













本文经自动驾驶之心公众号授权转载,转载请联系出处。
最近关于大模型(LLMs, VLM)与自动驾驶相关文献调研与汇总:
适合用于什么任务?答:目前基本上场景理解、轨迹预测、行为决策、运动规划、端到端控制都有在做。
大家都怎么做的?
- 对于规控任务,LLM型基本是调用+Prompt设计,集中在输入和输出设计,如输入有 1.2 DiLu这种拼memory的,输出有1.1 LanguageMPC这种做cost function的,训练和微调的有1.3 Wayve的工作;有做开环的1.3,也有闭环的1.1 和1.2。目前仿真器和数据都未有统一的benchmark。
- 对于场景理解任务,大多数都在构建QA类型的数据集,常用数据集为nuScenes。
一、自动驾驶决策/规划任务:
1. 1 LanguageMPC: Large Language Models As Decision Makers For Autonomous Driving, 10.4
动机:学习型决策系统缺乏 理解、泛化和可解释性,LLM具备推理和泛化能力,如何作为决策器与下游控制器结合?Language-action对齐到了MPC的cost function。
方案:
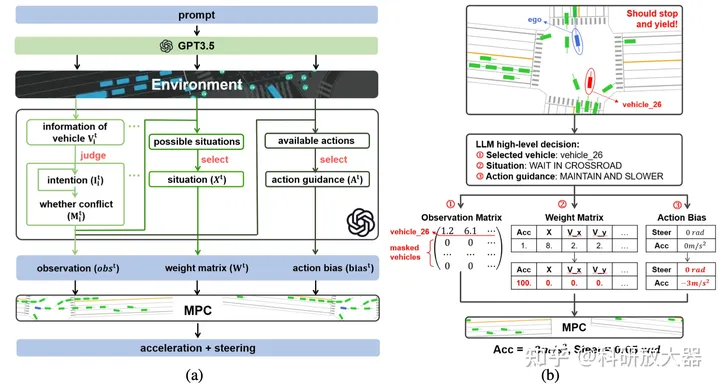
LLM的任务1) 选择关键交互车辆 2)评估当前驾驶情况 3) 提供决策动作引导。下游控制器采用了MPC controller,Language-action的输出为 observation matrix, weight matrix, and action bias,前者对应的是关键交互车辆,后两者对应MPC中Cost function的参数项。
 对于上述3步所设计的prompts
对于上述3步所设计的prompts
实验环境:CARLA路口、环岛等。调用GPT3.5,定义输出action,输入非视觉可理解为将原先vector输入语言化。
1.2. DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models, 9.28
