可视化对于理解复杂的数据模式和关系至关重要。它们提供了一种简洁的方式来理解统计模型的复杂性、验证模型假设、评估模型性能等等。因此,了解数据科学中最重要和最有用的图表非常重要。
本文将带来数据科学家95%的时间都在使用的11个基本图表。
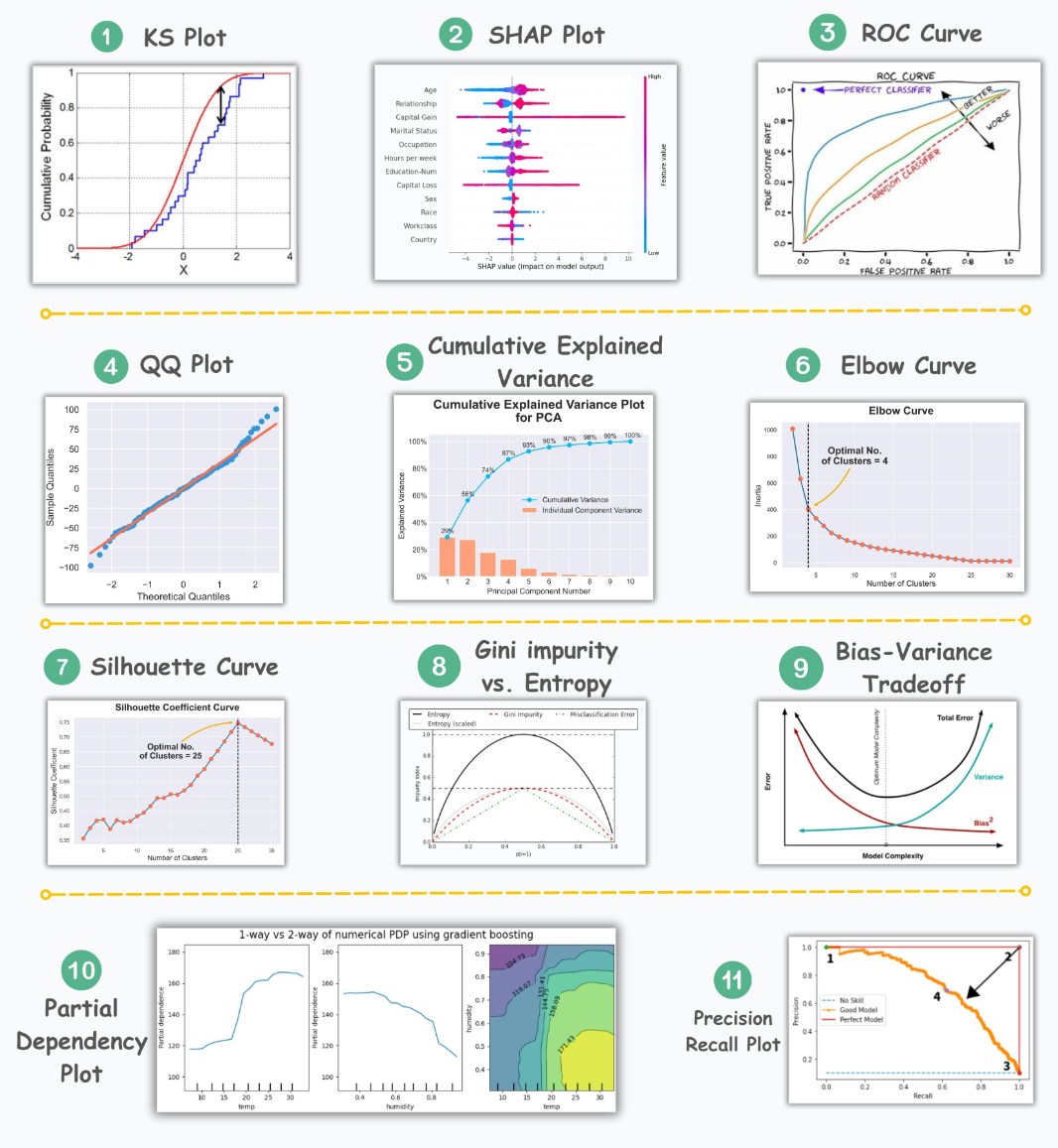
ROC Curve
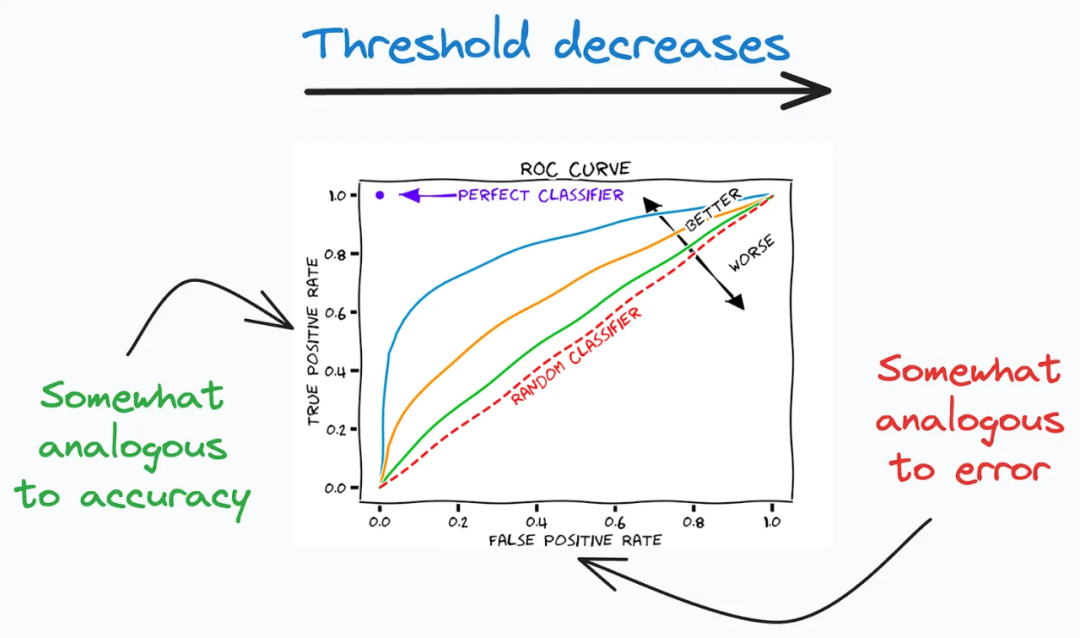
ROC曲线(Receiver Operating Characteristic Curve)描述了在不同分类阈值下,真阳性率(良好性能)与假阳性率(不良性能)之间的权衡关系。在二分类问题中,ROC曲线是一种常用的评估分类模型性能的工具。它绘制了在不同分类阈值下,分类器的真阳性率和假阳性率之间的关系。真阳性率是指被正确分类为正例的样本占所有实际正例样本的比例,假阳性率是指被错误分类为正例的负例样本占所有实际负例样本的比例。
ROC曲线的形状能够反映出分类器在不同阈值下的性能表现。一般情况下,ROC曲线越接近左上角,说明分类器的性能越好;而曲线越接近对角线,则表示分类器的性能越差。通过分析ROC曲线,可以选择适当的分类阈值,使得真阳性率尽可能高,同时保持较低的假阳性率,从而获得更准确的分类结果。
ROC曲线的目标是在真阳性率(良好性能)与假阳性率(不良性能)之间寻找平衡点。在分类问题中,我们希望尽可能提高真阳性率,即正确地将正例分类为正例,同时保持较低的假阳性率,即将负例误分类为正例的概率尽可能低。
Precision-Recall Curve
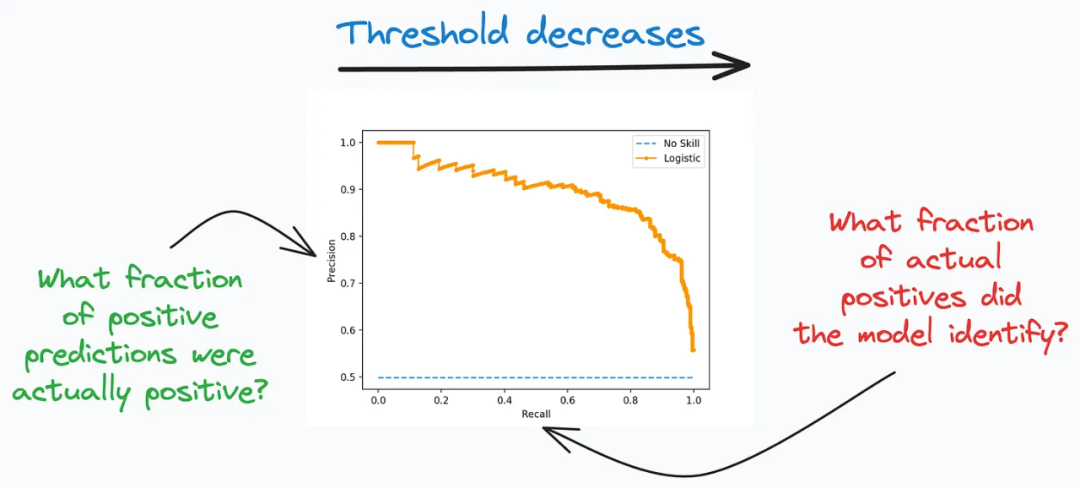
精确率-召回率曲线(Precision-Recall Curve)描述了在不同分类阈值下精确率和召回率之间的权衡关系。
在二分类问题中,精确率和召回率是常用的评估指标。精确率(Precision)是指被正确分类为正例的样本占所有被分类为正例的样本的比例。召回率(Recall)是指被正确分类为正例的样本占所有实际正例样本的比例。
精确率-召回率曲线通过绘制不同分类阈值下的精确率和召回率,展示了二者之间的权衡关系。通常情况下,当分类阈值较高时,模型更倾向于将样本分类为正例,从而提高精确率,但可能会降低召回率;而当分类阈值较低时,模型更倾向于将样本分类为正例,从而提高召回率,但可能会降低精确率。
