













数据是支撑企业发展的关键生产要素。随着业务场景的多元化,数据体量不断增长,催生了数据类型多样、交互式分析复杂等挑战,业务对于数据的实时性、资源弹性、融合负载等需求也愈发高涨。由此,一款合适的数据库产品,将成为企业实现数据管理的最佳工具。
在11月10日、11月16日和11月24日举办的“乘云·向未来”火山引擎公共云·城市分享会上,火山引擎以“字节跳动超大规模数据库产品技术演进之路”为题,基于字节跳动业务的多样性、规模化发展,解构了其数据库产品体系特征及技术演进历程,为企业疏解数据管理难题、带来数据治理的良策。
以下为演讲实录:

字节跳动业务发展历程与数据库之挑战
过去十年间,字节跳动的业务飞速发展。从2017年的1亿日活跃用户,到2019年的4亿,再到2023年6亿+,随之而来的是业务的多样性——抖音直播、抖音电商以及飞书等业务快速发展,也使得字节跳动的数据库经历了多代演进。
在2017年,集团数据库的数据量只有2000个集群,且每个集群的规模通常为几十万的体量;到2019年,数据量达到了200+PB;直到今天,数据量已经发展到2EB,峰值吞吐量达到了20B+。面对如此庞大的量级,火山引擎始终在思考数据库技术演进之道,大致可分为三个阶段。

第一阶段是2015-2017年,刀耕火种的石器时代,当时主要靠业务开发兼职运维,经常通宵进行线上运维和扩容。
第二阶段是在2018-2020年,火山引擎发现过去的方式难以为继,于是启动了多品类的数据库建设。基于原有的云原生数据库,火山引擎开发了分布式数据库等产品,在公司内部大规模应用。除此之外,火山引擎还开发了多个运维平台,实现了超大规模集群的自动化管理,摆脱了过去纯靠人工运维的局限性。
第三阶段是从2021年至今,字节跳动开展了更多云原生化的工作,业务规模达到了数万套库/数百万实例。在这个过程中,数据库在技术和应用上遇到了不同种类的挑战。

首先是业务种类的多样性。支付类业务、电商类业务等不同场景对数据库的需求并不一致;各种各样的中台产生的多种数据类型也对数据库提出了更多要求,例如:海量结构化及非结构化数据的管理、用户之间的关系管理等。
第二个挑战是超大规模下高可用问题。在大规模业务同时运行的情况下,如何保证数据库时时刻刻在线,成为每一个应用开发者都会思考的问题,火山引擎也不例外。
第三个挑战是多模式融合负载。例如有些业务对于并发数要求非常高,但容量较小;而有些业务吞吐量较低,但数据量较大,分析类需求较多。
最后一个挑战是资源弹性诉求变强。众所周知,字节跳动的业务具有一定的“季节性”,比如618和春晚,需要通过自动的弹性来应对突发的流量。对此,降低业务成本、提供弹性能力,对数据库而言是非常重要的一环。