动机:用LLM增强agent的泛化和可解释性。这篇文章的创新在于memory module的引入,是7月份Drive Like a Human的改进版,值得一看。
框架:用GPT3.5作为推理输出模块,用GPT4作为reflection模块。所有模块非fine-tuning,而是输入adaption
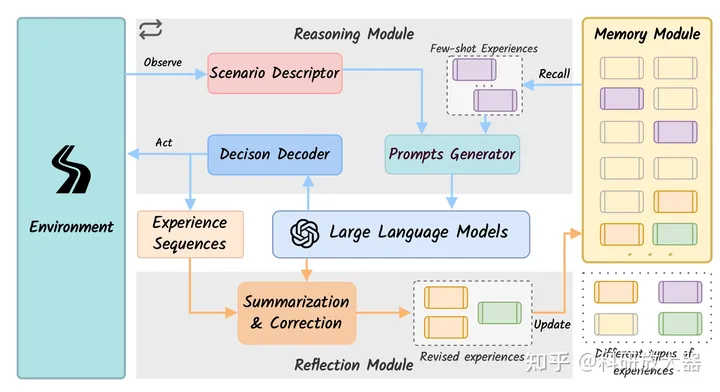
有意思的结论:LLM cannot directly perform the closed-loop driving tasks without any adaptation. 通过记忆模块消融分析得到。
实验环境:HighwayEnv,闭环;加速,保持,跟车,换道等高层行为,没说decision decoder是什么,如何映射的高层行为到底层控制。对比基线为 RL。
1.3 Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving,10.3 Wayve
动机:OOD的推理和可解释能力;对于目标级输入构建LLM的预训练和微调方法,开放驾驶QA数据和评估基线。还有一个相关blog: LINGO-1: Exploring Natural Language for Autonomous Driving
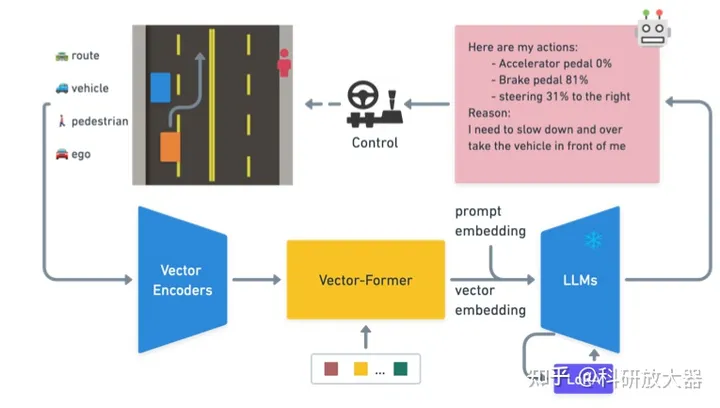
方法:action teacher:RL teacher;QA teacher:GPT teacher;
❝
一个结构化的语言生成器(lanGen):基于数值向量来产生prompt模版;使用RL产生专家动作O_{rl},100k问答数据从仿真器收集 (包括表征学习,推理任务:action预测,attention预测)

❝
驾驶问答数据标注:使用ChatGPT来自动产生问答数据, 10k

❝
训练过程:第一阶段 训练vectorformer,输入为高维的vector向量信息 第二阶段:利用QA问答数据来finetuning LLaMA-7b
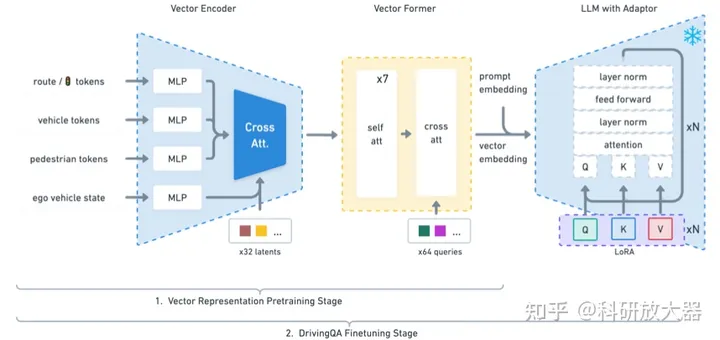
