












GPT-4和LLaMA这样的大型语言模型(LLMs)已在各个层次上成为了集成AI 的主流服务应用。从常规聊天模型到文档摘要,从自动驾驶到各个软件中的Copilot功能,这些模型的部署和服务需求正在迅速增加。
像DeepSpeed、PyTorch和其他几个框架可以在LLM训练期间实现良好的硬件利用率,但它们在与用户互动及处理开放式文本生成等任务时,受限于这些操作的计算密集度相对较低,现有系统往往在推理吞吐量上遇到瓶颈。
为了解决这一问题,使用类似vLLM这样由PagedAttention驱动的框架或是Orca系统可以显著提高LLM推理的性能。
然而,这些系统在面对长提示的工作负载时,依旧难以提供良好的服务质量。随着越来越多的模型(例如MPT-StoryWriter)和系统(例如DeepSpeed Ulysses)支持延伸到数万个token的上下文窗口,这些长提示工作负载变得越来越重要。
为了更好地理解问题,微软DeepSpeed的研究人员最近发表了一篇博文,详细介绍了LLM的文本生成,以及DeepSpeed-FastGen框架是如何在「提示处理」和「生成」的这两个阶段中运行的。
DeepSpeed-FastGen
当系统将「提示处理」和「生成」视为不同的阶段时,生成阶段将被提示处理所抢占,可能会破坏服务级别协议(SLAs)。
通过采用动态SplitFuse技术,DeepSpeed-FastGen框架能够提供比vLLM等先进系统高出多达2.3倍的有效吞吐量。
DeepSpeed-FastGen是DeepSpeed-MII和DeepSpeed-Inference的结合,提供了一个易于使用的服务系统。
快速开始:要使用DeepSpeed-FastGen只需安装最新的DeepSpeed-MII发行版:
pip install deepspeed-mii要使用简单的非持久性管道部署并生成文本,请运行以下代码。
from mii import pipeline
pipe = pipeline("mistralai/Mistral-7B-v0.1")
output = pipe(["Hello, my name is", "DeepSpeed is"], max_new_tokens=128)
print(output)现有LLM服务技术
单个序列的文本生成工作负载包含两个阶段:
1. 提示处理,此阶段系统处理用户输入的文本,将其转换成一系列token并构建用于注意力机制的键值(KV)缓存;
2. 生成token,即向缓存中添加单个token并产生新的token。
在生成文本序列的过程中,系统将对模型进行多次前向调用以生成完整的文本序列,现有文献和系统中已经提出了两种主要技术,解决了这些阶段中可能出现的各种限制和瓶颈。
分块KV缓存
vLLM识别出大型单体KV缓存导致的内存碎片化显著降低了大型语言模型服务系统的并发性,并提出了「分页注意力」(Paged Attention)机制来实现非连续KV缓存,并增加整个系统的总吞吐量。
此技术采用分页缓存机制,从而提升了系统的整体吞吐量。不同于之前分配各个不同大小的连续内存块的做法,分块KV缓存中的底层存储是固定大小的块(也称为页面)。
分块KV缓存通过消除KV缓存引起的内存碎片化,增加了潜在的序列并发量,从而增加了系统吞吐量。非连续KV缓存也被HuggingFace TGI和NVIDIA TensorRT-LLM等框架所实现。
连续批处理
过去,动态批处理(服务器等待多个请求以同步处理)被用来提高GPU利用率。然而,这种方法有缺点,因为它通常需要将输入填充到相同长度或使系统等待以构建更大的批次(batch)。
近期大型语言模型(LLM)推理和服务的优化一直专注于细粒度调度和优化内存效率。例如,Orca提出了迭代级调度(也称为连续批处理),它在模型的每次前向传递时作出独特的调度决策。
这允许请求根据需要加入/离开批次,从而消除了填充请求的需要,提高了总体吞吐量。除了Orca,NVIDIA TRT-LLM、HuggingFace TGI和vLLM也实现了连续批处理。
在当前系统中,有两种主要方法来实现连续批处理。
- 在TGI和vLLM中,生成阶段被抢占以执行提示处理(在TGI中称为填充)然后继续生成。
- 在Orca中,这些阶段不被区分;相反,只要总序列数没有达到固定限制,Orca就会将提示加入正在运行的批次中。这两种方法都在不同程度上需要暂停生成以处理长提示。
为了解决这些缺点,我们提出了一种新颖的提示和生成组合策略,动态 SplitFuse。
动态SplitFuse:一种新颖的提示和生成组合策略
类似于现有的框架如TRT-LLM、TGI和vLLM,DeepSpeed-FastGen的目标是利用连续批处理和非连续KV缓存技术,以提升数据中心服务大型语言模型(LLM)的硬件利用率和响应速度。
为了实现更高的性能,DeepSpeed-FastGen提出了SplitFuse技术,它利用动态提示和生成分解,统一来进一步改善连续批处理和系统吞吐量。
A. 三个性能见解
在描述动态SplitFuse之前,我们回答三个关键的性能问题,这些问题解释了SplitFuse背后的逻辑。
1. 哪些因素影响单个LLM的前向传递?
