一、前言
应用连接数据库基本上都是通过连接池去连接,比如常用的 HikariCP、Druid 等,在应用运行期间经常会出现获取连接很慢的场景,大多数同学都是一头雾水,不知道从哪下手。而且很多时候都是偶发场景,让人头疼不已,别着急,本文带你逐步剖析获取连接慢的所有可能的原因,以及对应的调优手段,让你成为连接池排障大师。
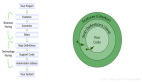
二、连接池监控
排查问题的前提是发现问题,所以首先需要有连接池的详细监控,下面我们以 HikariCP 为例,简单介绍几个常用的指标的含义。
 图片
图片
 图片
图片
 图片
图片
对应应用程序比较敏感的时间就是获取连接耗时,因为它是同步的会直接影响链路的RT,下面我们就来逐步分析造成这个获取连接耗时较高的所有可能性以及解决方案。
三、排查思路
连接池存在等待连接
获取连接耗时较高最直接的原因就是存在等待连接数,这种情况直接观测等待连接数的大盘即可
 图片
图片
那么又有哪几种情况会导致存在等待连接数呢?
- 连接池容量过小
如果日常的活跃连接数/总连接比例持续很高,或者 QPS * AVG-RT(s) > 连接总数说明当前连接池的最大连接数已经不足以支撑当前的流量,如何解决?
适当增加连接池最大连接数:连接数也不是越大越好,一般是根据 CPU 核数决定,HikariCP 官方给出了一个公式可以做一下参考,最大连接数一般不要超过 50。
core_count 为core的数量 effective_spindle_count 为挂载的磁盘数量。core_count 为core的数量 effective_spindle_count 为挂载的磁盘数量。- 应用扩容:如果连接数调大后,仍然无法解决,说明单机的连接数已经达到上限,需要对应用进行扩容,但是需要注意扩容节点的数量,单机连接数*节点数量不要超过数据库支持的最大连接数
有慢查询&长事务
- 慢SQL
慢 SQL 相对来说比较好排查,数据库或者数据库中间件都有成熟的慢 SQL 采集工具。只需要分析一下指定时间段内是否有慢 SQL 即可。 如果SQL 优化空间比较低,可以把慢 SQL 和核心业务分 2 个数据源,防止慢 SQL 影响正常核心业务。
- 长事务
长事务是很容易忽略的一种 case,可以通过观测连接使用时间指标和 SQL 耗时来分析,如果连接使用平均耗时远大于 SQL 平均耗时,那么说明有长事务。还可以根据 HikariCP 自带的连接泄露检测来分析,当连接被借出后长时间未归还(超过配置的阈值 leak-detection-threshold=30000)会打印借出时的堆栈,可以帮助我们快速定位。
 图片
图片
还可以通过 RDS 的 SQL 洞察来分析是否有长事务,如果使用 Spring+JDBC 管理事务的情况下,开启事务的命令是 SET autocommit=0,提交事务是 commit,这里根据数据库线程 ID 来逐个分析,提交事务的时间-开启事务的时间=事务持续时间。

应用负载过高
由于 HikariCP、Druid 在从连接池借出连接时,会有一个同步探活的操作,比如直接 MySQL 的 PING 命令或执行 select 'X' 等,因为有网络 IO,所以这里会让当前线程进入阻塞状态让出 CPU 时间片。
 图片
图片
在 CPU 繁忙时,执行完网络 IO 后等待获取 CPU 时间片的时间较长,最终表现的结果就是获取连接时间拉长。这种 case 的分析手段比较简单,直接通过观测应用的 CPU 和 Load 指标即可。
应用STW
在获取连接方法开始到结束期间,如果应用发生了 STW,就会导致获取连接耗时升高,需要结合 JVM 监控 &GC 日志来分析,关于 GC 分析不是本文重点,这里简单列举几个重点说明一下(以 ZGC 举例)。
- JVM 监控存在 Allocation Stall(垃圾回收阻塞,会暂停线程)或者暂停时间较长。
 图片
图片
 图片
图片
- GC 日志相对于监控会更为准确一点,把日志文件直接丢到 https://gceasy.ycrash.cn/ 里面分析一下即可,会输出详细的报告,重点关注一下 STW 时间和分配阻塞。
 图片
图片
 图片
图片
网络阻塞
这一类问题比较难以排查,具有偶发性和难以观测的特点,网络阻塞也分好几种情况。
- 网络抖动
这是最常见的一种情况,一般我们可以通过观测应用所在主机的 TCP 重传监控是否有尖刺,但这里要注意下,TCP 重传不代表一定是网络抖动,也可能是网络带宽打满或者数据库 &DAL 异常。
 图片
图片
除了监控还可以通过网络循环抓包来分析(主要磁盘容量不要保留太多文件),可以参考以下命令。
抓取 3306 端口的网络包,存储到 3306.pcap 文件中,-C 50 -W 10 代表一个文件最大 50M,最多保留 10 个 tcpdump -i eth0 port 3306 -w 3306.pcap -C 50 -W 10。
然后导入到 WireShark 工具中分析,重点关注 TCP Retransmission 即 TCP 重传。
 图片
图片
- 网络阻塞
如机器带宽打满,具体表现也是 TCP 重传,这里可以观测机器的带宽监控和机器支持的最大带宽做对比,看看是否超过限制。
 图片
图片
数据库&数据库中间件异常
当数据库或者数据库中间件出现异常时,对于上游应用的表现大多数就是 SQL RT 增高、TCP 重传。如果怀疑是数据库或者数据库中间件出现异常,可以先确定自己的应用连的是哪个库,这里可以通过应用监控(上下游 -RDS)直观的看到应用连接的具体的库信息,然后再观测对应 RDS 和数据库中间件的监控进一步分析。
 图片
图片
- 如果是数据库中间件域名,就可以看数据库中间件的监控大盘。
 图片
图片
如果数据库中间件本身没有异常,可以继续下钻到 RDS。
 图片
图片
- 如果是 RM/RR 开头的,说明连的是 RDS,可以看阿里云的 RDS 监控,把下面的 Rdsid 替换一下即可。
https://rdsnext.console.aliyun.com/detail/{替换成rdsId}/performance?reginotallow=cn-hangzhou&DedicatedHostGroupId=重点观测 CPU内存利用率 & IOPS 使用率,也可以框选指定时间段进行自动诊断。
 图片
图片
四、总结
本文列举了几乎所有可能导致连接池获取连接慢的 case,相信看完的读者以后再遇到此类问题时,再也不会一头雾水了。学会自助排查,不光可以提升自己的排障能力,同时也能减轻各位中间件 &DBA 小伙伴的客服压力。
参考文档:https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing