计算机视觉的GPT时刻,来了!
最近,来自UC伯克利的计算机视觉「三巨头」联手推出了第一个无自然语言的纯视觉大模型(Large Vision Models),并且第一次证明了纯视觉模型本身也是可扩展的(scalability)。
除此之外,研究人员还利用超过420B token的数据集让模型可以通过上下文学习来理解并执行下游任务,并且统一了图片/视频、有监督/无监督、合成/真实、2D/3D/4D等几乎所有的数据形式。

论文地址:https://arxiv.org/abs/2312.00785
值得一提的是,让LVM做非语言类智商测试(Raven's Progressive Matrices )中常见的非语言推理问题,它时常能做出正确的推断。
对此,研究人员惊喜地表示,这或许意味着LVM也展现出了「AGI的火花」!

纯视觉模型的逆袭
现在,随着大语言模型的爆发,不管是学术界还是业界,都开始尝试使用「文本」来扩大视觉模型的规模。
包括GPT4-V在内的SOTA模型,都是把视觉和文字组合在一起训练的。
以「苹果」为例,这种方法在训练时不仅会给模型看「苹果的照片」,而且还会配上文字「这是一个苹果」。
然而,在面对更加复杂的图片时,就很容易忽略其中大量的信息。
比如「蒙娜丽莎」应该怎么去描述?或者摆满各种物品的厨房的照片,也很难清晰地被描述出来。

对此,来自UC伯克利和约翰斯·霍普金斯大学的研究人员,提出了一种全新的「视觉序列」建模方法,可以在不使用任何语言数据的情况下,训练大规模视觉模型(Large Vision Model)。
这种名为「视觉序列」的通用格式,可以在其中表征原始图像和视频,以及语义分割、深度重建等带标注的数据源,且不需要超出像素之外的任何元知识。
一旦将如此广泛的视觉数据(包含4200亿个token)表征为序列,就可以进行模型的训练,让下一个token预测的交叉熵损失最小化。
由此得到的LVM模型,不仅可以实现有效地扩展,完成各种各样的视觉任务,甚至还能更进一步地涌现出比如数数、推理、做智力测试等能力。

左:Alexei A Efros;中:Trevor Darrell;右:Jitendra Malik
简单来说就是,大规模视觉模型只需看图训练,就能理解和处理复杂的视觉信息,完全不用依赖语言数据。
纯视觉模型的扩展难题
此前,使用预训练模型的价值 (例如ImageNet预训练的 AlexNet) ,早在2015年就已经在R-CNN中得到了证明。
从此, 它从此成为计算机视觉的标准实践。
而自监督预训练,作为一种大大增加可用于预训练的数据量的方法被提出。
不幸的是,这种方法并不是很成功,可能是因为当时基于CNN的架构没有足够的能力来吸收数据。
随着Transformer的推出,其容量变得高得多,因此研究人员重新审视了自监督预训练,并发现了基于Transformer的掩码图像重建方法,例如BEiT, MAE,SimMIM,它们要比基于CNN的同类方法表现好得多 。
然而,尽管如此,目前预训练的纯视觉模型在扩展到真正大的数据集(例如LAION) 时,还是遇到了困难。
如何构建「大视觉模型」
那构建一个大规模视觉模型(Large Vision Model,LVM),需要哪些要素呢?
动物世界告诉我们,视觉能力并不依赖于语言。而许多实验表明,非人类灵长类动物的视觉世界,和人类的极为相似。
因此,本文走在了LLaVA这种视觉-语言模型不同的方向:仅依靠像素,我们能走多远?
研究人员试图在LVM中,模仿LLM的两个关键特性:(1)在大数据环境下的扩展能力,和(2)通过提示(上下文学习)灵活地指定任务。
为了实现这一目标,需要明确三个主要组件:
数据:研究人员希望,能够充分利用视觉数据显著的多样性。
首先是原始的未经标注的图像和视频。接下来,研究人员计划利用过去几十年中产生的各种带标注的视觉数据资源,如语义分割、深度重建、关键点、3D物体的多个视图等。
为此,他们定义了一种名为「视觉序列」的通用格式,来表示这些不同的标注,而不需要任何超出像素本身的元知识。训练数据集总共包含1.64亿张图像/帧。
架构:研究人员使用了一个具有30亿参数的大型Transformer架构,这个架构在被表征为token序列的视觉数据上进行训练。
通过学习到的tokenizer,将每个图像映射到一个包含256个向量量化token的字符串。
损失函数:研究人员从自然语言处理领域获取了灵感,其中掩码token模型已经演变为顺序自回归预测。
一旦能够将图像/视频/带标注的图像都表征为序列,就可以训练模型来最小化预测下一个token的交叉熵损失。
通过这种极简的设计,研究人员有了一些新颖的发现——
- 随着模型尺寸和数据大小的增加,模型会表现出适当的扩展行为。
- 通过在测试时设计合适的视觉提示,可以解决多种视觉任务。
- 大量无监督数据,对于各种标准视觉任务性能的提升非常明显。
- 模型在处理超出分布外数据和执行新颖任务时,表现出了一般的视觉推理能力,但还需要进一步的调查研究。
数据
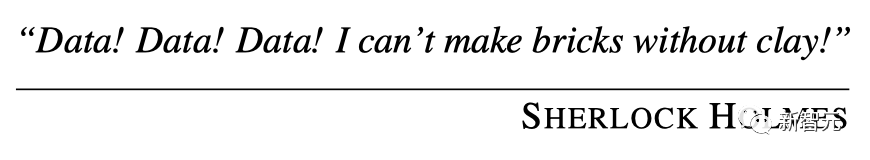
数据!数据!数据!没有粘土我就做不了砖头!
——夏洛克·福尔摩斯
任何大型预训练模型的关键,就必须接受大量数据的训练。
对于语言模型来说,获得非常多样化的大数据集,是很容易的事。
比如,流行的 CommonCrawl存储库,就包含扫描了整个网络的2500亿个网页,极其多样化,并且包括语言翻译、问题回答等「自然演示」。
然而在计算机视觉领域,想要拥有同样规模和多样性的数据源,还差得很远。
因此,研究人员的工作核心贡献之一,就是构建这样一个统一视觉数据集(UVDv1)。

为此,研究人员利用了许多不同的视觉数据源:(1)未标注的图像,(2)具有视觉标注的图像,(3)未标注的视频,(4)具有视觉标注的视频,(5)3D合成物体。
其中,未标注的图像占了总数据的80%以上,组成了大部分的视觉世界,也提供了所需的多样性,然而代价就是,数据源质量较低。
带标注的图像分布会更受限制,但通常质量更高。
而视频数据则受到更多限制(一般是以人类为中心的活动),但它们却是时态数据的宝贵来源。
3D合成对象的渲染多样性最低,但可以提供有关3D结构行为的宝贵提示。
而最重要的是,UVDv1是一个纯粹的视觉数据集,不包含文本之类的非视觉元数据。
总之,UVDv1包含16.4亿张图像。
与LLM的另一个重要区别是,语言数据对所有数据都有一个自然的、统一的一维结构——文本流。
然而不幸的是,视觉数据的情况却并非如此,不同的来源都有不同的结构。
因此在这项工作中,研究人员提出视觉序列,作为视觉数据的统一单元,这就使得他们能够从不同的集合源,训练可扩展的模型。
视觉序列只是包含一个或多个图像的序列,后面跟随着一个句尾 (EOS) token。
图1可以显示出,各种数据源是如何划分为视觉序列的。
单张图像
单张图像本身代表了视觉序列的最简单形式一一{图像,EOS}。
研究人员使用了LAION 5B数据集中14.9亿张图像的过滤子集。
这是迄今为止数据中最大的部分,占了88.5%。
图像序列
图像序列是视觉序列的自然形式。
研究人员通过从各种现有数据集中获取视频数据,来创建此类序列。
16帧的视觉序列,是通过以三个不同步长(10、20和30) 对视频进行机采样而形成的。
此外,研究人员利用了来自0bjaverse数据集的合成3D物体,生成了以物体为中心的多视角序列。
对于每个物体,研究人员都在物体中心和摄像机之间,采样了一个半径1.5到2.2的长度,并从-45度到45度采样了一个恒定仰角,然后遍历物体的不同视角(以15度步长和渲染24个视角的方式,改变方位角)。
通过这种方法,研究人员总共渲染了42000个这样的序列用于训练,8000个序列用于测试。
最后,还可以将属于同一语义类别的图像表征为序列的(一部分)。
使用ImageNet中的类别,将同一类别中的图像组(2、4、8或16个)连接成一个16幅图像的长序列。
带标注的图像
为了以统一的方式处理不同类型的图像标注,研究人员选择将所有标注表征为图像。
某些数据类型,例如语义分割图,边缘图,深度和普通图像,已经是以这种方式表征的。