通过分析精确率-召回率曲线,我们可以根据具体需求选择合适的分类阈值。
QQ Plot
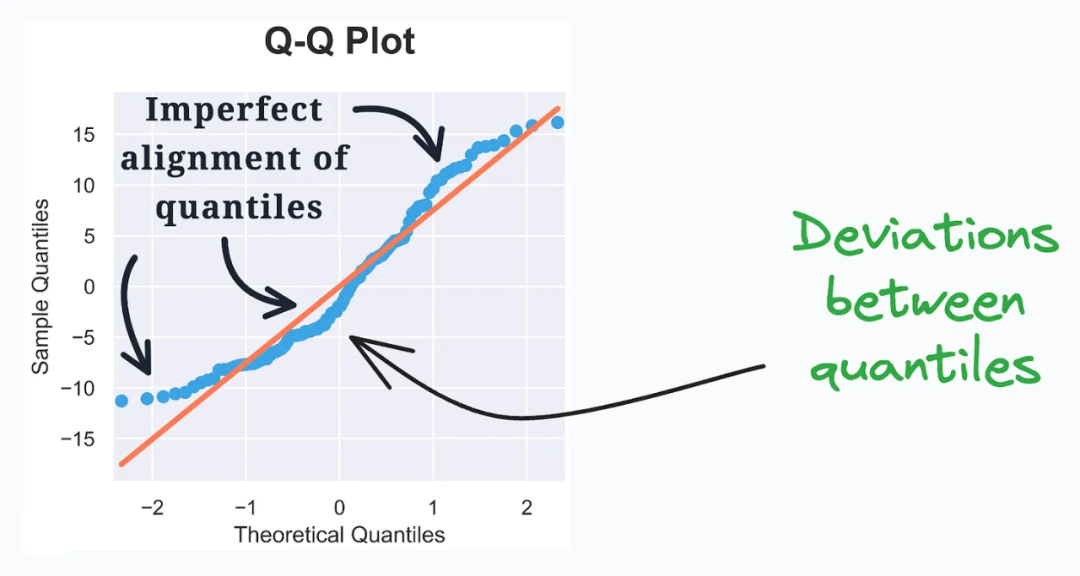
QQ图(QQ Plot)用于评估观测数据和理论分布之间的分布相似性。
QQ图通过绘制两个分布的分位数来比较它们之间的相似性。其中一个分布是观测数据的分布,另一个分布是理论上假设的分布,通常是一个已知的分布。
在QQ图中,横轴表示理论分布的分位数,纵轴表示观测数据的分位数。如果观测数据与理论分布完全相似,那么绘制的点将近似地落在一条直线上。
通过观察QQ图中的点的偏离程度,我们可以判断观测数据与理论分布之间的分布相似性。如果点的分布大致沿着一条直线,并且与理论分布的分位数一致,那么可以认为观测数据与理论分布较为相似。反之,如果点的分布明显偏离直线,就表示观测数据与理论分布存在差异。
KS Plot
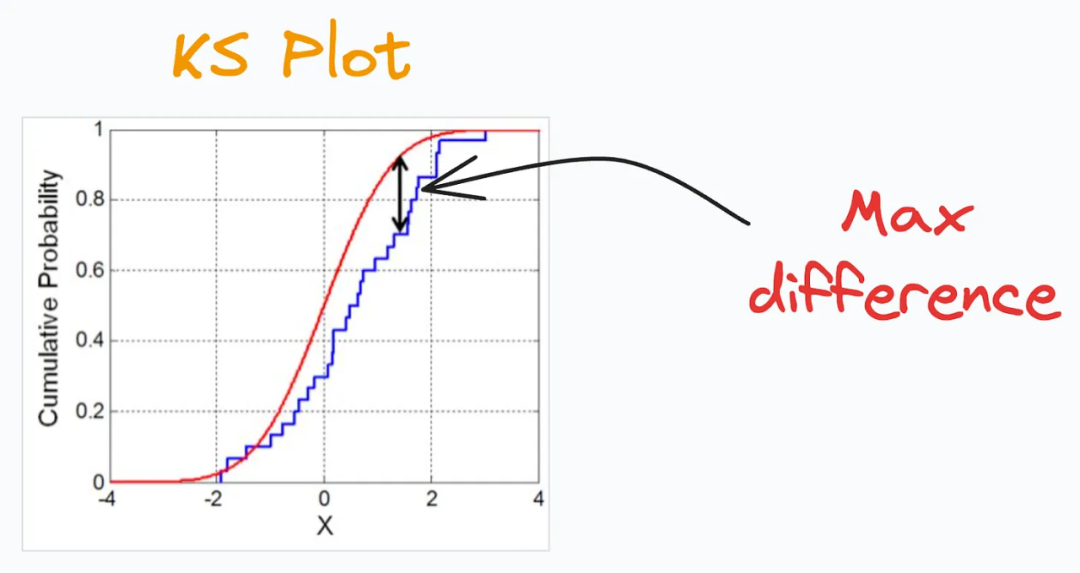