为了有效地调度,我们必须首先了解调度过程中应考虑的独立变量有哪些。
我们观察到,在前向传递中序列的组成(序列中的批次大小)对性能的影响可以忽略不计。
这意味着我们可以围绕单一变量——即前向传递中的token数量——构建一个高效的调度器。
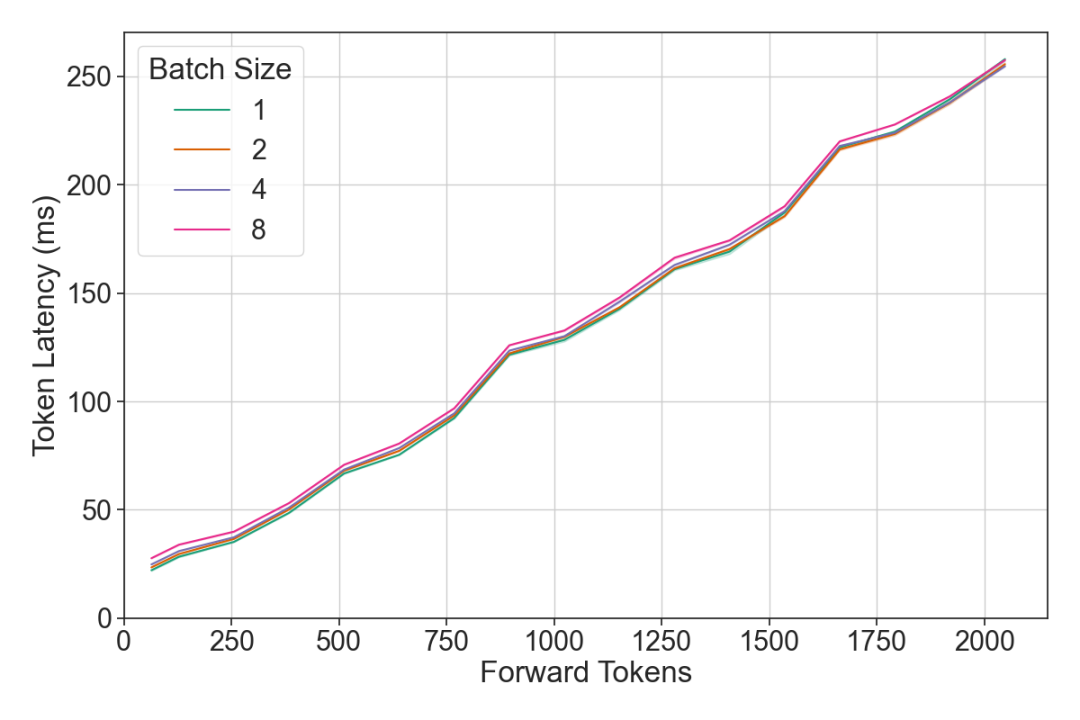
2. 模型的吞吐量与前向传递中token数量的关系如何?