实验:在1000个不同驾驶场景中评估,指标为感知和预测精度;在开放世界场景中评估,通过ChatGPT来评估得分。要求20GB显存来评估,40GB显存来训练。
1.4 GPT-DRIVER: LEARNING TO DRIVE WITH GPT,10.2
动机:推理能力和泛化
方法:1. planner inputs and outputs as language tokens 2. a novel prompting-reasoning-finetuning strategy
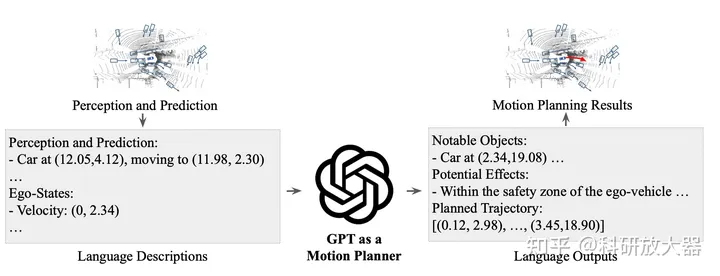
输入语言token化,使用的UniAD的感知和预测结构,输出思维链与上一篇类似,LLM先输出关键交互车、再判断行为决策动作,最后输出轨迹。对chatGPT做了fine-tuning
实验环境:NuScenes,开环,对比UniAD
1.5 Drive as You Speak: Enabling Human-Like Interaction with Large Language Models in Autonomous Vehicles,9.19
动机:LLM赋能
- Language Interaction
- Contextual Understanding and Reasoning
- Zero-Shot Planning
- Continuous Learning and Personalization
- Transparency and Trust
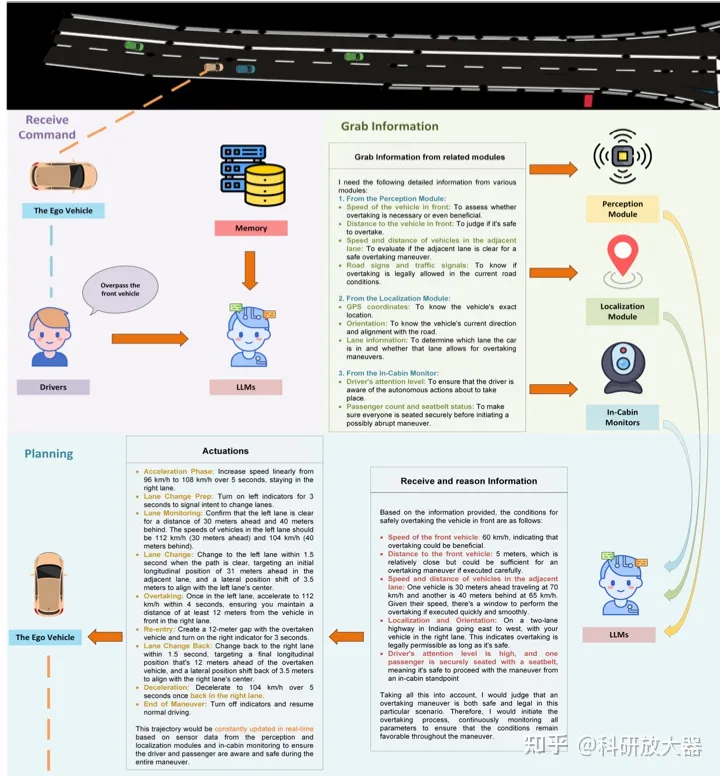
方案:更多探索人机协同,驾驶员给予指令,LLM ChatGPT 4获取感知结果,输出决策行为。没有给实验,只给了上图的case。
1.6 Receive, Reason, and React: Drive as You Say with Large Language Models in Autonomous Vehicles, 10.12
同1.5,进一步分析了ICL,CoT,Personalization方面的能力。