火山引擎自研数据库产品全解析
过去,业务很难用单一的数据库来满足所有的负载。因此,为了应对挑战,火山引擎构建了多样化、规模化、融合化、智能化的数据库产品矩阵。
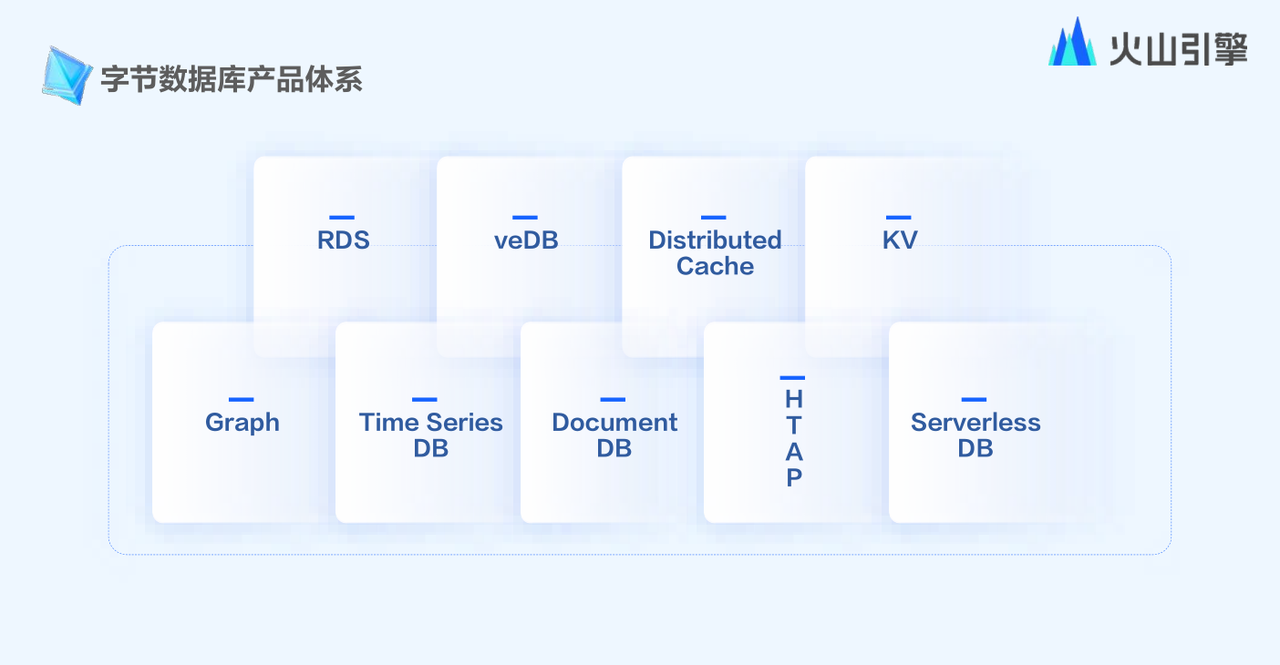
veDB云原生数据库可以解决扩容拆分等一系列问题,实现存储共享,极大降低存储成本;同时,资源的弹性非常好,在解决业务弹性诉求后,能很快将资源弹出来,把计算算力缩下去,降低了用户成本。目前,数据中心90%以上的业务都在用veDB。
在做业务过程中,遇到业务不感知的情况时,可以通过一些平台自动化地解决问题。数据库能够跨三个超大机房进行部署,这一点在运维过程中,相比于过去的扩容、拆分,运维操作难度降低了80%。在此基础上,火山引擎构建了HTAP产品,通过一体化的技术,集成了OLTP、内存等,这对用户而言是完全透明的,复杂的查询可以直接交其处理。
文档数据库DocumentDB是基于云原生技术进行的托管服务,相比于传统数据库,这类产品的数据可以做到实时的一致性,使得数据的“新鲜度”较高。目前,该类产品已在字节跳动内部大规模使用。
Redis Family缓存类产品的特点是兼容Redis协议,在性能上有很好的表现。该产品在内部分成了内存版和磁盘版两个版本,其中磁盘版的容量可以达到上百T,减轻了业务考虑数据的搬迁。字节跳动内部诸如游戏和电商等大型中台,都在使用这一产品。
在跨平台业务中,云原生集群的数据规模也是非常大的,因此火山引擎打造了强一致KV数据库ByteKV,它应用在支付/红包等财务类业务居多,能够保持元数据的安全性,同时支持分布式事务及CAS需求。
火山引擎自2018年开始自研,到2020年左右打造了第一代图数据库,其底层是分布式KV,能够支持万亿点变量级,例如抖音中的相互关注、推荐关系、好友关系等,都是用图数据库来存储的。
2022年,火山引擎打造了下一代的高性能多模态的图数据库。其整体是基于分布式存储,将图数据和非图数据放在一起进行数据同步,减少了存储成本。以极致性价比、统一存储格式,支持一数多算,为用户带来一站式分析体验。
此外,火山引擎还构建了超大规模图计算/图学习的能力。图计算可以直接访问分布式存储、读取数据,内含非常高效的数据流。在如前叙及的HTAP中,数据可以通过图,实时用数据进行图的计算和学习。典型的应用场景就是在抖音电商中,存在大量的风控、支付安全和黑产等需要提取信息的操作,该能力可以秒级查询是否存在风险,为用户带来安全的体验。

聚焦“4+1”战略持续优化产品
面向未来,火山引擎聚焦“4+1”战略对产品进行展望。

第一是智能化,基于AI模型的原生支持,数据库在规模上得到了算力提升。数据库团队也在结合产品进行升级,让零技术基础的用户也可以方便地对数据库进行操作。
第二是将数据库安全化。随着时间推移,合规安全越来越重要,数据库产品除了在本身的性能上提升以外,也在转型可信数据库。例如在企业办公等场景下,每一个字段都是需要加密的,火山引擎要做的就是提升数据安全与隐私保护能力以及数据库平台合规能力。
第三是平台化。火山引擎将在自动化运维、多云一体化部署上持续迭代升级,打造产品化、体系化的解决方案。
第四是在生态方面,火山引擎将与合作伙伴携手,丰富开发者工具和资源,积极拓展市场和合作伙伴关系,共同完善数据库生态建设。
最重要的是,火山引擎将持续进行数据库内核极致优化,真正做到降本、增效;同时,深度整合火山引擎自研DPU等新硬件,持续挖掘硬件红利,通过应用场景方面的融合和基础设施层面的分离、整合,以横纵双融合的系统重塑应用缓存和数据库,助力用户增长。

扫码了解veDB更多详情





















