












为了应对多模态大语言模型中视觉信息提取不充分的问题,哈尔滨工业大学(深圳)的研究人员提出了双层知识增强的多模态大语言模型-九天(JiuTian-LION)。

论文链接: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
项目主页: https://rshaojimmy.github.io/Projects/JiuTian-LION
与现有的工作相比,九天首次分析了图像级理解任务和区域级定位任务之间的内部冲突,提出了分段指令微调策略和混合适配器来实现两种任务的互相提升。
通过注入细粒度空间感知和高层语义视觉知识,九天实现了在包括图像描述、视觉问题、和视觉定位等17个视觉语言任务上显著的性能提升( 比如Visual Spatial Reasoning 上高达5% 的性能提升),在其中13个评测任务上达到了国际领先水平,性能对比如图1所示。

图1:对比其他MLLMs,九天在大部分任务上都取得了最优的性能。
九天JiuTian-LION
借助大型语言模型(LLMs)惊人的语言理解能力,一些工作开始通过赋予 LLM 多模态感知能力,来生成多模态大语言模型(MLLMs),并在很多视觉语言任务上取得突破性进展。但是现有的MLLMs大多采用图文对预训练得到的视觉编码器,比如 CLIP-ViT。
这些视觉编码器主要学习图像层面的粗粒度图像文本模态对齐,而缺乏全面的视觉感知和信息抽取能力,包括细粒度视觉理解。
这种视觉信息抽取不足,理解程度不够的问题,在很大程度上会导致MLLMs存在视觉定位偏差,空间推理不足,物体幻觉等诸多缺陷,如图2所示。
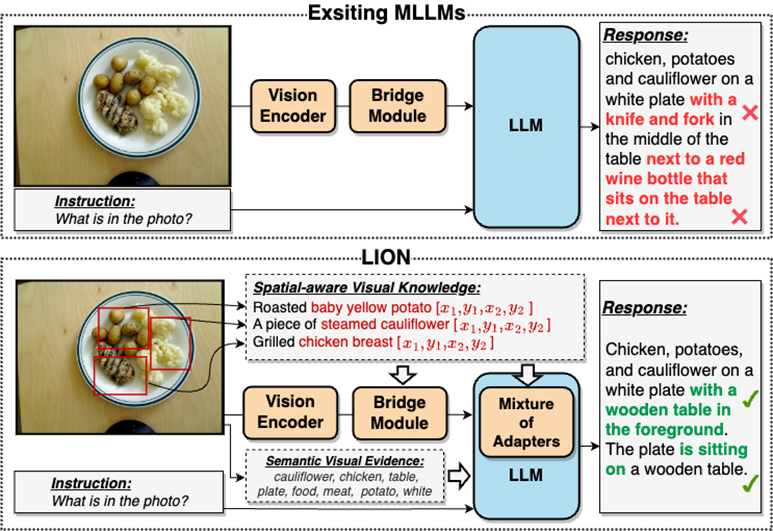
图2:双层视觉知识增强的多模态大语言模型-九天(JiuTian-LION)。
与现有的多模态大语言模型(MLLMs)相比,九天通过注入细粒度空间感知视觉知识和高层语义视觉证据,有效地提升了MLLMs的视觉理解能力,生成更准确的文本回应,减少了MLLMs的幻觉现象。
双层视觉知识增强的多模态大语言模型-九天(JiuTian-LION)
为了弥补MLLMs中视觉信息提取不足,理解程度不够的问题,研究人员提出了双层视觉知识增强的MLLMs,简称九天(JiuTian-LION),方法框架如图3所示。
该方法主要从两方面增强MLLMs,渐进式融合细粒度空间感知视觉知识(Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge)和软提示下的高层语义视觉证据(Soft Prompting of High-level Semantic Visual Evidence)。
具体来说,研究人员提出了分段指令微调策略来解决图像级理解任务和区域级定位任务之间存在的内部冲突,渐进式地将细粒度空间感知知识注入到 MLLMs 中。同时将图像标签作为高层语义视觉证据加入到 MLLMs,并利用软提示方法来减轻不正确标签带来的潜在负面影响。
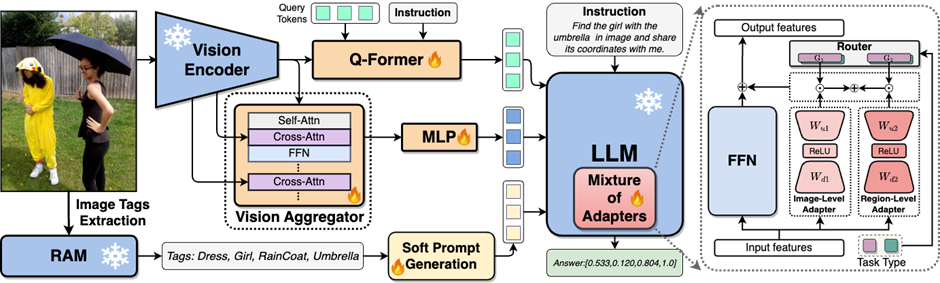
图3:九天( JiuTian-LION) 模型框架图。
