前几日,阿里研究团队构建了一种名为 Animate Anyone 的方法,只需要一张人物照片,再配合骨骼动画引导,就能生成自然的动画视频。不过,这项研究的源代码还没有发布。
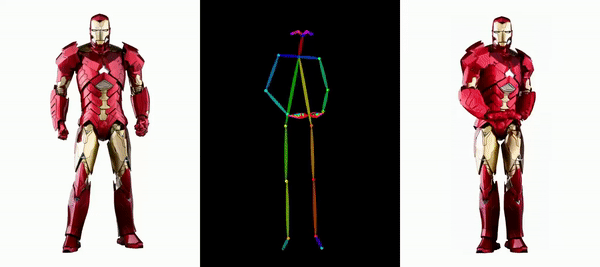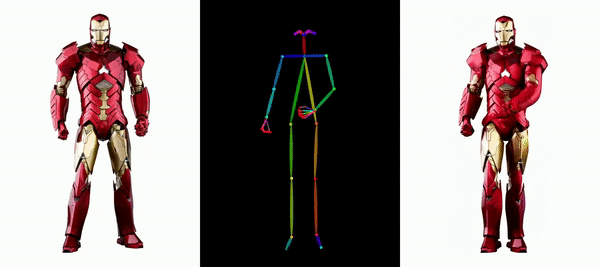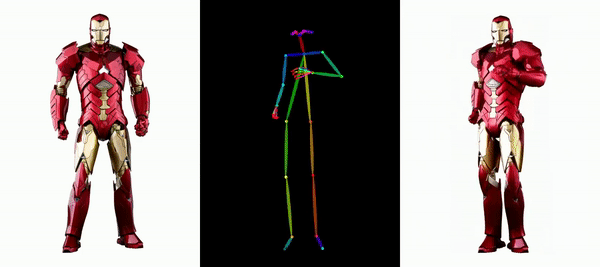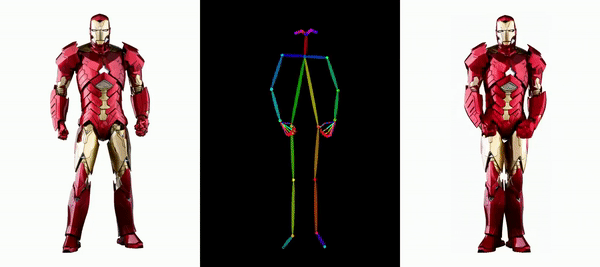
让钢铁侠动起来。
其实在 Animate Anyone 这篇论文出现在 arXiv 上的前一天,新加坡国立大学 Show 实验室和字节联合做了一项类似的研究。他们提出了一个基于扩散的框架 MagicAnimate,旨在增强时间一致性、忠实地保留参考图像并提升动画保真度。并且,MagicAnimate 项目是开源的,目前推理代码和 gradio 在线 demo 已经发布。

- 论文地址:https://arxiv.org/pdf/2311.16498.pdf
- 项目地址:https://showlab.github.io/magicanimate/
- GitHub 地址:https://github.com/magic-research/magic-animate
为了实现上述目标,研究者首先开发了一个视频扩散模型来编码时间信息。接着为了保持跨帧的外观连贯性,他们引入了新颖的外观编码器来保留参考图像的复杂细节。利用这两个创新,研究者进一步使用简单的视频融合技术来保证长视频动画的平滑过渡。
实验结果表明,MagicAnimate 在两项基准测试上均优于基线方法。尤其在具有挑战性的 TikTok 跳舞数据集上,本文方法在视频保真度方面比最强基线方法高出 38%以上。
我们来看以下几个 TikTok 小姐姐的动态展示效果。