对于其他数据类型,研究人员为每种特定的标注类型,量身定制了不同方法——
1. 物体检测:通过在每个物体周围覆盖颜色编码的边界框,来创建标注。
2. 人体姿态:利用MMPose,遵循OpenPose格式,在像素空间中渲染人体骨骼。
3. 深度估计、表面法线和边缘检测:对于给定的ImageNet和COCO图像,按照特定协议生成标注。
4. 风格迁移、除雨、去噪、弱光增强和立体数据集:这些都表征为图像对的形式(例如输入/输出)。
5. 着色:将ImageNet图像转换为灰度图像,生成图像对。
6. 修复:在图像中随机添加黑色框来模拟损坏,从而产生图像对。



对于上述所有标注类型,可以通过将相同标注类型的8个图像对,连接成16个图像的视觉序列,来创建视觉序列。
对于包含同一图像的k个不同标注的数据集,使用不同的方法: 对于每组1+k 个图像 (输入多于k的标注),然后随机选择m个元素,其中m≤n+1≤16。然后将这些m元组连接起来,形成视觉序列。
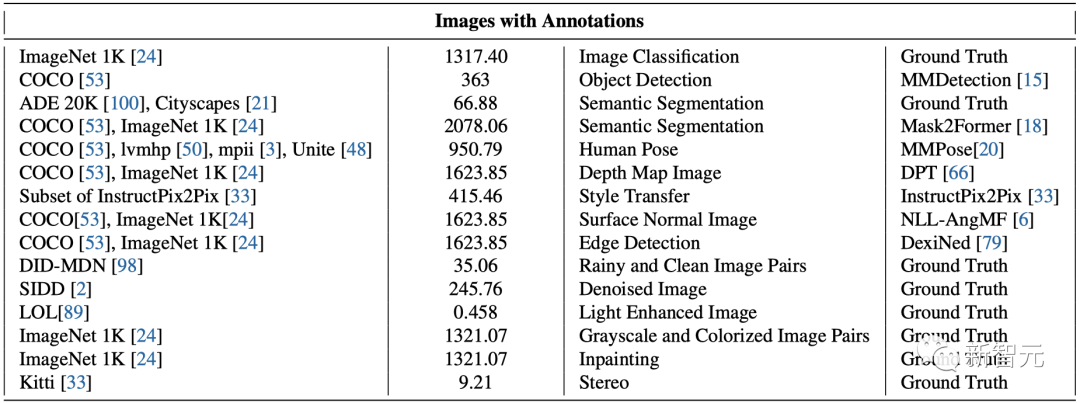
带标注的图像序列
在将带标注的视频数据(VIPSeg、Hand14K、AVA、JHMDB)转换为视觉序列时,采用了两种互补策略。
第一种策略类似于处理成对标注图像数据的方法:每个视觉序列都是通过将帧与它们的标注连接起来而构建的——{frame1,annot1,frame2,annot2,...}。
第二种方法是将多个帧与相应的标注{frame1,frame2,annot1,annot2,...}进行分组。

实现方法
与天然展现离散序列结构的文本数据不同,将图像像素建模为视觉序列并不直观。在这项工作中,研究人员采取了一个两阶段方法:
1. 训练一个大型视觉tokenizer(对单个图像操作)将每个图像转换成一系列视觉token;
2. 在视觉序列上训练一个自回归Transformer模型,每个序列都表示为一系列token。
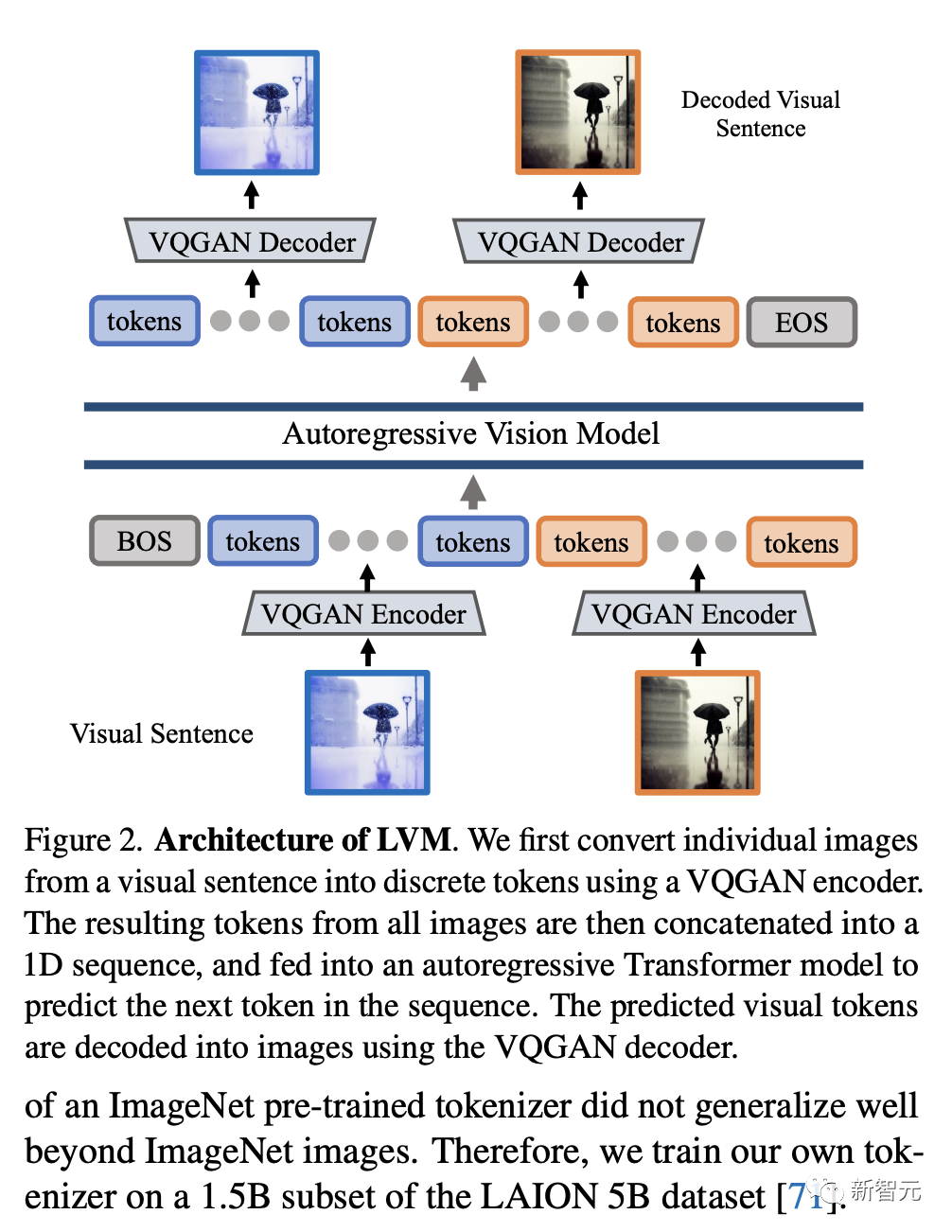
图像分词(Image Tokenization)
虽然视觉序列在连续图像之间展现出了序列结构,但在单个图像内部并没有这样的自然序列结构。
