在当今的软件开发世界中,Python已经成为了一种无可替代的编程语言。它的简洁、易读易写的语法以及丰富的库使得Python成为了众多开发者的首选。在Python的世界里,有许多神奇的库可以大大提升开发效率,本文将带你探索其中的5个神奇库,让你的编程之旅更加高效、轻松、愉快!

UMAP
UMAP(Uniform Manifold Approximation and Projection)是一种强大的非线性降维算法,能够将高维数据映射到低维空间,为数据可视化和分析提供了极大的便利。在Python中,UMAP算法的Python实现库为开发者提供了实现该算法的便捷途径,为数据科学家和机器学习从业者们提供了强大的工具,使得他们能够更好地理解和分析复杂的高维数据。
(1) 安装
首先,您需要安装UMAP库,可以使用pip命令进行安装:
pip install umap-learn(2) 使用示例
如下代码是使用UMAP算法对鸢尾花数据集进行降维并可视化。首先,通过load_iris方法加载鸢尾花数据集,然后使用UMAP模型对数据进行降维。最后,利用matplotlib库绘制降维后的数据散点图,并根据鸢尾花的类别进行着色,以便于观察数据的聚类情况。
import umap
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
X = data.data
y = data.target
umap_model = umap.UMAP(n_neighbors=10, min_dist=0.1, n_components=2,random_state=2023)
umap_result = umap_model.fit_transform(X)
plt.scatter(umap_result[:, 0], umap_result[:, 1], c=y, cmap='viridis')
plt.title('UMAP (Uniform Manifold Approximation and Projection)')
plt.xlabel('Component 1')
plt.ylabel('Component 2')
# plt.colorbar()
plt.show()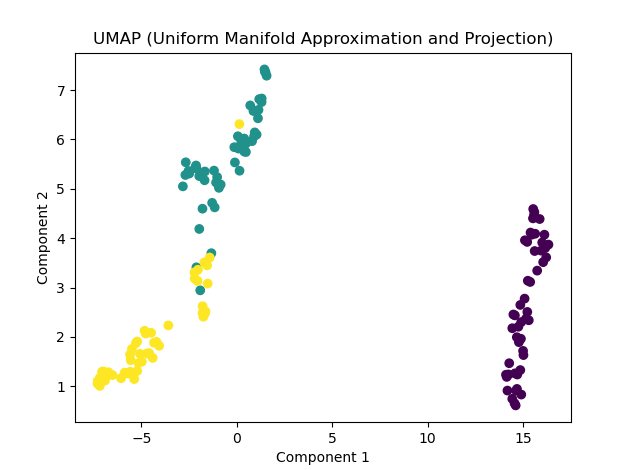
folium
folium是一个用于创建交互式地图的 Python 库。它基于Leaflet.js构建,可以帮助用户轻松地在 Web 应用程序中集成地图可视化。Folium 提供了丰富的地图定制选项,包括标记、弹出窗口、热力图等功能,使得用户可以灵活地展示地理空间数据。无论是用于数据分析、可视化还是 Web 应用程序开发,Folium 都是一个强大而灵活的工具,为 Python 用户提供了创建交互式地图可视化的便利途径。
(1) 安装
pip install folium(2) 示例代码
如下代码使用 Folium 库创建了一个简单的地图,并将全球各国的政治边界以 GeoJSON 的形式添加到地图上。接着将地图保存为名为 footprint.html 的 HTML 文件。打开该文件,你将看到一个交互式地图,其中包含了全球各国的政治边界信息。
import folium
political_countries_url = (
"http://geojson.xyz/naturalearth-3.3.0/ne_50m_admin_0_countries.geojson"
)
m = folium.Map(location=(30, 10), zoom_start=3, tiles="cartodb positron")
folium.GeoJson(political_countries_url).add_to(m)
m.save("footprint.html")numexpr