KS图(KS Plot)是一种用于评估分布差异的可视化工具。通过绘制KS图,我们可以直观地观察到两个分布之间的差异程度。通常情况下,KS图会显示两个CDF曲线之间的距离随着阈值的变化而变化的情况。当距离较小时,说明两个分布趋于接近,而当距离较大时,表示两个分布之间存在较大的差异。
因此,KS图也被定义为一种用于确定分布差异的“统计检验”。
SHAP Plot
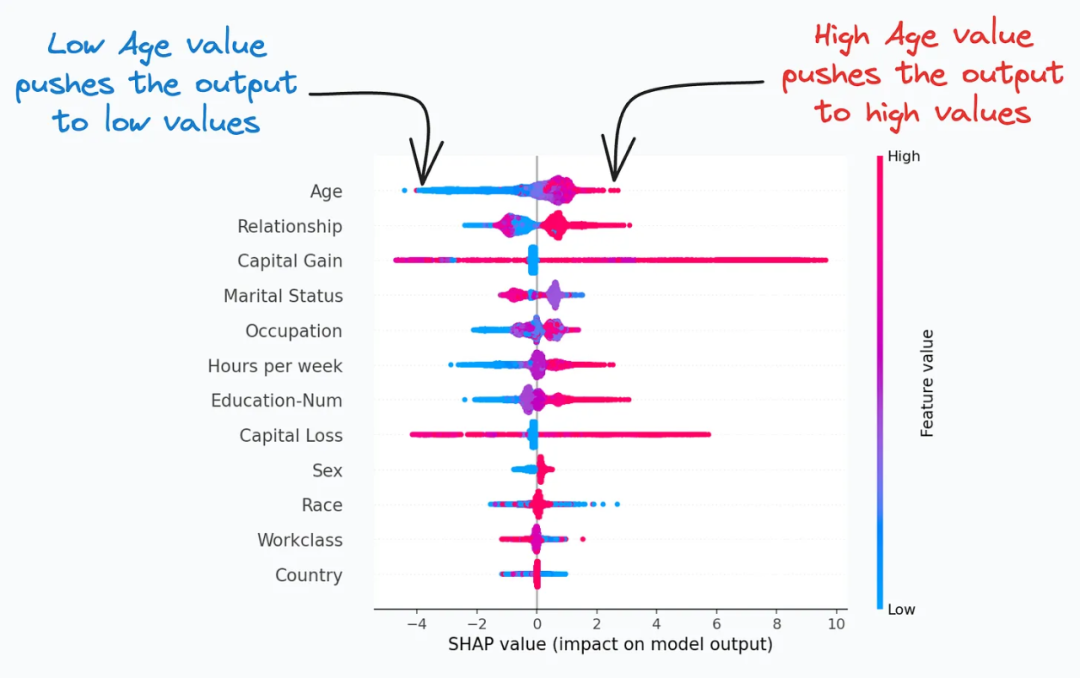
SHAP图(SHAP Plot)通过考虑特征之间的交互和依赖关系,总结了模型对预测的特征重要性。它是一种常用的可视化工具,用于解释机器学习模型的预测结果。
SHAP图基于博弈论的方法,解释模型对每个特征的贡献程度,展示了每个特征对模型预测结果的影响程度,以及特征值的高低如何影响整体输出结果。
Cumulative Explained Variance Plot
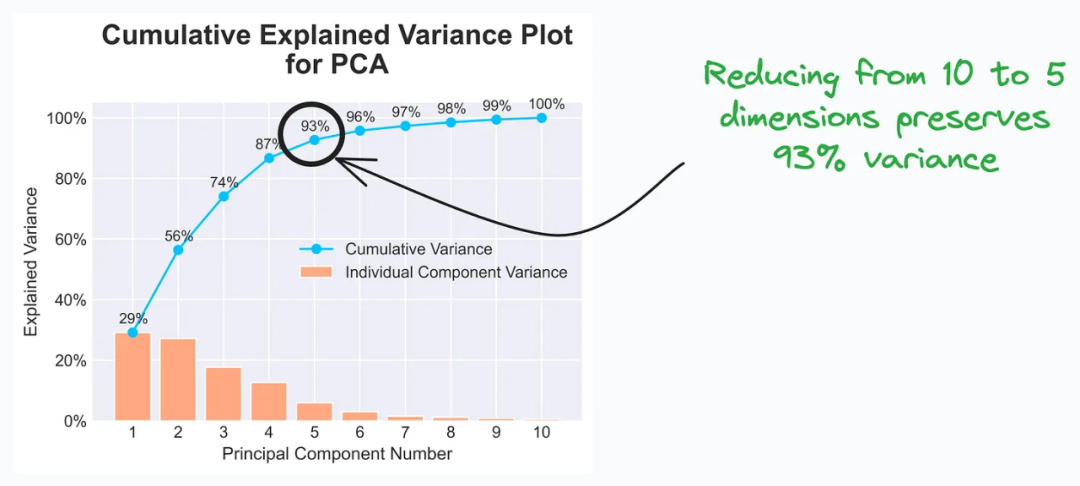
累计解释方差图(Cumulative Explained Variance Plot)有助于确定在主成分分析(PCA)过程中可以将数据缩减到的维度数,同时保留最大的方差。