因此,为了将Transformer模型应用于图像,先前的工作通常采用以下方法:要么按扫描线顺序将图像分割成补丁,并将其视为一个序列,要么使用预训练的图像tokenizer,例如VQVAE或VQGAN ,将图像特征聚类成一格一格的离散token,然后再按扫描线顺序将这些token转换成序列。
研究人员采用后一种方法,因为模型的离散分类输出自然形成了一个可以轻松采样的概率分布,使得在视觉序列中灵活生成新图像成为可能。
具体来说,研究人员使用了VQGAN模型生成的语义token。该框架包括编码和解码机制,特点是一个量化层,将输入图像分配给一个已建立代码本的离散token序列。
编码器和解码器完全由卷积层构成。编码器配备了多个下采样模块,以压缩输入的空间维度,而解码器则配备了等量的上采样模块,以恢复图像到其初始大小。
对于给定的图像,研究人员的VQGAN的tokenizer产生256个离散token。
需要注意的是,研究人员的tokenizer独立地对单个图像进行操作,而不是一次性处理整个视觉序列。
这种独立性允许研究人员将tokenizer训练与下游Transformer模型分离,这样tokenizer就可以在单图像数据集上进行训练,而无需考虑视觉序列的分布。
实现细节:研究人员采用了现成VQGAN架构。其中使用了f=16的下采样因子和8192大小的代码本。这意味着对于一个大小为256×256的图像,研究人员的VQGAN的tokenizer产生16×16=256个token,其中每个token可以取8192个不同的值。
研究人员发现使用ImageNet预训练的tokenizer在ImageNet图像之外并不具有很好的泛化性能。因此,研究人员在LAION 5B数据集的1.5B子集上训练他们自己的tokenizer。
视觉序列的序列建模
使用VQGAN将图像转换成离散token后,研究人员通过将多个图像的离散token连接成一个1D序列,将视觉序列视为一个统一的序列。
重要的是,研究人员平等对待所有视觉序列——研究人员不使用任何特殊token来指示特定任务或格式。
研究人员使用交叉熵损失训练一个因果Transformer模型,其目标是预测下一个token,类似于语言模型的标准方法。用相同的方式训练模型来处理所有视觉序列,使模型能够从上下文而不是从特定于任务或格式的token中推断出图像之间的关系。这使得模型有机会推广到其他未见过的视觉序列结构。