一个LLM有两个关键的运行区间,并且过渡相对陡峭。
当token数量较少时,GPU的瓶颈是从内存中读取模型,因此吞吐量会随着token数量的增加而上升,而当token数量很多时,模型的吞吐量受GPU计算能力限制,吞吐量近乎恒定。
因此如果我们能将所有前向传递都保持在吞吐量饱和区间,则模型运行效率最高。
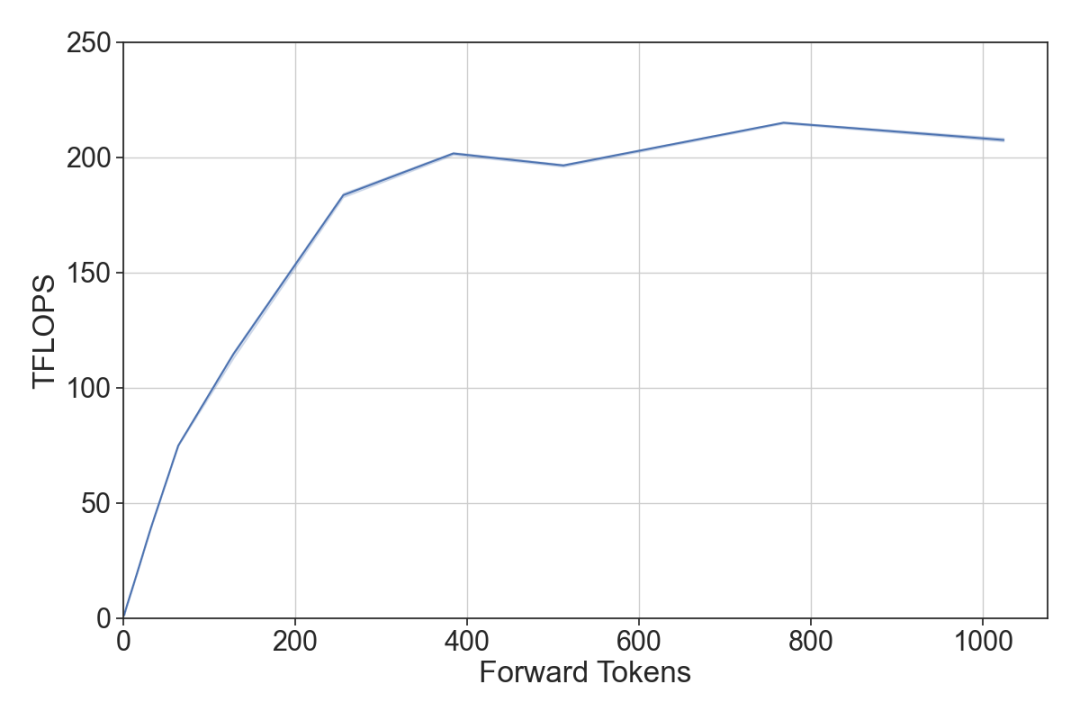
3. 如何在多个前向传递中调度一组token?
我们在上图中观察到,对于对齐良好的输入,token吞吐量曲线是凹的,这意味着第二导数必定小于或等于0。
设f(x)为给定模型的延迟至吞吐量的凹函数。则对于凹函数f(x),以下关系成立:

这表明,对于给定的2x个总token来说,最大化吞吐量的方式是将它们均匀分割到两个批次之间。
更一般地说,在一个系统中,如果要在F个前向传递中处理P个token,最理想的分区方案是均匀分配它们。
B. 动态分割融合(Dynamic SplitFuse)
动态分割融合是一种用于提示处理和token生成的新型token组成策略。
DeepSpeed-FastGen利用动态分割融合策略,通过从提示中取出部分token并与生成过程相结合,使得模型可以保持一致的前向传递大小(forward size)。
具体来说,动态分割融合执行两个关键行为:
将长提示分解成更小的块,并在多个前向传递(迭代)中进行调度,只有在最后一个传递中才执行生成。短提示将被组合以精确填满目标token预算。
即使是短提示也可能被分解,以确保预算被精确满足,前向大小(forward sizes)保持良好对齐。
动态分割融合(Dynamic SplitFuse)提升了以下性能指标:
- 更好的响应性:
由于长提示不再需要极长的前向传递来处理,模型将提供更低的客户端延迟。在同一时间窗口内执行的前向传递更多。
- 更高的效率:
短提示的融合到更大的token预算使模型能够持续运行在高吞吐量状态。
- 更低的波动和更好的一致性:
由于前向传递的大小一致,且前向传递大小是性能的主要决定因素,每个前向传递的延迟比其他系统更加一致。
生成频率也是如此,因为DeepSpeed-FastGen不需要像其他先前的系统那样抢占或长时间运行提示,因此延迟会更低。