在绘制累计解释方差图时,横轴表示主成分的数量,纵轴表示解释的方差的累积比例。通过观察图上的曲线,我们可以确定在保留足够的方差的前提下,可以将数据缩减到的维度数。
通常情况下,曲线开始的部分会很陡峭,表明前几个主成分解释了较大的方差。随着维度的增加,曲线的斜率逐渐变缓,表示新增的主成分对方差的贡献较小。
通过观察累计解释方差图,我们可以选择保留累积方差较大部分的主成分数量作为数据降维的目标维度数。一般来说,我们会选择保留累计方差达到一定阈值(例如93%)的主成分数量,以保留尽可能多的信息。
Elbow Curve
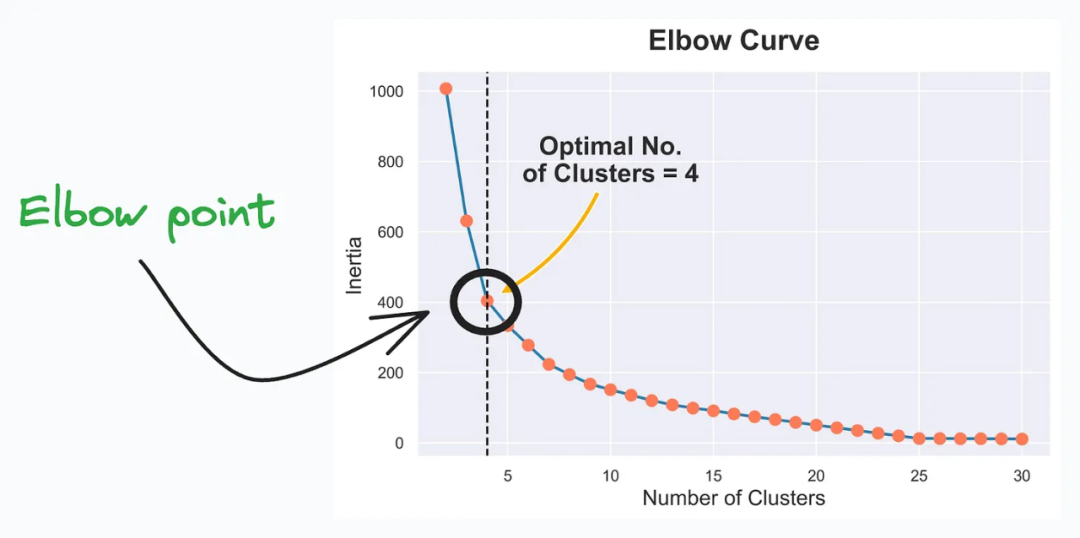
肘部曲线(Elbow Curve)有助于确定k均值算法的最佳簇数。
肘部曲线通过绘制不同k值下的簇内平方和(Within-Cluster Sum of Squares,WCSS)的变化情况来评估聚类的效果。WCSS表示每个数据点与其所属簇中心之间的距离的平方和。肘部曲线的横轴表示k值,纵轴表示WCSS。
当k值较小时,每个簇中的数据点与簇中心的距离通常较小,WCSS较低。随着k值的增加,每个簇中的数据点与簇中心的距离可能会增加,导致WCSS增加。当k值增加到一定程度时,每个额外的簇可能只会为数据点添加很少的附加信息,而WCSS的改进幅度会减小。
肘部曲线的核心思想是选择WCSS变化率陡降的点,通常是曲线出现“拐点”或形成“肘部”的位置。这个点所对应的k值被认为是最佳簇数。
Silhouette Curve
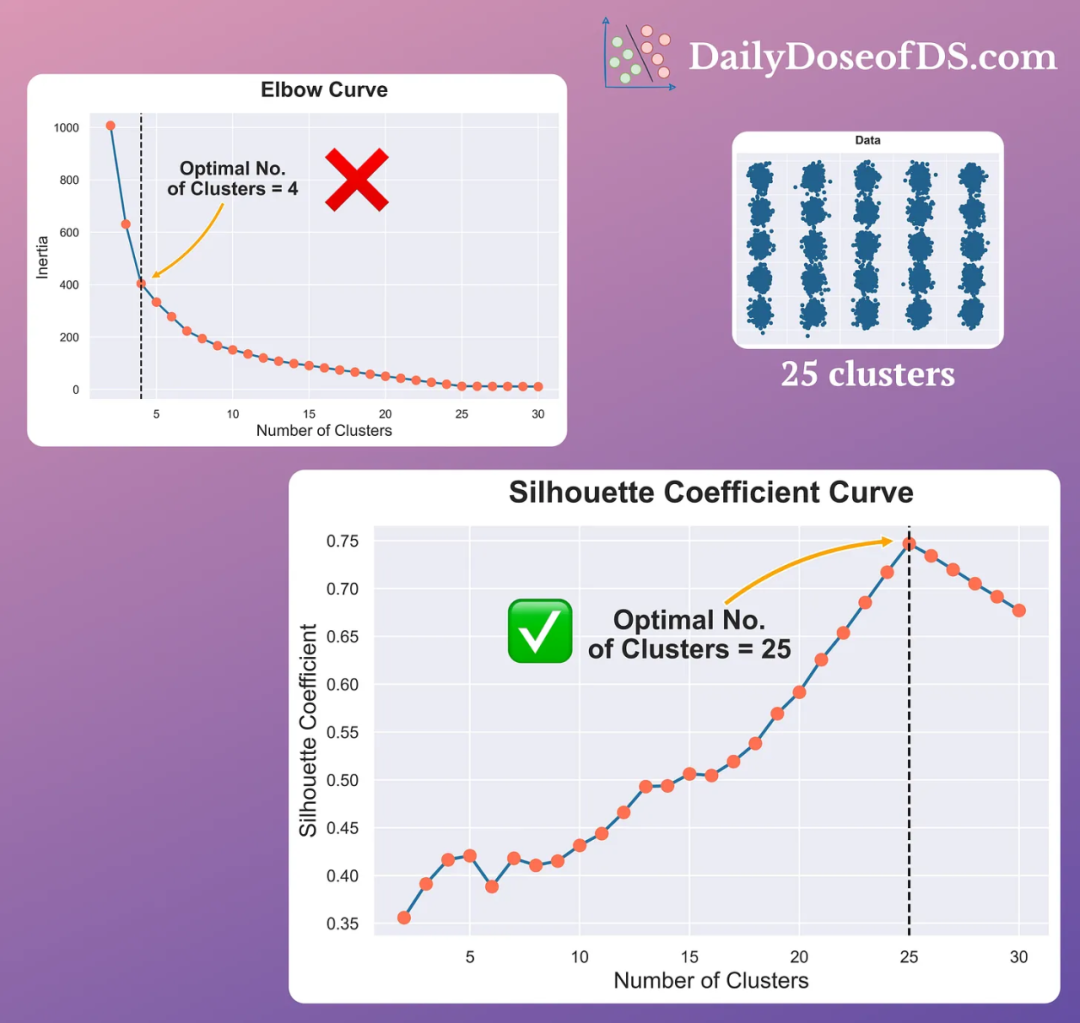
轮廓曲线(Silhouette Curve)通过绘制不同簇数下的轮廓系数来评估聚类的效果。轮廓系数的取值范围为[-1,1],其中较高的值表示样本在其所属簇中更紧密,且与其他簇之间的分离度更高。
通过观察轮廓曲线,我们可以找到轮廓系数最大的点,这个点对应的簇数即为最佳簇数。当轮廓系数达到最大值时,表示聚类效果较好,样本在其所属簇中更紧密,并且与其他簇之间的分离度更高。
相比于肘部曲线,在有大量簇的情况下,轮廓曲线通常更有效。它能够更准确地评估聚类质量,并帮助我们选择最佳的簇数。
Gini-Impurity and Entropy
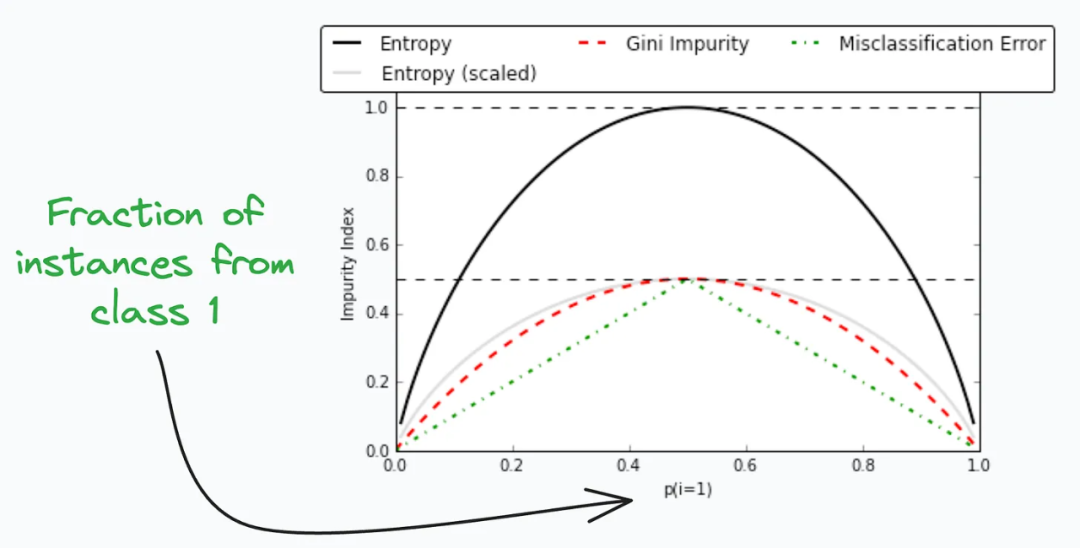
