论文"NeuRAD: Neural Rendering for Autonomous Driving",来自Zenseact,Chalmers科技大学,Linkoping大学和Lund大学。
 神经辐射场(NeRF)在自动驾驶(AD)社区中越来越受欢迎。最近的方法显示了NeRFs在闭环模拟、AD系统测试和训练数据增强技术方面的潜力。然而,现有的方法往往需要长的训练时间、密集的语义监督,缺乏可推广性。这反过来又阻碍了NeRF在AD中的大规模应用。本文提出NeuRAD,一种针对动态AD数据的稳健的新视图合成方法。该方法具有简单的网络设计、包括相机和激光雷达的传感器建模(包括滚动快门、光束发散和光线降落),适用于开箱即用的多个数据集。
神经辐射场(NeRF)在自动驾驶(AD)社区中越来越受欢迎。最近的方法显示了NeRFs在闭环模拟、AD系统测试和训练数据增强技术方面的潜力。然而,现有的方法往往需要长的训练时间、密集的语义监督,缺乏可推广性。这反过来又阻碍了NeRF在AD中的大规模应用。本文提出NeuRAD,一种针对动态AD数据的稳健的新视图合成方法。该方法具有简单的网络设计、包括相机和激光雷达的传感器建模(包括滚动快门、光束发散和光线降落),适用于开箱即用的多个数据集。
如图所示:NeuRAD是一种为动态汽车场景量身定制的神经渲染方法。可以改变自车和其他道路使用者的姿态,也可以自由添加和/或移除参与者。这些功能使NeuRAD适合作为传感器逼真的闭环模拟器或强大数据增强引擎等组件的基础。
 本文目标是学习一种表示,从中可以生成真实的传感器数据,其中可以改变自车平台、行动者的姿态,或者两者兼而有之。假设可以访问由移动平台收集的数据,由设定的相机图像和激光雷达点云组成,以及对任何移动行动者大小和姿态的估计。为了实用性,该方法需要在主要汽车数据集上的重建误差方面表现良好,同时将训练和推理时间保持在最低限度。
本文目标是学习一种表示,从中可以生成真实的传感器数据,其中可以改变自车平台、行动者的姿态,或者两者兼而有之。假设可以访问由移动平台收集的数据,由设定的相机图像和激光雷达点云组成,以及对任何移动行动者大小和姿态的估计。为了实用性,该方法需要在主要汽车数据集上的重建误差方面表现良好,同时将训练和推理时间保持在最低限度。
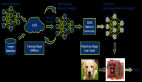
如图是本文提出方法NeuRAD的概览:学习一个用于汽车场景的静态和动态的联合神经特征场,通过行动者-觉察的哈希编码来区分。落入行动者边框内的点被转换为行动者局部坐标,并与行动者索引一起用于查询4D哈希网格。用上采样CNN将体渲染的光线级特征解码为RGB值,并用MLP将其解码为光线降落概率和强度。
 在新视图合成[4,47]的工作基础上,作者用神经特征场(NFF)、NeRFs[25]的推广和类似方法[23]对世界进行建模。
在新视图合成[4,47]的工作基础上,作者用神经特征场(NFF)、NeRFs[25]的推广和类似方法[23]对世界进行建模。
为了渲染图像,对一组相机射线进行体渲染,生成特征图F。如[47]所示,然后依靠CNN来渲染最终图像。在实践中,特征图的分辨率低于图像,并且用CNN进行上采样。这样能够大幅减少查询的光线数量。
激光雷达传感器允许自动驾驶车辆测量一组离散点的深度和反射率(强度)。他们通过发射激光束脉冲和测量飞行时间来确定距离和反射率的返回功率。为了捕捉这些特性,将来自姿态激光雷达传感器的传输脉冲建模为一组射线,并使用类似体渲染技术。
