












视频 PS 可以灵活到什么程度?最近,微软的一项研究提供了答案。
在这项研究中,你只要给 AI 一张照片,它就能生成照片中人物的视频,而且人物的表情、动作都是可以通过文字进行控制的。比如,如果你给的指令是「张嘴」,视频中的人物就会真的张开嘴。

如果你给的指令是「伤心」,她就会做出伤心的表情和头部动作。

当给出指令「惊讶」,虚拟人物的抬头纹都挤到一起了。

此外,你还可以给定一段语音,让虚拟人物的嘴型、动作都和语音对上。或者给定一段真人视频让虚拟人物去模仿。
如果你对虚拟人物动作有更多的自定义编辑需求,比如让他们点头、转头或歪头,这项技术也是支持的。

这项研究名叫 GAIA(Generative AI for Avatar,用于虚拟形象的生成式 AI),其 demo 已经开始在社交媒体传播。不少人对其效果表示赞叹,并希望用它来「复活」逝者。
但也有人担心,这些技术的持续进化会让网络视频变得更加真假难辨,或者被不法分子用于诈骗。看来,反诈手段要继续升级了。
GAIA 有什么创新点?
会说话的虚拟人物生成旨在根据语音合成自然视频,生成的嘴型、表情和头部姿势应与语音内容一致。以往的研究通过实施特定虚拟人物训练(即为每个虚拟人物训练或调整特定模型),或在推理过程中利用模板视频实现了高质量的结果。最近,人们致力于设计和改进零样本会说话的虚拟人物的生成方法(即仅有一张目标虚拟人物的肖像图片可以用于外貌参考)。不过,这些方法通过采用基于 warping 的运动表示、3D Morphable Model(3DMM)等领域先验来降低任务难度。这些启发式方法虽然有效,但却阻碍了从数据分布中直接学习,并可能导致不自然的结果和有限的多样性。
本文中,来自微软的研究者提出了 GAIA(Generative AI for Avatar),其能够从语音和单张肖像图片合成自然的会说话的虚拟人物视频,在生成过程中消除了领域先验。

项目地址:https://microsoft.github.io/GAIA/
论文地址:https://arxiv.org/pdf/2311.15230.pdf
GAIA 揭示了两个关键洞见:
- 用语音来驱动虚拟人物运动,而虚拟人物的背景和外貌(appearance)在整个视频中保持不变。受此启发,本文将每一帧的运动和外貌分开,其中外貌在帧之间共享,而运动对每一帧都是唯一的。为了根据语音预测运动,本文将运动序列编码为运动潜在序列,并使用以输入语音为条件的扩散模型来预测潜在序列;
- 当一个人在说出给定的内容时,表情和头部姿态存在巨大的多样性,这需要一个大规模和多样化的数据集。因此,该研究收集了一个高质量的能说话的虚拟人物数据集,该数据集由 16K 个不同年龄、性别、皮肤类型和说话风格的独特说话者组成,使生成结果自然且多样化。
根据上述两个洞见,本文提出了 GAIA 框架,其由变分自编码器 (VAE)(橙色模块)和扩散模型(蓝色和绿色模块)组成。

