO),它稳定、高效、计算量小,无需拟合奖励模型、在微调过程中从语言模型中采样,或执行重要的超参数调整。实验表明,DPO 能够微调 LM 以符合人类偏好,其效果与现有方法相当或更好。值得注意的是,与 RLHF 相比,使用 DPO 进行微调在控制生成内容的情感、提高摘要和单轮对话的响应质量方面表现更好,同时实现和训练过程大大简化。
杰出数据集和基准论文
数据集
获奖论文:ClimSim: A large Multi-scale Dataset for Hybrid Physics-ML Climate Emulation

- 论文地址:https://arxiv.org/pdf/2306.08754.pdf
- 机构:UCI、 LLNL、Columbia、UCB、MIT、DLR、Princeton 等
论文摘要:由于计算限制,现代气候预测缺乏足够的空间和时间分辨率,导致对风暴等极端气候预测不准确、不精确。这时融合物理与机器学习的混合方法引入了新一代保真度更高的气候模拟器,它们可以通过将计算需求巨大、短时、高分辨率的模拟任务「外包」给机器学习模拟器以绕过摩尔定律桎梏。不过,这种混合的机器学习 - 物理模拟方法需要针对特定领域具体处理,并且由于缺乏训练数据以及相关易用的工作流程,机器学习专家们也无法使用。
本文中,研究者推出了 ClimSim,一个专为混合机器学习 - 物理研究设计的迄今为止最大的数据集,包含了气候科学家和机器学习研究人员联合开发的多尺度气候模拟。具体来讲,ClimSim 由 57 亿个多元输入和输出向量对组成,它们隔绝了局部嵌套、高分辨率、高保真度物理对主机气候模拟器宏观物理状态的影响。该数据集覆盖全球,以高采样频率持续多年,设计生成的模拟器能够与下游的操作气候模拟器相兼容。

ClimSlim 的局部空间版本。
研究者实现了一系列确定性和随机回归基线,以突出机器学习挑战和基线得分。他们公开了相关数据和代码,用以支持混合机器学习 - 物理和高保真气候模拟的开发,造福科学和社会。
项目地址:https://leap-stc.github.io/ClimSim/README.html
基准
获奖论文:DECODINGTRUST: A Comprehensive Assessment of Trustworthiness in GPT Models

- 论文地址:https://arxiv.org/pdf/2306.11698.pdf
- 机构:伊利诺伊大学厄巴纳 - 香槟分校、斯坦福大学、UC 伯克利、AI 安全中心、微软
论文摘要:GPT 模型在能力层面已经展现出了无与伦比的进展,但有关 GPT 模型可信度的文献仍然不多。从业者提议将强大的 GPT 模型用于医疗和金融领域的敏感性应用,可能面临高昂的代价。
为此,本文研究者对大型语言模型进行了全面可信度评估,并以 GPT-4 和 GPT-3.5 为重点模型,充分考虑了不同的视角,包括毒性(toxicity)、刻板印象偏差、对抗稳健性、分布外稳健性、对抗演示稳健性、隐私、机器伦理道德和公平性等。评估结果发现了以往未曾披露的可信度威胁漏洞,例如 GPT 模型很容易被误导,从而输出有毒和有偏见的内容,并泄露训练数据和对话记录中的个人信息。

大模型可信度评估指标。
研究者还发现,虽然在标准基准上 GPT-4 比 GPT-3.5 更值得信赖,但由于 GPT-4 更精确地遵循误导性指令,因而它也更容易受到攻击。
基准测试:https://decodingtrust.github.io/