1.7 A Language Agent for Autonomous Driving, 11.17 (单位有Nvidia)
动机:用Agent框架重塑自动驾驶系统,Agent Driver,三个重要组件:tool library;cognitive memory;reasoning engine;
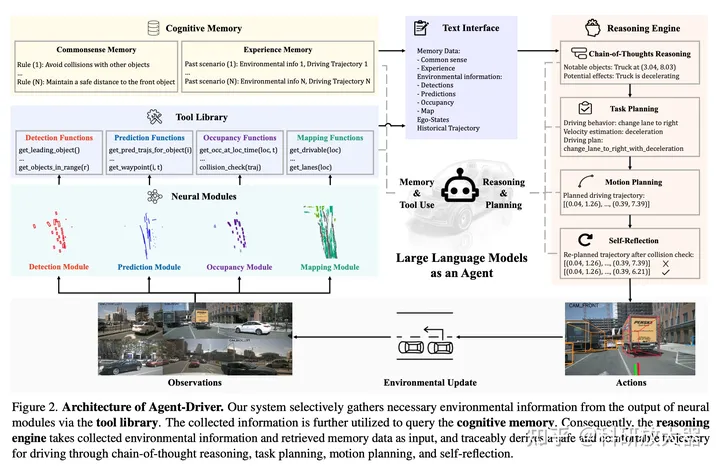
方法:输入为sensory data;输出为轨迹;
Tools:抽象不同网络输出并转化为text文本,即LLM调用tools来收集文本形式的环境信息;tool库是4类神经网络模型 检测(产生检测结果)、预测(产生预测结果)、占据栅格、地图,但模型产生的信息过于冗余,LLM-based tools目的是为了从冗余的信息中提取到必要的环境信息。
Cognitive memory:基于环境信息query来搜索traffic rules (纯文本形式;可以认为是考驾照科目1的学习材料) 和 similar past experience(环境信息和decision);past experience记忆搜索形式:vector-space KNN + LLM-based fuzzy search
Reasoning:LLM-based CoT作为推理引擎,最终输出轨迹,形式如GPT-Driver,自我反思部分基于碰撞检测和优化方法;如果碰撞检测到危险,会利用优化cost function形式将LLM 产生的轨迹进行优化;

实验还是在Nusenses数据集上的开环评测,对标的是UniAD和GPT-Driver,消融分析了ICL和fine-tuning的性能差异,结论是ICL是首选。
1.8 A Multi-Task Decision-Making GPT Model for Autonomous Driving at Unsignalized Intersections 6.30
不是大模型,trained PPO作为teacher,收集多任务教师数据用的 decision Transformer训多任务策略。没太多可看的。
二、 轨迹预测
2.1 Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving,9.13 Bosch