基尼不纯度和熵(Gini-Impurity and Entropy)是用于衡量数据集的混乱程度或不确定性的指标。基尼不纯度的计算基于每个类别在数据集中的比例,如果数据集完全由同一类别组成,则基尼不纯度为0。 熵的计算基于每个类别在数据集中的比例,如果数据集中的每个类别都均匀分布,则熵最大。
在决策树的构建过程中,我们可以根据基尼不纯度或熵来选择最佳的分割点。当基尼不纯度或熵越低时,表示分割点能够更好地将数据集分成纯净的子集,这样的分割点通常被认为是更好的选择。然而,基尼不纯度和熵之间存在一种权衡关系,选择哪种指标取决于具体的应用和数据集特征。
Bias-Variance Tradeoff
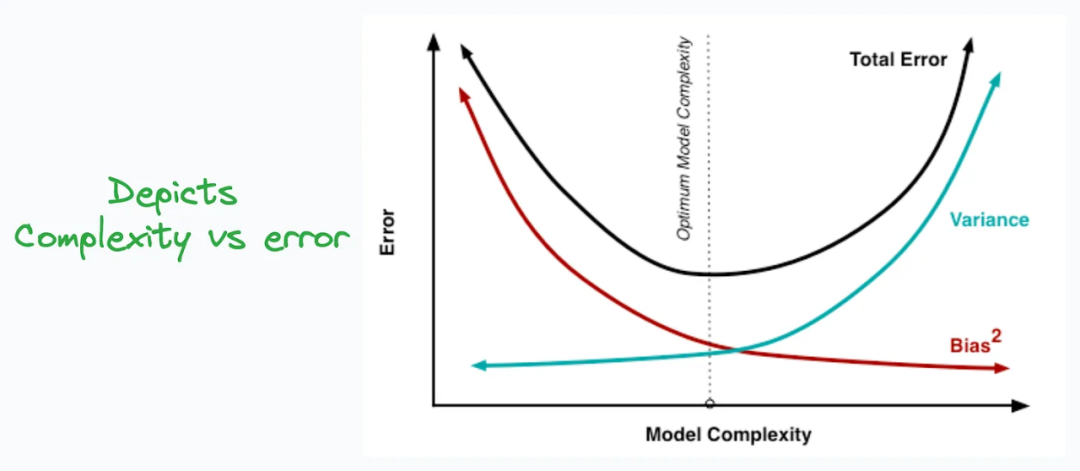
Bias-variance tradeoff是在模型复杂性与偏差和方差之间寻找合适平衡的概念。
在机器学习中,模型的偏差(bias)是指模型在训练集上的预测结果与真实值的偏离程度。偏差较高意味着模型对训练集的拟合不足,无法捕捉到数据中的复杂关系,导致欠拟合。
而方差(variance)是指模型在不同训练集上的预测结果的变化程度。方差较高意味着模型过于敏感于训练集的细节,过度拟合了训练集的噪声和随机性,导致泛化能力较差。