除了跳舞的 TikTok 小姐姐之外,还有「跑起来」的神奇女侠。

戴珍珠耳环的少女、蒙娜丽莎都做起了瑜伽。


除了单人,多人跳舞也能搞定。


与其他方法比较,效果高下立判。

还有国外网友在HuggingFace上创建了一个试用空间,创建一个动画视频只要几分钟。不过这个网站已经404了。

图源:https://twitter.com/gijigae/status/1731832513595953365

接下来介绍 MagicAnimate 的方法和实验结果。
方法概览
给定参考图像 I_ref 和运动序列 ,其中 N 是帧数。MagicAnimate 旨在合成连续视频
,其中 N 是帧数。MagicAnimate 旨在合成连续视频
 。其中出现画面 I_ref,同时遵循运动序列
。其中出现画面 I_ref,同时遵循运动序列 。现有基于扩散模型的框架独立处理每个帧,忽略了帧之间的时间一致性,从而导致生成的动画存在「闪烁」问题。
。现有基于扩散模型的框架独立处理每个帧,忽略了帧之间的时间一致性,从而导致生成的动画存在「闪烁」问题。
为了解决该问题,该研究通过将时间注意力(temporal attention)块合并到扩散主干网络中,来构建用于时间建模的视频扩散模型 。
。
此外,现有工作使用 CLIP 编码器对参考图像进行编码,但该研究认为这种方法无法捕获复杂细节。因此,该研究提出了一种新型外观编码器(appearance encoder) ,将 I_ref 编码到外观嵌入 y_a 中,并以此为基础对模型进行调整。
,将 I_ref 编码到外观嵌入 y_a 中,并以此为基础对模型进行调整。
MagicAnimate 的整体流程如下图 2 所示,首先使用外观编码器将参考图像嵌入到外观嵌入中,然后再将目标姿态序列传递到姿态 ControlNet 中,以提取运动条件
中,以提取运动条件 。
。

在实践中,由于内存限制,MagicAnimate 以分段的方式处理整个视频。得益于时间建模和强大的外观编码,MagicAnimate 可以在很大程度上保持片段之间的时间和外观一致性。但各部分之间仍然存在细微的不连续性,为了缓解这种情况,研究团队利用简单的视频融合方法来提高过渡平滑度。
如图 2 所示,MagicAnimate 将整个视频分解为重叠的片段,并简单地对重叠帧的预测进行平均。最后,该研究还引入图像 - 视频联合训练策略,以进一步增强参考图像保留能力和单帧保真度。
实验及结果
实验部分,研究者在两个数据集评估了 MagicAnimate 的性能,分别是 TikTok 和 TED-talks。其中 TikTok 数据集包含了 350 个跳舞视频,TED-talks 包含 1,203 个提取自 YouTube 上 TED 演讲视频的片段。
首先看定量结果。下表 1 展示了两个数据集上 MagicAnimate 与基线方法的定量结果比较,其中表 1a 显示在 TikTok 数据集上,本文方法在 L1、PSNR、SSIM 和 LPIPS 等重建指标上超越了所有基线方法。
表 1b 显示在 TED-talks 数据集上,MagicAnimate 在视频保真度方面也更好,取得了最好的 FID-VID 分数(19.00)和 FVD 分数(131.51)。

再看定性结果。研究者在下图 3 展示了 MagicAnimate 与其他基线方法的定性比较。本文方法实现了更好的保真度,展现了更强的背景保留能力, 这要归功于从参考图像中提取细节信息的外观编码器。

研究者还评估了 MagicAnimate 的跨身份动画(Cross-identity animation),以及与 SOTA 基线方法的比较,即 DisCo 和 MRAA。具体来讲,他们从 TikTok 测试集中采样了两个 DensePose 运动序列,并使用这些序列对其他视频的参考图像进行动画处理。
下图 1 显示出 MRAA 无法泛化到包含大量不同姿态的驱动视频,而 DisCo 难以保留参考图像的细节。相比之下,本文方法忠实地为给定目标运动的参考图像设置动画,展示了其稳健性。

最后是消融实验。为了验证 MagicAnimate 中设计选择的有效性,研究者在 TikTok 数据集上进行了消融实验,包括下表 2 和下图 4 中有无时间建模、外观编码器、推理阶段视频融合以及图像 - 视频联合训练等。


MagicAnimate 的应用前景也很广。研究者表示,尽管仅接受了真实人类数据的训练,但它展现出了泛化到各种应用场景的能力,包括对未见过的领域数据进行动画处理、与文本 - 图像扩散模型的集成以及多人动画等。

更多细节请阅读原论文。