动机:可以将LLM看作foundation model,集成视觉特征和文本特征,进行轨迹预测获得最好效果
方案:由于GPT系列难以得到中间feature,对于文本使用的是DistilBert,对于BEV使用了BEiT作为encoder,
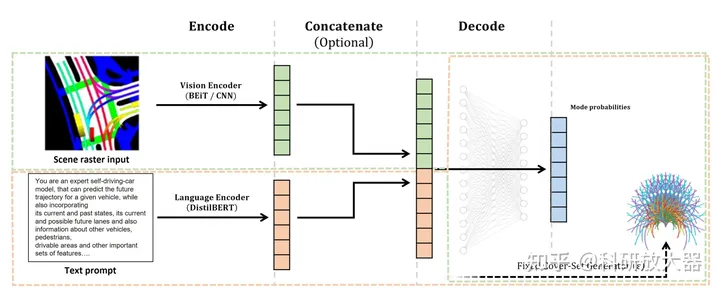

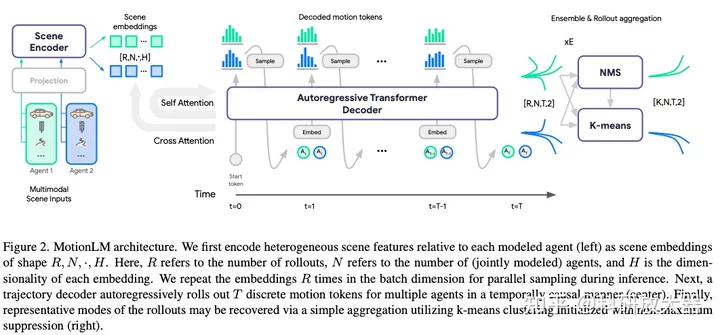
2.2 MotionLM: Multi-Agent Motion Forecasting as Language Modeling, ICCV, 2023, Waymo
动机:autoregressive language models作为多智能体轨迹预测模型,在waymo交互预测任务取得SoTA
方案:使用的是LLM类似的自回归transformer decoder,但chatGPT本身没有太大联系。可以同时decoder多个智能体,不开源,
三、端到端控制任务:
3.1 DRIVEGPT4: INTERPRETABLE END-TO-END AUTONOMOUS DRIVING VIA LARGE LANGUAGE MODEL,10.2
动机:可解释性、泛化性。同时多模态大模型还可处理图像和视频数据;可解释性端到端模型,用黑盒解释黑盒,具备了人机交互层面的可解释性。
数据集生成:在BDDK的16k固定问答数据上,用chatGPT产生了新的12k问答数据
模型训练:使用Valley将video token转化为语言token,LLM使用了LLaMA 2;预训练阶段只训练video tokenizer;fine-tuning阶段LLM和video tokenizer在29k数据上一起微调,同时为了保障它的问答能力,还在80k的问答数据上一起微调

实验环境:开环,视觉输入,BDD-K,对比基线为ADAPT,metric:使用了ChatGPT打分。
3.2 ADAPT: Action-aware Driving Caption Transformer,ICRA,2023,开源代码,中文解读