该工作通过分段式训练策略先分别基于Q-Former 和 Vision Aggregator – MLP 两个分支学习图像级理解和区域级定位任务,然后在最后训练阶段利用具有路由机制的混合适配器来动态融合不同分支的知识提升模型在两种任务的表现。
该工作还通过 RAM 提取图像标签作为高层语义视觉证据,然后提出软提示方法提升高层语义注入的效果。
渐进式融合细粒度空间感知视觉知识
当直接将图像级理解任务(包括图像描述和视觉问答)与区域级定位任务(包括指示表达理解,指示表达生成等)进行单阶段混合训练时,MLLMs 会遭遇两种任务之间存在的内部冲突,从而不能在所有任务上取得较好的综合性能。
研究人员认为这种内部冲突主要由两个问题引起。第一个问题是缺少区域级的模态对齐预训练,当前具有区域级定位能力的 MLLMs 大多先使用大量相关数据进行预训练,不然很难在有限地训练资源下让基于图像级模态对齐的视觉特征适应区域级任务。
另一个问题是图像级理解任务和区域级定位任务之间的输入输出模式差异,后者需要模型额外理解关于物体坐标的特定短句(以 的形式)。为了解决以上问题,研究人员提出了分段式指令微调策略,以及具有路由机制的混合适配器。
的形式)。为了解决以上问题,研究人员提出了分段式指令微调策略,以及具有路由机制的混合适配器。
如图4所示,研究人员将单阶段指令微调过程拆分为三阶段:
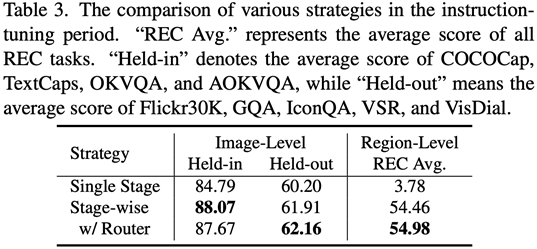
阶段1,利用 ViT,Q-Former,和image-level adapter 来学习图像级理解任务中包含的全局视觉知识;阶段2,利用Vision Aggregator, MLP,和 region-level adapter 去学习区域级定位任务中包含的细粒度空间感知视觉知识;阶段3,提出了具有路由机制的混合适配器来动态融合不同分支中学习到的不同粒度的视觉知识。表3展示了分段式指令微调策略相比较单阶段训练的性能优势。
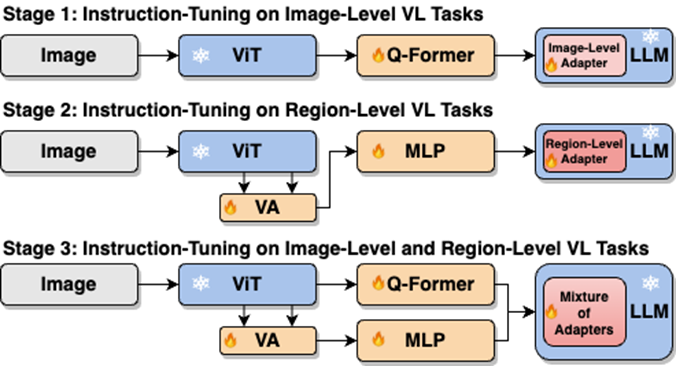
图4:分段式指令微调策略
软提示下的高层语义视觉证据注入
作为一个有力的补充,研究人员提出利用图像标签作为高层语义视觉证据来进一步增强 MLLMs 的全局视觉感知理解能力。
具体来说,首先通过 RAM 提取图像的标签,然后利用特定的指令模版“According to <hint>, you are allowed to use or partially use the following tags:”包装图像标签。该指令模版中的“<hint>”会被替换为一个可学习的软提示向量。
配合模版中特定短语“use or partially use”,软提示向量可以指导模型减轻不正确标签带来的潜在负面影响。
实验结果
研究人员在包括图像描述(image captioning)、视觉问答(VQA)、和指示表达理解(REC)等17个任务基准集上进行了评测。
实验结果表明,九天在13个评测集上达到了国际领先水平。特别的,相比较 InstructBLIP 和 Shikra,九天分别在图像级理解任务和区域级定位任务上取得了全面且一致的性能提升,在 Visual Spatial Reasoning (VSR) 任务上可达到最高5%的提升幅度。