在模型的复杂性方面,较简单的模型通常具有较高的偏差和较低的方差,而较复杂的模型通常具有较低的偏差和较高的方差。
Bias-variance tradeoff的目标是找到适当的模型复杂性,以在偏差和方差之间取得平衡。如果模型过于简单,偏差会很高,而方差较低;如果模型过于复杂,偏差会较低,但方差会较高。为了获得较好的泛化性能,我们需要在这两者之间找到一个合适的平衡点。
Partial Dependency Plots
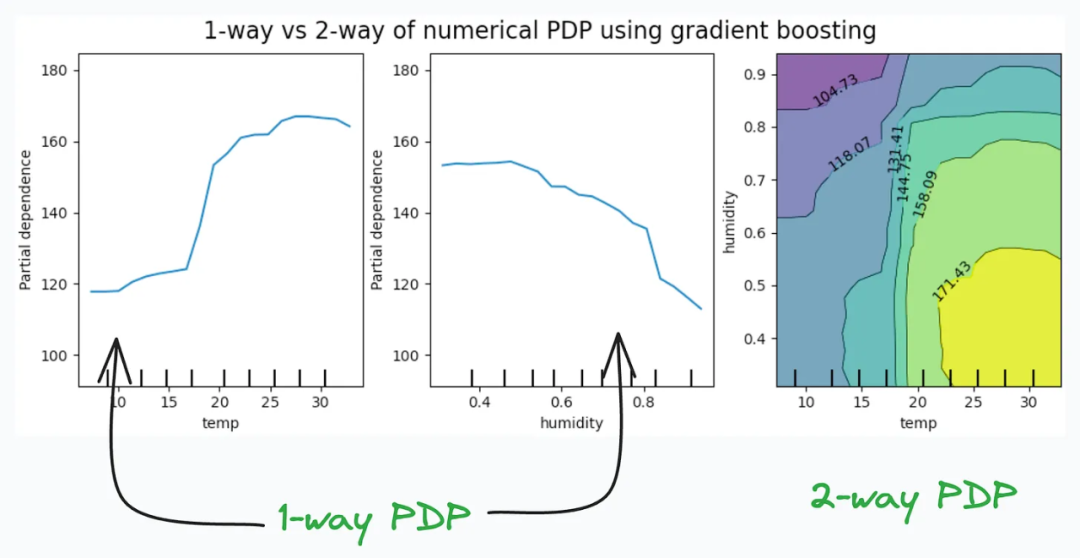
Partial Dependency Plots用于描述目标变量和特征之间的依赖关系。
一维图(1-way PDP)显示了目标变量与一个特征之间的关系。通过这个图可以看出,当某个特征的取值发生变化时,目标变量的取值如何相应地变化。
二维图(2-way PDP)显示了目标变量与两个特征之间的关系。通过这个图可以观察到,当两个特征的取值同时变化时,目标变量的取值如何相应地变化。
在最左边的图中,温度的增加通常会导致目标值较高。这表示温度对目标变量有正向影响,也就是说,当温度增加时,目标值往往会增加。