动机:端到端模型的可解释性
方法:连续多帧图像输入,预训练的video swin transformer 得到video tokens,预测控制信号和文本输出。
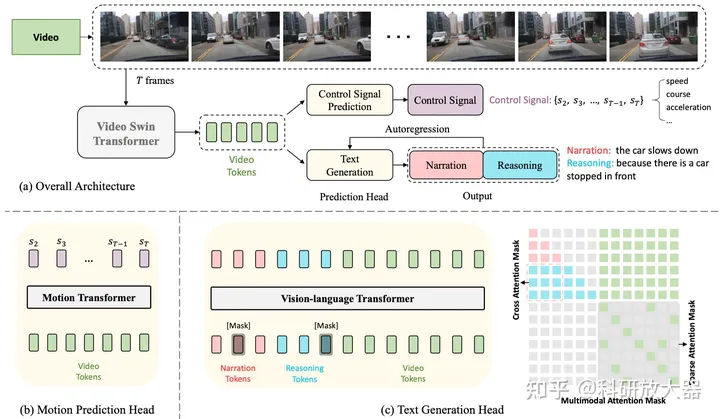
实验环境:开环,BDD-K,具体见中文解读。
四、多视角视觉输入场景理解:
4.1 Language Prompt for Autonomous Driving,9.8
动机:缺少多视角输入的language prompt-instance 数据
方案:第1步:3D目标检测,目标包括4类属性 color,class,action,location, 手工标注13k目标;第2步:属性与或非操作的组合;第3步:让GPT3.5产生描述的language prompt,35k. 基于nuScenes数据集。
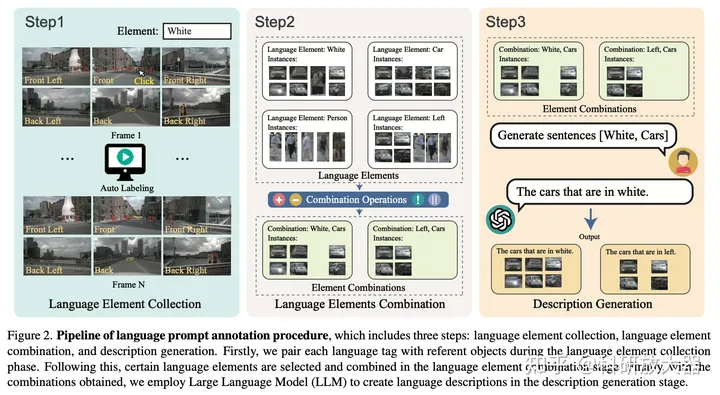
基于此数据集,做了prompt输入的多目标跟踪任务。整体效果为:利用视觉和language prompt,可以检测和跟踪多视角连续帧输入的目标。
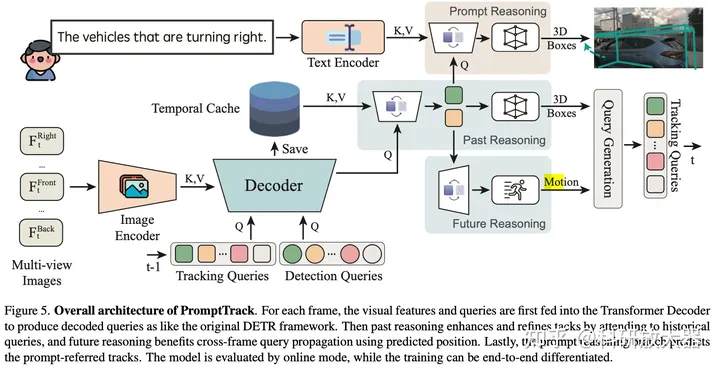
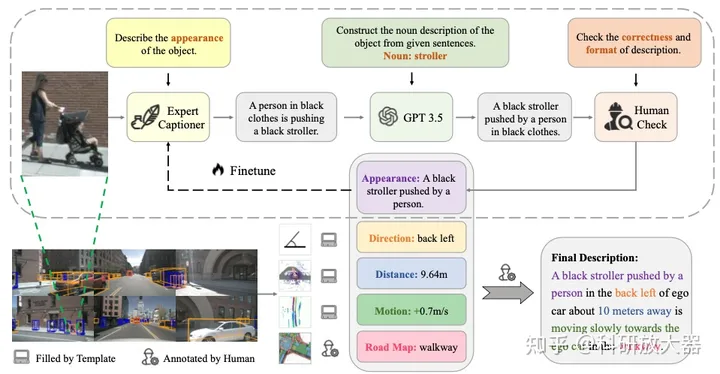
4.2 3D DENSE CAPTIONING BEYOND NOUNS: A MIDDLE-WARE FOR AUTONOMOUS DRIVING
动机:目前缺少衔接 感知和规划的3D场景理解的LLM数据集,3D dense captioning
方案:3D目标属性:Appearance Direction Distance Motion Road Map
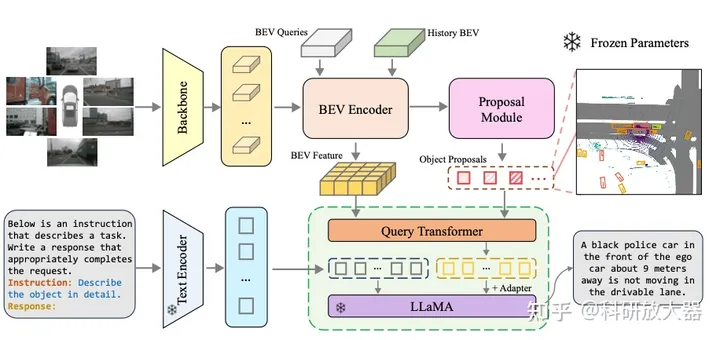
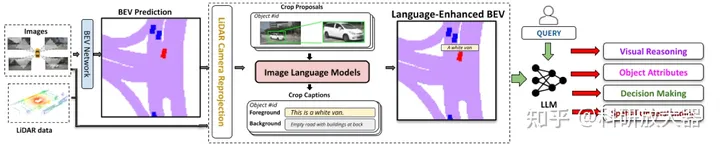
4.3 Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous Driving
与3.2类似,是对BEV input做了语言prompt.