实现细节:研究人员将视觉序列中的每个图像分词成256个token,然后将它们连接成一个1Dtoken序列。
在视觉token序列的基础上,研究人员的Transformer模型几乎与自回归语言模型相同,因此研究人员采用了LLaMA 的Transformer架构。
研究人员使用4096 token的上下文长度,可以适应研究人员VQGAN tokenizer下的16幅图像。
类似于语言模型,研究人员在每个视觉序列的开头添加一个[BOS](序列开始)token,在末尾添加一个[EOS](序列结束)token,并在训练时使用序列连接(sequence concatenation)来提高效率。
研究人员在整个UVDv1数据集(4200亿token)上训练研究人员的模型,使用一个周期(在语言模型中使用简单周期训练,以避免潜在的过拟合)。
研究人员训练了4种不同参数数量的模型:3亿、6亿、10亿和30亿,遵循相同的训练配置。
通过视觉提示进行推理
由于研究人员模型中的自回归Transformer输出了基于先前token的下一个token的概率分布,研究人员可以轻松地从这个分布中抽样,生成完成视觉序列的新视觉token。
要将模型用于下游任务,可以在测试时构建定义任务的部分视觉序列,并应用模型生成输出。这类似于语言模型中的上下文学习或计算机视觉中的视觉提示。
实验结果与分析
最后,研究人员评估了模型的扩展能力,以及它理解和回答各种提示任务的能力。
可扩展性
研究人员研究了研究人员的模型在训练损失和下游任务性能方面的扩展行为,随着模型大小的增加以及训练过程中看到的token数量的增加。
训练损失。首先,研究人员检查了不同参数大小的LVM的训练损失,见下图。

由于研究人员的所有模型仅在数据集上训练了一个epoch,因此模型只看到每个数据样本一次,因此在训练过程中的任何时候的训练损失与验证损失非常相似。
可以观察到随着训练的进行:
1. 不同大小模型的训练损失(困惑度)持续下降;
2. 随着模型规模(参数计数)的增加,损失下降得更快。这些观察表明,LVM在更大的模型和更多数据方面显示出强大的可扩展性。
虽然LVM在训练过程中整体损失良好地扩展,但并不能保证更好的整体模型也会在特定的下游任务上表现更好。
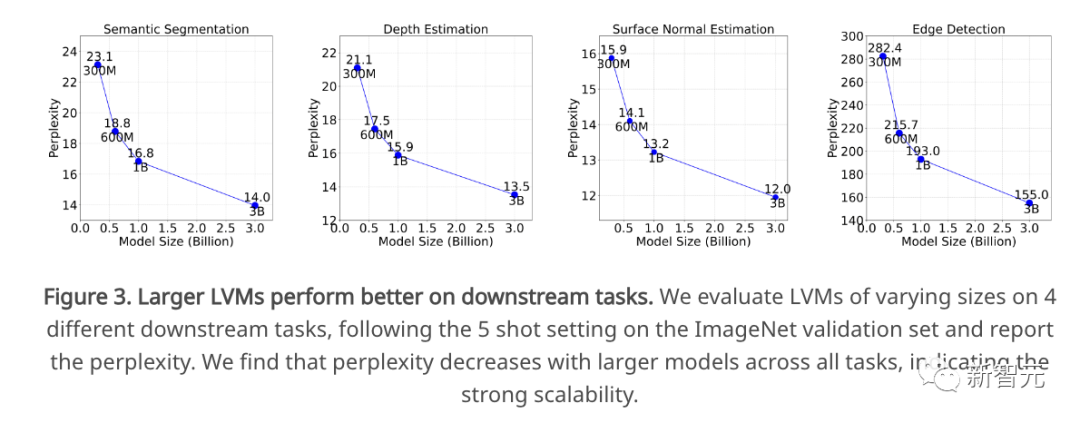