因此,与现有最先进的服务系统相比,DeepSpeed-FastGen将以允许快速、持续生成的速率消耗来自提示的token,同时向系统添加token,提高系统利用率,提供更低的延迟和更高的吞吐量流式生成给所有客户端。
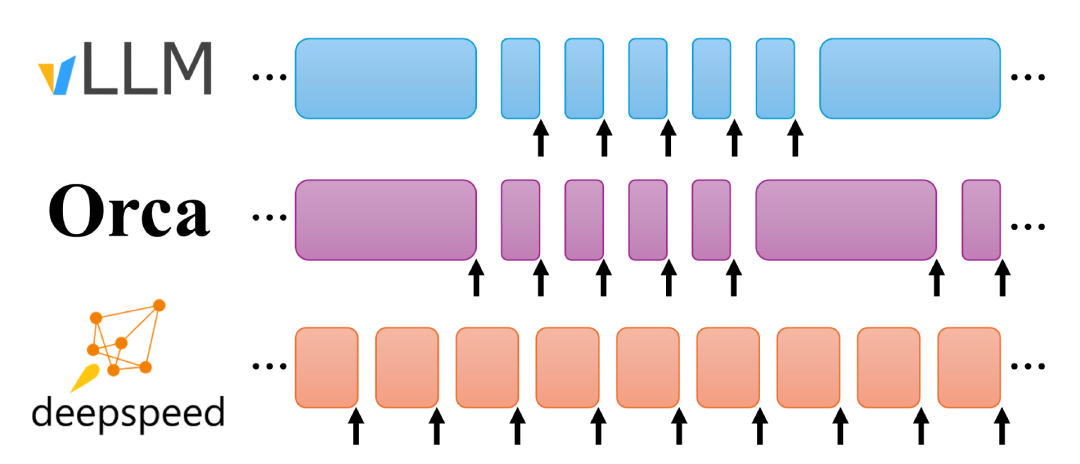
图 1:连续批处理策略的示意图。每个块显示一个前向传递的执行。箭头表示前向传递有一或多个token生成。vLLM在一个前向传递中要么生成token要么处理提示;token生成抢占提示处理。Orca在生成过程中以完整长度处理提示。DeepSpeed-FastGen动态分割融合则执行固定大小批次的动态组合,包括生成和提示token
性能评估
DeepSpeed-FastGen利用分块KV缓存和动态分割融合连续批处理,提供了最先进的LLM服务性能。
我们以下述的基准测试方法对DeepSpeed-FastGen和vLLM在一系列模型和硬件配置上进行评估。
A. 基准测试方法论
我们采用两种主要的定量方法来衡量性能。
吞吐量-延迟曲线:生产环境的两个关键指标是吞吐量(以每秒请求计)和延迟(每个请求的响应性)。
为了衡量这一点,我们模拟了多个客户端(数量从1到32不等)同时向服务器发送请求(总计512个)的情况。每个请求的结果延迟在端点测量,吞吐量通过完成实验的端到端时间来测量。
有效吞吐量:诸如聊天应用程序之类的交互式应用程序可能有比上述指标(如端到端延迟)更严格和复杂的要求。
以越来越受欢迎的聊天应用为例:
用户通过发送提示(输入)来开始对话。系统处理提示并返回第一个token。随着生成的进行,后续token被流式传输给用户。
在这个过程的每个阶段,系统都有可能提供不利的用户体验;例如,第一个token到达得太慢;或生成似乎停止了一段时间。
我们提出了一个考虑这两个维度的SLA框架。
由于提示和生成文本的长度差异很大,影响计算成本,因此设定同一个SLA值对于吞吐量和延迟是不切实际的。
因此,我们将提示延迟的SLA定义为「|提示中的token|/512」秒(=512 token/秒)。