numexpr 是一个用于在 NumPy 数组上进行快速数值表达式计算的库。它使用了CPU的并行计算能力和缓存优化,能够在不需要创建临时数组的情况下,快速地对数组进行元素级运算。Numexpr可以显著提高数值计算的速度,特别是当需要处理大型数组时,它的性能优势更加明显。
(1) 安装
pip install numexpr(2) 示例代码
import numpy as np
import numexpr as ne
# 创建两个随机的大型 NumPy 数组
a = np.random.rand(1000000)
b = np.random.rand(1000000)
# 使用 Numexpr 计算表达式
c = ne.evaluate('a + b')
print(c)sviewgui
sviewgui是一个基于PyQt的GUI,无需写大量代码,只需动动鼠标就可以实现csv文件或Pandas的DataFrame的数据可视化。
(1) 安装
pip install sviewgui(2) 示例代码
如下代码可以看出,sviewgui模块用法超级简单,它只有一个函数 buildGUI()。
from sviewgui import sview as sv
sv.buildGUI()运行如上代码即可启动GUI,启动之后如下图所示。
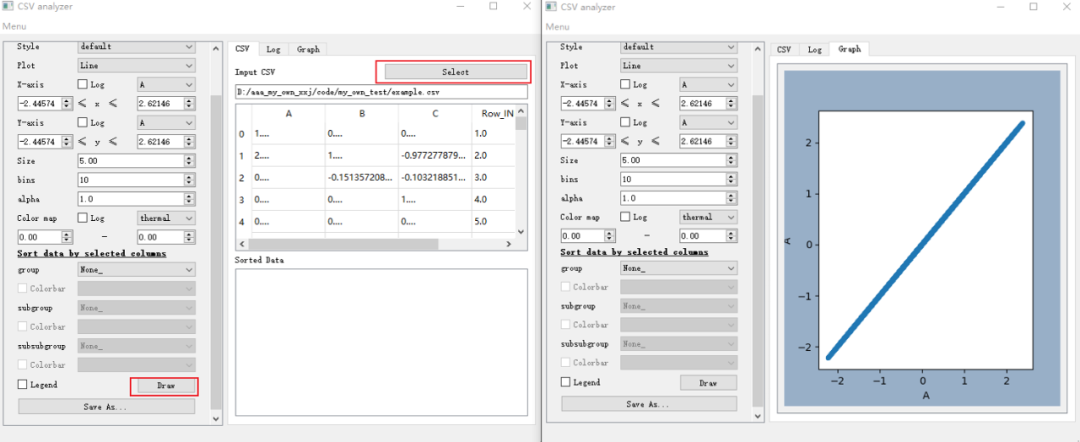
再导入csv文件,点击draw按钮,数据可视化效果如右图。
此方法可以传入零个或一个参数,您也可以使用csv文件的文件路径或pandas的DataFrame对象作为参数,再打开GUI。这里以Iris数据集为例,代码如下:
import pandas as pd
from sklearn import datasets
# sviewGUI
from sviewgui import sview as sv
#加载iris数据
iris = datasets.load_iris()
#创建DataFrame对象
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target_names[iris.target]
#DataFrame存入csv文件
SAVE_PATH = 'iris.csv'
df.to_csv(SAVE_PATH) # save as CSV
# build GUI with the filepath
sv.buildGUI(SAVE_PATH)
# build GUI with pandas' DataFrame object
sv.buildGUI(df)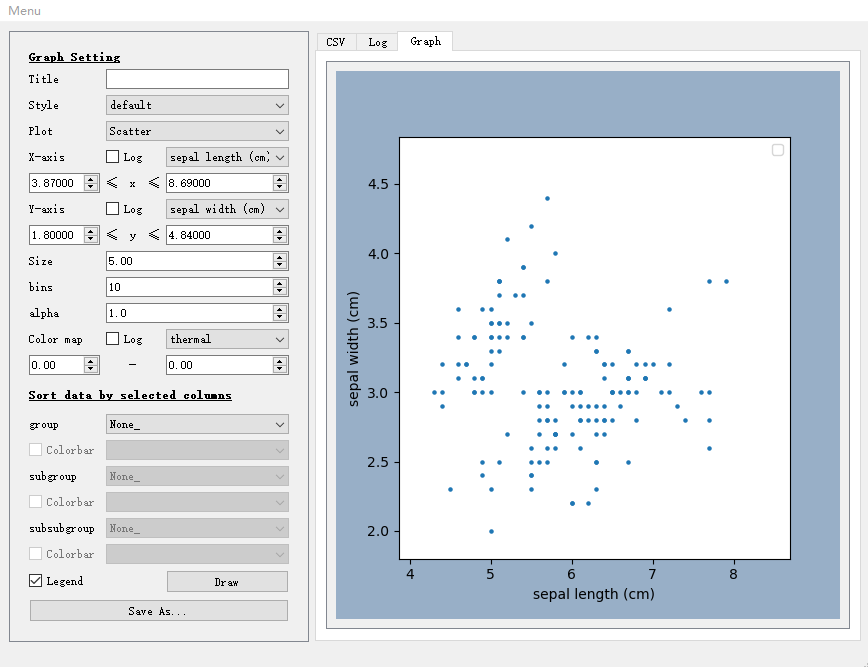

Pynlpir
Pynlpir是一个非常优秀的 Python 中文自然语言处理库。它提供了一系列功能,包括分词、词性标注、命名实体识别等。Pynlpir的安装和使用相对简单,可以通过pip包管理器进行安装。通过导入Pynlpir库,你可以轻松地在Python代码中调用相关函数进行中文文本处理。
(1) 安装
pip install pynlpir(2) 示例代码
如下是使用Pynlpir进行中文文本分词的示例代码:
import pynlpir
# 输入文本进行分词
text = "这是一段中文文本,我们使用pynlpir进行分词"
result = pynlpir.segment(text)
print(result)执行结果如下:
[('这是', 'r'), ('一', 'm'), ('段', 'q'), ('中文', 'nz'), ('文本', 'n'),
(',', 'w'), ('我们', 'r'), ('使用', 'v'), ('pynlpir', 'nz'), ('进行', 'v'),
('分词', 'n')]