因此,研究人员在4个下游任务上评估不同大小的模型:语义分割、深度估计、表面法线估计和边缘检测。研究人员在ImageNet验证集上评估这些任务。
对于每个任务,研究人员给出5对输入和相应真实标注以及作为输入提示的查询图像,并评估研究人员模型对下一个256个token(一幅图像)的真实标注的困惑度预测。
下图中,研究人员展示了,更大的模型确实在所有任务上获得了更低的困惑度,展示了研究人员的可扩展整体性能确实转化为一系列下游任务。
虽然LVM在更大的模型和更多数据上获得了更好的性能,但很自然地一个问题是,在UVDv1中收集的每个数据组件是否有帮助。
为了回答这个问题,研究人员在研究人员的数据集上对几个3B模型进行了消融研究,这些模型是在研究人员数据集的子集上训练的,并比较了它们在下游任务上的表现。
研究人员使用之前相同的4个下游任务和设置,并在下图中展示了结果。
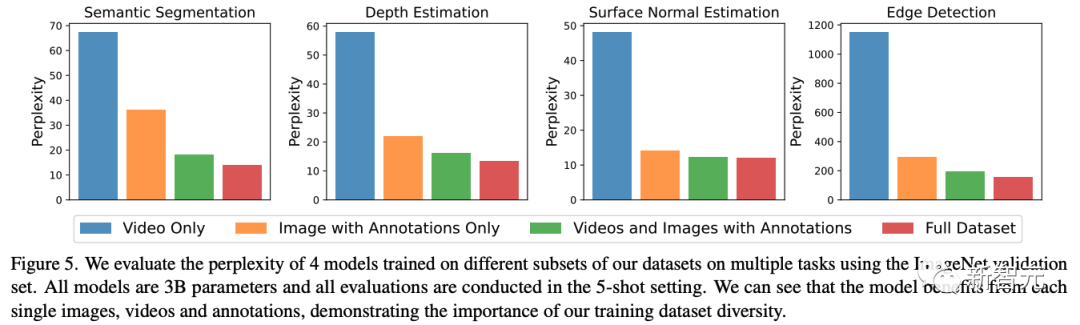
研究人员观察到,每个数据组件对下游任务都有积极的贡献。LVM不仅从更大的数据中受益,而且随着数据集中的多样性(包括标注和无监督的图像和视频数据)的增加而改进。
顺序提示
研究人员首先采用最直观、最简单的方法来对LVM进行视觉提示:顺序推理。在这里,提示构建非常简单:研究人员向模型展示7幅图像的序列,并要求它预测下一幅图像(256个token)。
对于顺序提示来说,最直接的任务是视频预测。下图展示了从Kinetics-700验证集序列中提示的几个下一帧预测示例。

在顶部示例中,7帧提示(蓝色边框)后跟着预测的帧(红色边框)。研究人员观察到在空间定位、视点和对象理解方面有一定程度的推理能力。在Kinetics验证集上预测的困惑度为49.8。
下面示例显示了具有更长上下文(15帧)和更长预测(4帧)的预测。
同样类型的简单顺序提示也可以用其他方式使用。例如,下图显示了如何通过提示模型一个围绕任意轴的合成对象的3D旋转序列,使其能够预测更进一步的旋转。

或者研究人员可以将给定类别的物品列表视为一个序列,并预测该类别中的其他想法,如下图所示。
值得注意的是,虽然该系统在训练时是在同一ImageNet类别的图像组上训练的,但这里的提示包括素描,这些素描在任何标注数据中都没有出现过。

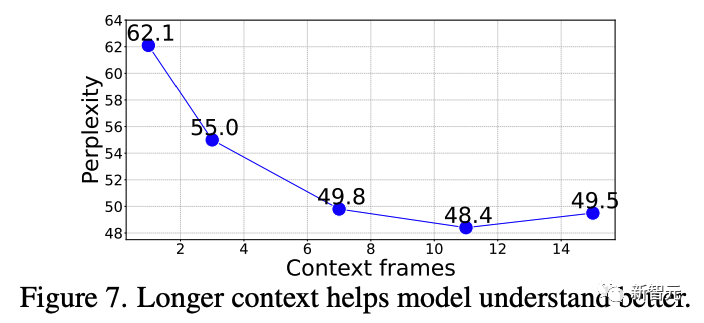