考虑不返回任何点的激光束射线。如果返回功率过低,就会出现一种现象,称为射线降落,这对于减少模拟-实际差别的建模非常重要[21]。通常,这样的光线传播得很远而不会碰到表面,或者碰到光束反弹到空地上的表面,例如镜子、玻璃或潮湿的路面。对这些影响进行建模对于传感器真实模拟很重要,但如[14]所述,很难完全基于物理来捕捉,因为它们依赖于(通常未公开的)低层传感器检测逻辑的细节。因此,选择从数据中学习光线降落。与强度类似,可体渲染光线特征,并将其通过一个小MLP来预测光线下降概率pd(r)。请注意,与[14]不同的是,不对激光雷达光束的二次回波进行建模,因为实验中五个数据集中不存在此信息。
将神经特征场(NFF)的定义扩展为学习函数(s,f)=NFF(x,t,d),其中x是空间坐标,t表示时间,d表示视角方向。重要的是,该定义引入了时间作为输入,这对于场景的动态方面建模至关重要。
神经架构
NFF架构遵循NeRF[4,27]中公认的最佳方法。给定位置x和时间t,查询行动者-觉察哈希编码。然后,这种编码输入到一个小MLP中,该感知器计算有符号距离s和中间特征g。用球谐波[27]对视图方向d进行编码,使模型能够捕捉反射和其他与视图相关的效果。最后,通过第二个MLP联合处理方向编码和中间特征,用g的跳跃连接来增强,从而产生特征f。
场景构成
与之前的工作[18,29,46,47]类似,将世界分解为两个部分,静态背景和一组刚性动态行动者,每个行动者由一个3D边框和一组SO(3)姿态定义。提供双重目的:简化学习过程,并允许一定程度的可编辑性,在训练后可以动态行动者生成新场景。与之前不同场景元素使用单独NFF的方法不同,本文用一个单个统一NFF,其中所有网络都是共享的,静态和动态组件之间的区别由行动者-觉察的哈希编码透明处理。编码策略很简单:根据给定样本(x,t)是否位于行动者边框内,用两个函数中的一个对其进行编码。
无界静态场景
用多分辨率哈希网格[27]表示静态场景,因为这已被证明是一种高度表达和高效的表示。然而,为了将无界场景映射到网格上,采用MipNerf-360[3]中提出的收缩方法。这能够用单个哈希网格准确地表示附近的道路元素和远处的云。相比之下,现有的方法利用专用的NFF来捕捉天空和其他遥远的区域[47]。
刚性动态行动者
当样本(x,t)落在行动者的边框内时,其空间坐标x和视角方向d在给定时间t转换到行动者的坐标系。忽略之后的时间方面,并从与时间无关的多分辨率哈希网格中采样特征,就像静态场景一样。简单地说,需要分别对多个不同的哈希网格进行采样,每个行动者是一个。然而,转而使用单个4D哈希网格,其中第四个维度对应于行动者索引。这种方法允许并行地对所有行动者特征进行采样,在匹配单独哈希网格性能的同时实现显著的加速。
多尺度场景问题
将神经渲染应用于汽车数据的最大挑战之一是处理这些数据中存在的多个细节级。当车辆行驶很长距离时,无论是从远处还是近距离都可以看到许多表面。在这些多尺度设置中天真地应用iNGP[27]或NeRF的位置嵌入会导致混叠伪影[2]。为了解决这一问题,许多方法将射线建模为截锥体,截锥体纵向由bin的大小决定,径向由像素面积以及与传感器的距离决定[2,3,13]。
Zip-NeRF[4]是目前iNGP哈希网格的唯一抗混叠(anti-aliasing)方法,它结合了两种截头体建模技术:多采样和降低权重。在多采样中,对截头体多个位置的位置嵌入进行平均,捕捉纵向和径向范围。对于降低权重,每个样本都被建模为各向同性高斯,网格特征的权重与单元(cell)大小和高斯方差之间比例成比,从而有效地抑制更精细的分辨率。虽然组合技术显著提高了性能,但多重采样也显著增加了运行时间。所以本文目标是以最小的运行影响结合规模信息。受Zip-NeRF的启发,作者提出了一种直观的降低权重方案,根据哈希网格特征相对于截头体的大小对其进行权重降低。
高效采样
渲染大规模场景的另一个困难是需要高效的采样策略。在一张图像中,可能想在附近的交通标志上渲染详细的文本,同时捕捉几公里外摩天大楼之间的视差效果。为了实现这两个目标,对射线进行均匀采样将需要每条射线数千个样本,这在计算上是不可行的。以前的工作在很大程度上依赖激光雷达数据来修剪样本[47],因此很难在激光雷达的工作之外进行渲染。
相反,本文根据幂函数[4]沿射线渲染样本,使得样本之间的空间随着与射线原点的距离而增加。即便如此,不可能在样本数量急剧增加的情况下满足所有相关条件。因此,还采用两轮的提议采样(proposal sampling)[25],其中查询NFF(neural feature field)的轻量级版本,生成沿射线的权重分布。然后,根据这些权重渲染一组新的样本。经过两轮这个过程后,得到了一组精细的样本,这些样本集中在射线上的相关位置,可以用来查询全尺寸NFF。为了监督所提出的网络,采用了一种抗混叠的在线蒸馏方法[4],并进一步使用激光雷达进行监督。
建模滚动快门
在基于NeRF的标准公式中,假设每个图像都是从一个原点o捕获的。然而,许多相机传感器都有滚动快门,即像素行是按顺序捕获的。因此,相机传感器可以在第一行的捕获和最后一行的捕获之间移动,打破了单一原点的假设。虽然合成数据[24]或慢速手持相机拍摄的数据不是问题,但滚动快门在快速移动车辆的拍摄中变得明显,尤其是侧面相机。同样的影响也存在于激光雷达中,每次扫描通常在0.1s内收集,当以高速公路速度行驶时,这相当于几米移动。即使对于自我运动补偿的点云,这些差异也可能导致有害的视线误差,即3D点转化为穿过其他几何的射线。为了减轻这些影响,为每条光线指定单独的时间并根据估计的运动调整其原点,这样对滚动快门进行建模。由于滚动快门会影响场景的所有动态元素,因此会对每个单独的光线时间,行动者姿态做线性插值。
不同的相机设置
模拟自动驾驶序列时的另一个问题是,图像来自不同的相机,具有潜在的不同捕获参数,如曝光。在这里,从“NeRFs in the wild”[22]的研究中获得了灵感,其中为每个图像学习外观嵌入,并与其特征一起传递到第二个MLP。然而,当知道哪个图像来自哪个传感器时,反而为每个传感器学习单个嵌入,从而最大限度地减少过拟合的可能性,并允许在生成新视图时使用这些传感器嵌入。当渲染特征而不是颜色时,在体渲染后应用这些嵌入,显著减少了计算开销。
含噪的行动者姿态
模型依赖于对动态行动者姿态的估计,无论其是以注释的形式还是作为跟踪输出。为了解决缺陷,将行动者姿态作为可学习的参数纳入模型中,并对其进行联合优化。姿态参数化为平移t和旋转R,用6D-表示[50]。
注:NeuRAD是在开源项目Nerfstudio[33]中实现的。用Adam[17]optimizer训练方法,进行20000次迭代。使用一台英伟达A100,训练大约需要1个小时。
复现UniSim:UniSim[47]是一种神经闭环传感器模拟器。它具有逼真的渲染效果,对可用的监督几乎没有任何假设,即它只需要相机图像、激光雷达点云、传感器姿态和带有动态行动者轨迹的3D边框。这些特性使UniSim成为一个合适的基线,因为它很容易应用于新自动驾驶数据集。然而,该代码是封闭源代码,也没有非官方的实现。因此,本文选择重新实现UniSim,作为自己的模型,在Nerfstudio[33]中这样实现。由于UniSim的主要文章没有详细说明许多模型细节,只能依赖于IEEE Xplore提供的补充材料。尽管如此,一些细节仍然是未知的,作者已经调整了这些超参数,匹配10个选定PandaSet[45]序列的报告性能。