VAE 主要用来分解运动和外貌,其包含两个编码器(即运动编码器和外貌编码器)和一个解码器。在训练过程中,运动编码器的输入是当前帧的面部关键点(landmarks),而外貌编码器的输入是当前视频剪辑中的随机采样的帧。
随后根据这两个编码器的输出,优化解码器以重建当前帧。在获得了训练好的 VAE 后,就得到了所有训练数据的潜在运动(即运动编码器的输出)。
接着,本文训练了一个扩散模型来预测以语音和视频剪辑中的一个随机采样帧为条件的运动潜在序列,这为生成过程提供了外貌信息。
在推理过程中,给定目标虚拟人物的参考肖像图像,扩散模型将图像和输入语音序列作为条件,生成符合语音内容的运动潜在序列。然后,生成的运动潜在序列和参考肖像图像经过 VAE 解码器合成说话视频输出。
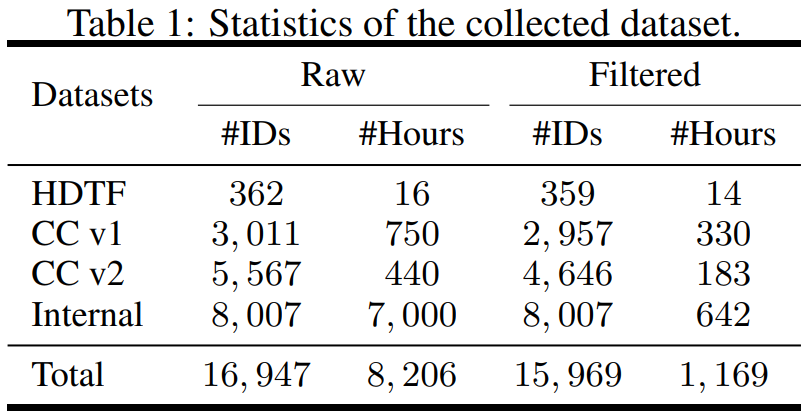
在数据方面。该研究从不同的来源构建数据集,他们收集的数据集包括 HighDefinition Talking Face Dataset (HDTF) 和 Casual Conversation datasets v1&v2 (CC v1&v2) 。除了这三个数据集之外,该研究还收集了一个大规模的内部说话虚拟人物(internal talking avatar)数据集,其中包含 7K 小时的视频和 8K 说话者 ID。数据集统计的概述如表 1 所示。
为了能够从数据中学习到所需的信息,本文还提出了几种自动过滤策略来确保训练数据的质量:
- 为了使嘴唇运动可见,头像的正面方向应朝向相机;
- 为了保证稳定性,视频中的面部动作要流畅,不能出现快速晃动;
- 为了过滤掉嘴唇动作和言语不一致的极端情况,应该删除头像戴口罩或保持沉默的帧。
本文在过滤后的数据上训练 VAE 和扩散模型。从实验结果来看,本文得到了三个关键结论:
- GAIA 能够进行零样本说话虚拟人物生成,在自然度、多样性、口型同步质量和视觉质量方面具有优越的性能。根据研究者的主观评价,GAIA 显着超越了所有基线方法;
- 训练模型的大小从 150M 到 2B 不等,结果表明,GAIA 具有可扩展性,因为较大的模型会产生更好的结果;
- GAIA 是一个通用且灵活的框架,可实现不同的应用,包括可控的说话虚拟人物生成和文本 - 指令虚拟人物生成。
GAIA 效果怎么样?
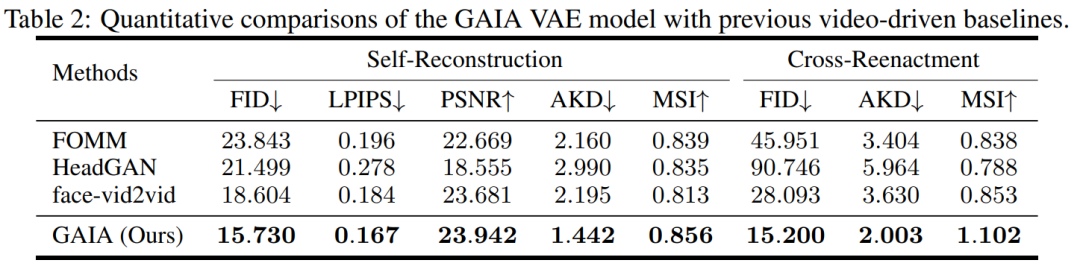
实验过程中,该研究将 GAIA 与三个强大的基线进行比较,包括 FOMM、HeadGAN 和 Face-vid2vid。结果如表 2 所示:GAIA 中的 VAE 比以前的视频驱动基线实现了持续的改进,这说明 GAIA 成功地分解了外貌和运动表示。
语音驱动结果。用语音驱动说话虚拟人物生成是通过从语音预测运动实现的。表 3 和图 2 提供了 GAIA 与 MakeItTalk、Audio2Head 和 SadTalker 方法的定量和定性比较。
可以看出,GAIA 在主观评价方面大幅超越了所有基线。更具体地说,如图 2 所示,即使参考图像是闭着眼睛或不寻常的头部姿态给出的,基线方法的生成往往高度依赖于参考图像,相比之下,GAIA 对各种参考图像具有鲁棒性,并生成具有更高自然度、口型高度同步、视觉质量更好以及运动多样性的结果。

如表 3 所示,最佳 MSI 分数表明 GAIA 生成的视频具有出色的运动稳定性。Sync-D 得分为 8.528,接近真实视频的得分 (8.548),说明生成的视频具有出色的唇形同步性。该研究获得了与基线相当的 FID 分数,这可能是受到了不同头部姿态的影响,因为该研究发现未经扩散训练的模型在表中实现了更好的 FID 分数,如表 6 所示。



