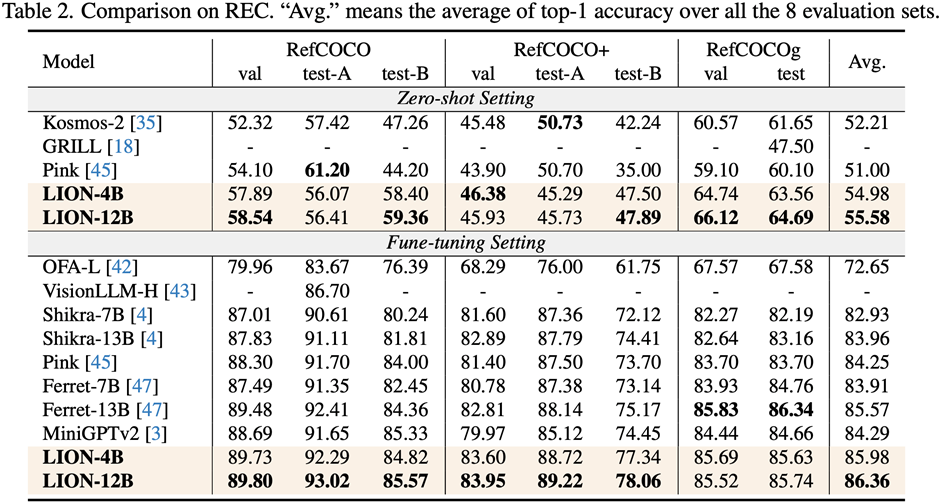
图5提供了在不同视觉语言多模态任务上,九天和其他 MLLMs 的能力差异,说明了九天可以取得更优的细粒度视觉理解和视觉空间推理能力,并且输出具有更少幻觉的文本回应。

图5:定性分析九天大模型和 InstructBLIP、Shikra 的能力差异
图6通过样本分析,表明了九天模型在图像级和区域级视觉语言任务上都具有优秀的理解和识别能力。

图6:更多例子分析,从图像和区域级视觉理解层面展现九天大模型的能力
总结
(1)该工作提出了一个新的多模态大语言模型-九天:通过双层视觉知识增强的多模态大语言模型。
(2)该工作在包括图像描述、视觉问答和指示表达理解等17个视觉语言任务基准集上进行评测,其中13个评测集达到了当前最好的性能。
(3)该工作提出了一个分段式指令微调策略来解决图像级理解和区域级定位任务之间的内部冲突,实现了两种任务的互相提升。
(4)该工作成功将图像级理解和区域级定位任务进行整合,多层次全面理解视觉场景,未来可以将这种全面的视觉理解能力应用到具身智能场景,帮助机器人更好、更全面地识别和理解当前环境,做出有效决策。




