此外,考虑到人类的阅读速度,我们将生成延迟的SLA设置在指数移动平均(EMA)上为2、4或6 token/秒。能够达到这些SLA的请求被认为是成功的,这些成功请求的吞吐量被称为有效吞吐量。
我们通过在NVIDIA A100、H100和A6000上运行Llama-2 7B、Llama-2 13B和Llama-2 70B对vLLM和DeepSpeed-FastGen进行了评估。
B. 吞吐量-延迟分析
在这个实验中,DeepSpeed-FastGen在吞吐量和延迟方面都优于vLLM,在相同的延迟下DeepSpeed-FastGen的吞吐量更大;在相同的吞吐量下DeepSpeed-FastGen的响应延迟更小。
如图2所示,在Llama-2 70B运行于4个A100-80GB的情况下,DeepSpeed-FastGen展示了高达2倍的吞吐量(1.36 rps对比0.67 rps)在相同的延迟(9 秒)下;或高达50%的延迟减少(7秒对比14秒)同时实现相同的吞吐量(1.2 rps)。
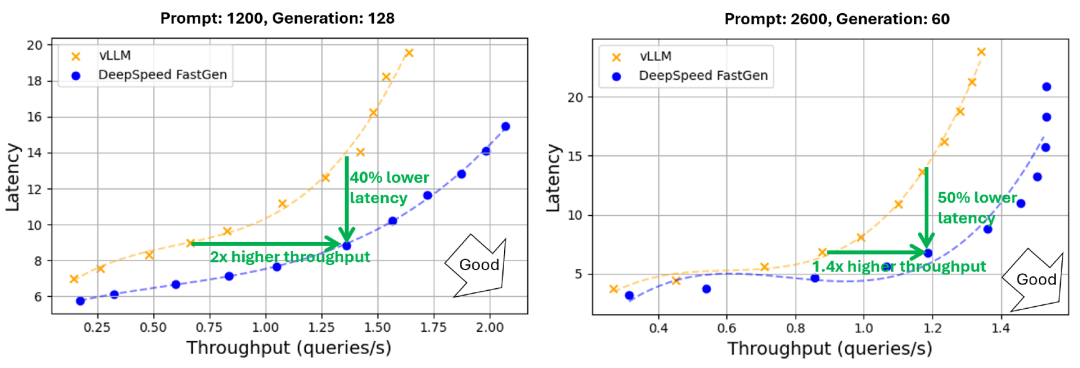
图 2:使用Llama 2 70B进行文本生成的吞吐量和延迟(使用4个A100-80GB GPU的张量并行)。提示和生成长度遵循正态分布,平均值分别为1200/2600和128/60,方差为30%
评估Llama-2 13B时DeepSpeed-FastGen也呈现了这些趋势,如图3所示。
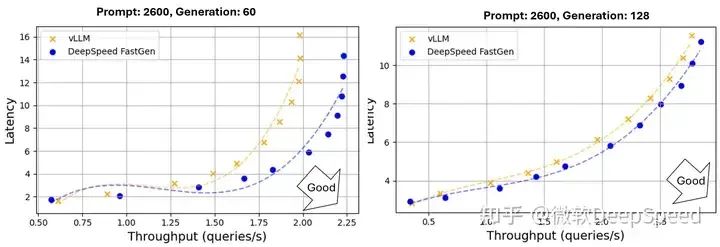
图 3:使用Llama 2 13B进行文本生成的吞吐量和延迟(A100-80GB GPU,无张量并行)。提示和生成长度遵循正态分布,平均值分别为1200/2600和60/128,并且有30%的方差
C. 有效吞吐量分析
在考虑了首个token的延迟和生成速率的有效吞吐量分析下,DeepSpeed-FastGen提供的吞吐量比vLLM高出多达2.3倍。
图4展示了DeepSpeed-FastGen和vLLM的有效吞吐量的比较分析。每个绘制的点表示从特定数量的客户端得出的有效吞吐量。
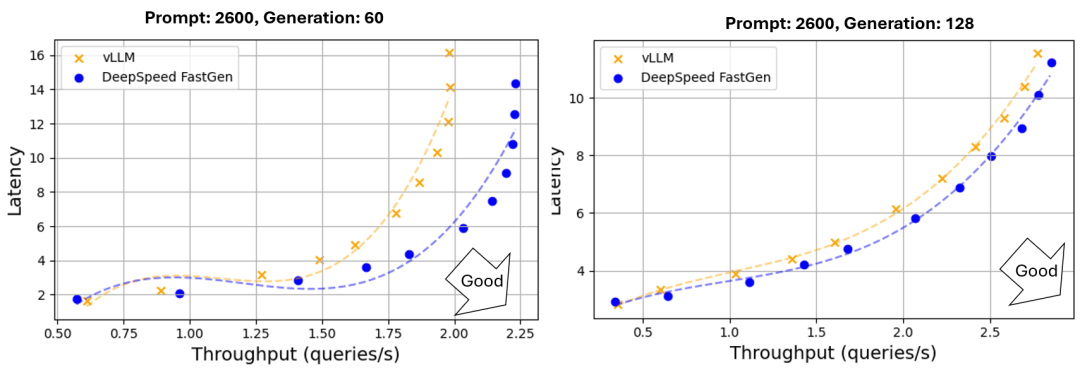