4.4 DriveLM: Drive on Language, OpenDriveLab
LLM将用于感知、预测和规划任务,graph of thouht. 相比于3.2,多做了预测和规划。在nuScenes上360k annotated QA pairs。目前只开源了demo样例。

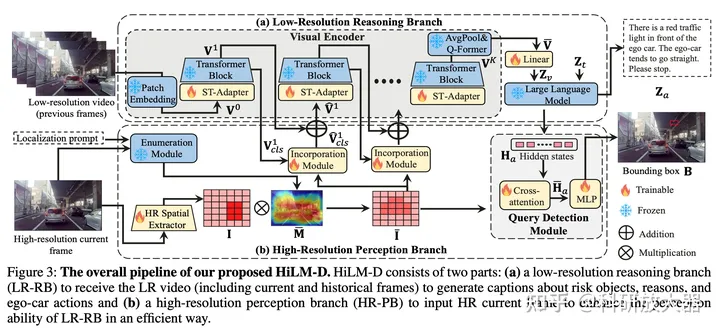
4.5 HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving,9.11
动机:对于非高清图片,目前预训练的多模态大模型往往会漏掉小目标、过分关注大目标(由于预训练数据为低分辨率图片)。本文感知关注的是关键风险目标,还输出预测和主车决策建议,
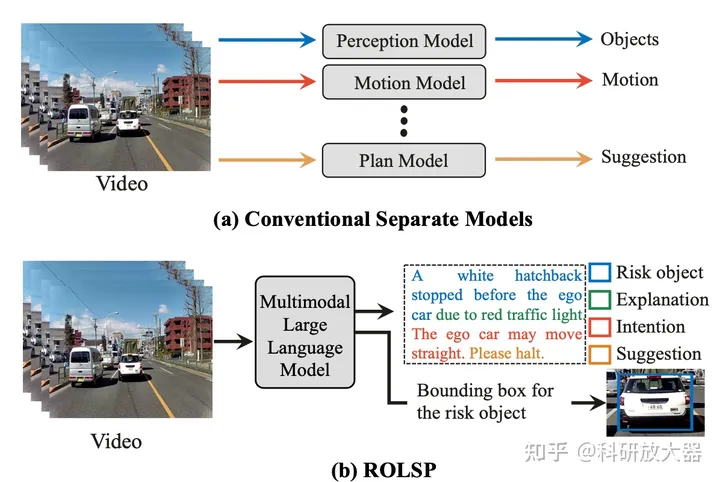
动机图
方案:提出了用高清图片分支辅助低分辨率分支,在23年CVPR的DRAMA数据集上进行了实验,包括关键风险目标的检测、预测目标意图和给出驾驶建议。
五、场景或数据生成
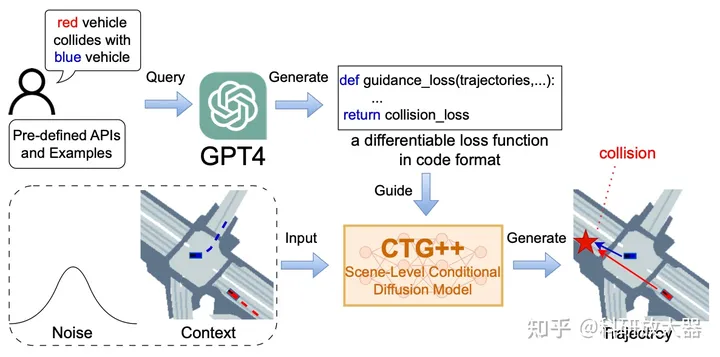
5.1 Language-Guided Traffic Simulation via Scene-Level Diffusion,Nvidia,CoRL, 2023
动机:基于语言表述生成openscenarios格式的场景
方案:利用GPT4产生引导loss,引导扩散模型来产生指定场景
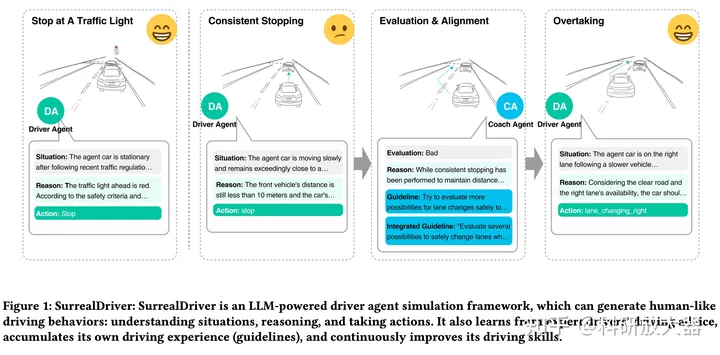
5.2 SurrealDriver: Designing Generative Driver Agent Simulation Framework in Urban Contexts based on Large Language Model,9.22
驾驶场景的可控生成,将会成为LLM的潜力方向。
5.3 WEDGE: A multi-weather autonomous driving dataset built from generative vision-language models,2023, CVPR workshop
动机:缓解OOD问题,利用DALL-E生成增广图片数据



