接下来,研究人员研究了准确预测后续帧需要多少时序上下文。
研究人员评估了模型在不同长度(1到15帧)上下文提示下的帧生成困惑度。下图所示,在Kinetics-700验证集上,从1到11帧困惑度明显改善后稳定下来(从62.1 → 48.4)。
类比提示
研究人员的研究通过评估一个更复杂的提示结构来进展,研究人员称之为「类比提示(Analogy Prompting)」。这种方法挑战模型理解任意长度和复杂度的类比,从而测试它的高级解释能力。
下图展示了在多个任务上使用类比提示的定性结果样本。提示包括14幅图像的序列,给出各种任务的示例,然后是第15幅查询图像。给定每个提示,预测的下一幅图像。

图的上部展示了几个定义训练集中任务的示例提示(但这些实际图像从未在训练中见过)。图的下部展示了在训练中从未展示过的任务的泛化。
研究人员展示了在Pascal 3D+ 上对关键点检测的结果,使用标准的正确关键点百分比(PCK)度量,阈值为0.1。值得注意的是,LVM在未对此数据集进行训练的情况下达到了81.2的PCK,显示出了令人印象深刻的泛化能力。
相比之下,研究人员展示了一些现有的特定任务模型:StackedHourglass的PCK为68.0,MSS-Net达到了68.9 PCK,StarMap则有78.6 PCK。
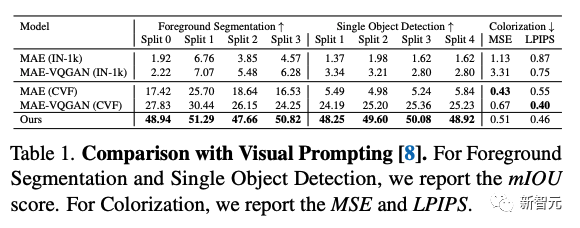
与视觉提示的比较
与研究人员的方法最接近的,也允许定义任意任务的方法是视觉提示。在下表中,研究人员比较了几种视觉提示模型在少量样本分割、对象检测和着色任务上的表现。研究人员的顺序LVM在几乎所有任务上都超过了之前的方法。
任务组合
下图演示了在单个提示中组合多个任务。研究人员展示了旋转任务与新的关键点对应任务,并要求模型继续这种模式。模型能够在测试时成功地组合这两个任务,显示出一定程度的组合性。

其他类型的提示
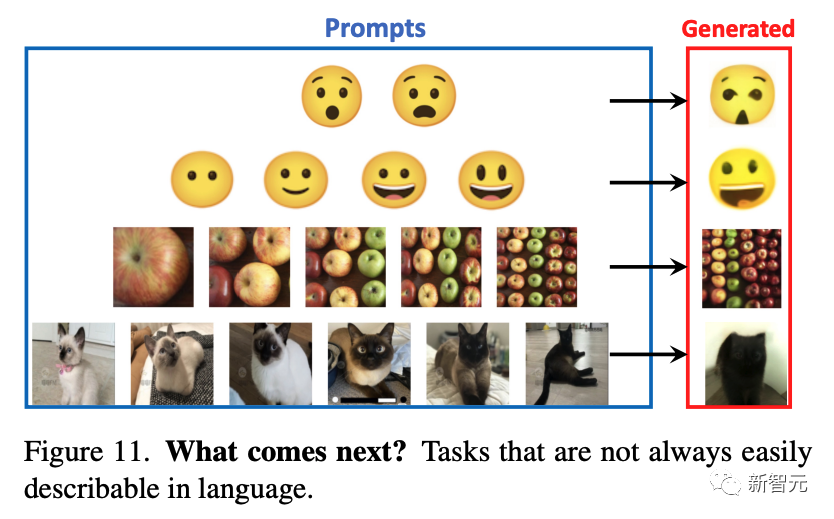
研究人员人员尝试他们是否可以通过向模型提供它以前没有见过的各种提示,看看模型能走到哪一步。
下图展示了一些这样的提示,效果很不错。
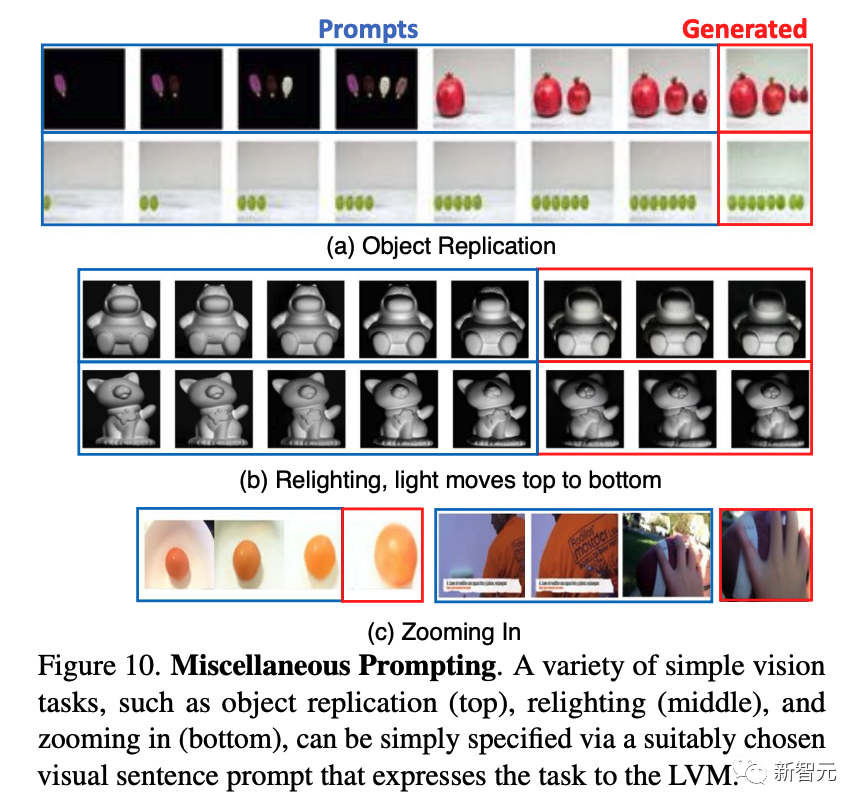
下图展示了一些不容易用语言描述的提示——这是LVM可能最终胜过LLM的任务类型。