图 4:DeepSpeed-FastGen和vLLM的有效吞吐量(Llama 2 70B/A100-80GB使用张量并行在4个A100-80GB GPU上。提示和生成长度遵循正态分布,平均值分别为2600和60,并且有30%的方差)
当我们扩大客户端数量时,我们最初观察到有效吞吐量的增加。然而,当客户端数量接近系统容量时,延迟也显著增加,导致许多请求未能满足SLA。
因此,有效吞吐量将在某个点上饱和或减少。从可用性角度来看,达到最大有效吞吐量所需的客户端数量并不特别重要;线条的最高点是最优的服务点。
当vLLM抢占正在进行的先前请求的生成时,生成延迟会明显增加。这导致vLLM的有效吞吐量看起来低于其直接测量的吞吐量。
在vLLM的峰值时,有效吞吐量为0.63查询/秒,大约28%的请求未能满足4 token/秒的SLA。在相同的SLA下,DeepSpeed-FastGen达到了1.42查询/秒(不到1%的请求未能满足SLA),这是vLLM的2.3倍。
D. token级时间分析
图5显示了生成过程的P50、P90和P95延迟。vLLM和DeepSpeed-FastGen展示了类似的P50延迟,但vLLM的P90和P95延迟显著更高。
这种差异是由于vLLM在抢占正在进行的生成以处理新提示时,生成延迟出现显著增加所导致的。
相比之下,DeepSpeed-FastGen通常会同时处理之前请求的提示和生成,导致生成延迟更加一致。
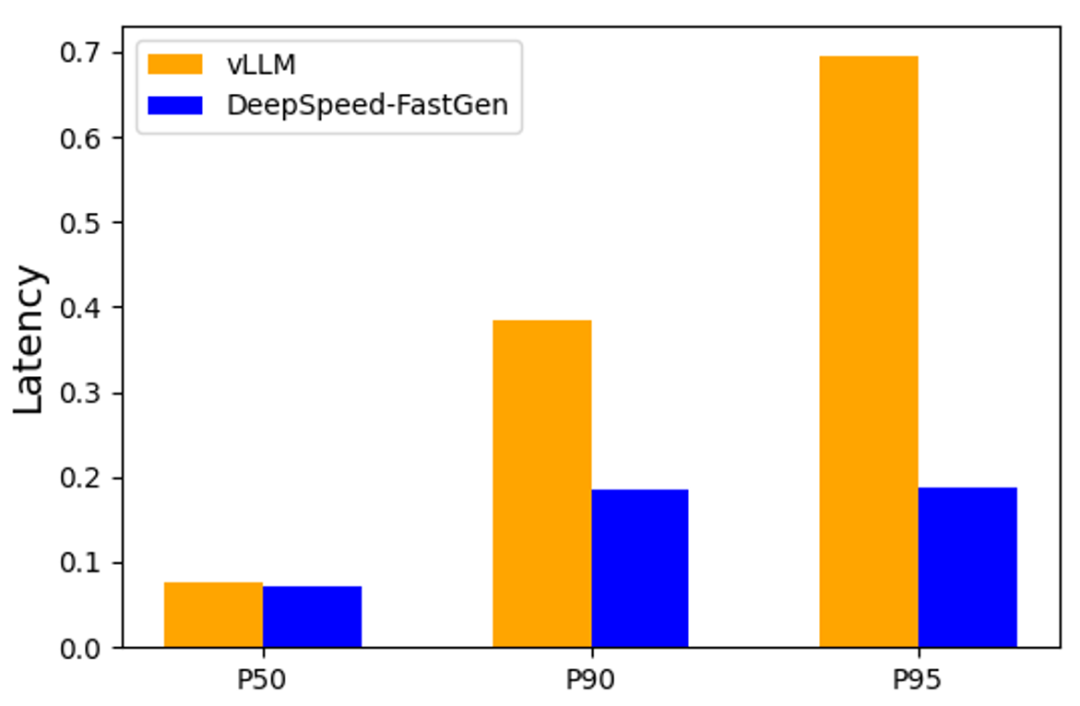
图 5:使用张量并行在4个A100-80GB GPU上的Llama 2 70B/A100-80GB的每token生成延迟,16客户端。提示和生成长度遵循正态分布,平均值分别为2600和128,并且有30%的方差。
E. 使用负载均衡的可扩展性
DeepSpeed-FastGen提供了副本级负载均衡,可以将请求均匀分布在多个服务器上,让您轻松扩展应用程序。
图6展示了DeepSpeed-FastGen在使用负载均衡器和最多16个副本时的可扩展性。请注意,我们使用了4个A100 GPU来计算每个Llama 2 70B模型。
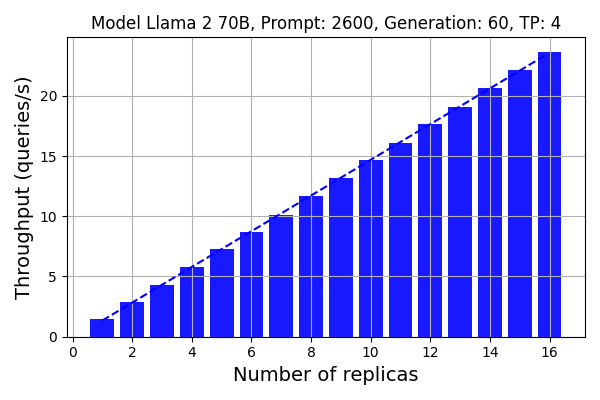
图 6:使用负载均衡功能的可扩展性。提示和生成长度遵循正态分布,平均值分别为2600和60,并且有30%的方差
结果展示了DeepSpeed-FastGen几乎完美的可扩展性。
单个副本时DeepSpeed-FastGen的吞吐量为1.46查询/秒,而16个副本的吞吐量达到了23.7查询/秒,与单个副本相比标志着线性的16倍增长。
F. 其他硬件平台
除了对A100的深入分析,我们还提供了H100和A6000的基准测试结果。在A6000和H100上观察到的性能趋势与A100相同。
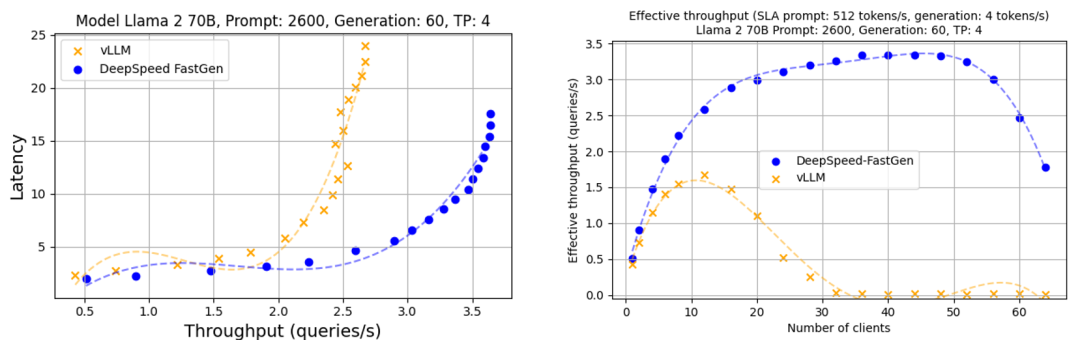
图 7:使用8个H100 GPU的Llama 2 70B的吞吐量-延迟曲线和有效吞吐量。提示和生成长度遵循正态分布,平均值分别为2600和60,并且有30%的方差
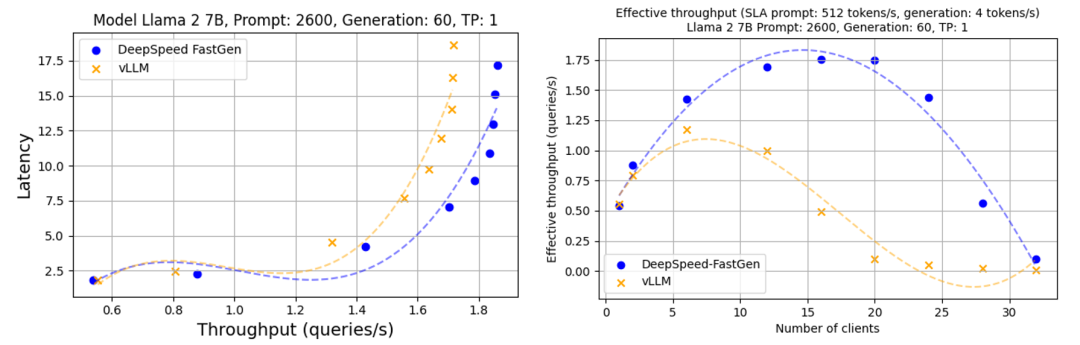
图 8:使用A6000的Llama 2 7B的吞吐量-延迟曲线和有效吞吐量。提示和生成长度遵循正态分布,平均值分别为2600和60,并且有30%的方差
软件实现与使用指南
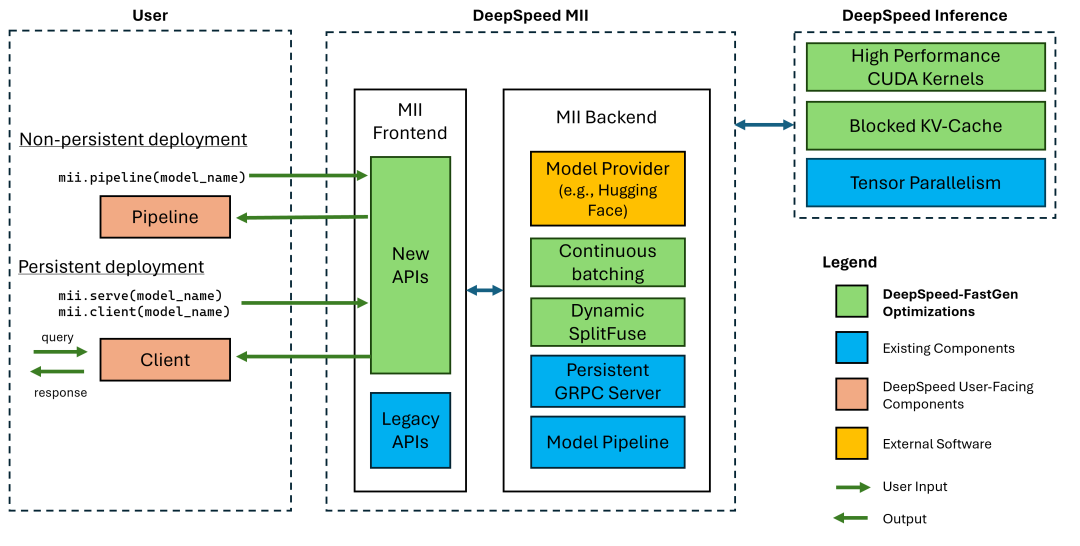
DeepSpeed-FastGen是DeepSpeed-MII和DeepSpeed-Inference的协同组合,如下图所示。
两个软件包共同提供了系统的各个组成部分,包括前端API、用于使用动态SplitFuse调度批次的主机和设备基础设施、优化的内核实现,以及构建新模型实现的工具。
alpha版DeepSpeed-FastGen最快的入门方式是:pip install deepspeed-mii
A. 支持的模型
在DeepSpeed-FastGen的当前alpha版本中,我们目前支持以下模型架构:LLaMA和LLaMA-2MistralOPT
所有当前模型都利用了后端的HuggingFace API来提供模型权重和模型对应的分词器。
我们计划在最初发布后的几周和几个月内添加更多模型。如果您希望支持特定的模型架构,请提交问题来让我们知道。
B. 部署选项
以下所有示例均可在DeepSpeedExamples中运行。安装后,您有两种部署方式:交互式非持久管道或持久化服务部署:
非持久管道
非持久管道部署是快速入门的好方法,只需几行代码即可完成。非持久模型只在您运行的python脚本期间存在,适用于临时交互式会话。
from mii import pipeline
pipe = pipeline("mistralai/Mistral-7B-v0.1")
output = pipe(["Hello, my name is", "DeepSpeed is"], max_new_tokens=128)
print(output)持久部署
持久部署非常适合用于长时间运行和生产的应用。持久部署使用了轻量级的GRPC服务器,可以使用以下两行代码创建:
import mii
mii.serve("mistralai/Mistral-7B-v0.1")上述服务器可以同时被多个客户端查询,这要归功于DeepSpeed-MII内置的负载平衡器。创建客户端也只需要两行代码:
client = mii.client("mistralai/Mistral-7B-v0.1")
output = client.generate("Deepspeed is", max_new_tokens=128)
print(output)持久部署可以在不再需要时终止:
client.terminate_server()C. 高级安装方式
为了使用方便并显著减少许多其他框架所需的冗长编译时间,我们通过名为DeepSpeed-Kernels的新库分发了覆盖我们大部分自定义内核的预编译 Python wheel。
我们发现这个库在环境中非常便携,只要这些环境具有NVIDIA GPU计算能力 8.0+(Ampere+)、CUDA 11.6+和Ubuntu 20+。
在大多数情况下,您甚至不需要知道这个库的存在,因为它是DeepSpeed-MII的依赖项,并将自动与之一起安装。然而,如果您因任何原因需要手动编译我们的内核,请参阅我们的高级安装文档。
转载自微软DeepSpeed组官方知乎账号:zhihu.com/people/deepspeed























