写在前面&个人理解
看到了一篇很不错的工作,这里和大家分享下!关于Occupancy+World Model,不得不说,它结合了当下最火的两个方向,值得一读。3D场景如何演变对于自动驾驶决策至关重要,现有的方法都是通过预测目标框的移动来实现,而目标框无法捕捉到更细粒度的场景信息。这里探索了一种在3D占用空间中学习世界模型OccWorld的新框架,同时预测自车的运动和周围scene的演变。对于场景理解任务来说,更建议学习基于3D占用而不是3D bounding box和分割maps的世界模型,原因有三:
1) 表征能力,3D占用可以描述场景的更细粒度的3D结构;
2) 效率,3D占用能够更经济地获得(例如从稀疏的LiDAR点)
3) 多功能性,3D占用可以适应视觉和激光雷达。
为了便于对世界进化进行建模,Occworld主在学习一种基于重建的3D占用场景标记器,以获得离散的场景标记来描述周围的场景!采用类似GPT的时空生成transformer来生成后续场景和ego tokens,以解码未来的占有率和ego轨迹。在nuScenes基准上进行的大量实验证明了OccWorld有效模拟驾驶场景演变的能力,OccWorld还可以在不使用实例和地图监督的情况下生成有竞争力的规划结果。

领域发展与现状
近年来,自动驾驶已被广泛探索,并在各种场景中显示出不错的结果。虽然基于激光雷达的模型由于其对结构信息的捕获,通常在3D感知中表现出强大的性能和鲁棒性,但更经济的以硬件为中心的解决方案已经大大赶上了深度网络感知能力的提高。预测未来场景演变对自动驾驶汽车的安全性很重要,大多数现有方法遵循传统的感知、预测和规划流程。感知旨在获得对周围场景的语义理解,如3D检测和语义图构建。后续预测模块捕获其他交通参与者的运动,然后规划模块根据先前的输出做出决策。
然而,这种串行设计通常在训练的每个阶段都需要GT,但实例级box和高清晰度地图很难标注。此外,它们通常只预测目标边界框的运动,无法捕捉到有关3D场景的更细粒度的信息。
Occworld是一种新的范式,可以同时预测周围场景的演变,并规划自动驾驶汽车的未来轨迹。OccWorld是一个三维语义占用空间中的世界模型,来对驾驶场景的发展进行建模。它采用3D语义占用作为场景表示,而不是传统的3D框和分割图,它可以描述场景的更细粒度的3D结构。此外,3D占用率可以从稀疏的激光雷达点中有效地学习,因此是描述周围场景的一种潜在的更经济的方式。
为了实现这一点,首先使用矢量量化变分自动编码器(VQVAE)来细化high-level concepts,并以自监督的方式获得离散场景tokens。然后,定制了生成预训练transformer(GPT)架构,并提出了一种时空生成transformer来预测随后的场景token和ego tokens,以分别预测未来的占有率和自ego轨迹。首先执行空间混合来聚合场景tokens,并获得多尺度tokens来表示多个级别的场景。然后,将时间注意力应用于不同级别的tokens,以预测下一帧的token,并使用U-net结构对其进行集成。最后,我们使用经过训练的VQVAE解码器将场景标记转换为占用空间,并学习轨迹解码器以获得ego规划结果!
一些相关的任务介绍
3D占用预测:3D占用预测旨在预测3D空间中的每个体素是否被占用以及其语义标签是否被占用。早期的方法利用激光雷达作为输入来完成整个3D场景的3D占用。最近的方法开始探索更具挑战性的基于视觉的3D占用预测或应用视觉backbone来有效地执行基于激光雷达的3D占用预测。3D占用提供了对周围场景的更全面的描述,包括动态和静态元素。它也可以从稀疏累积的多次激光雷达数据或视频序列中有效地学习。然而,现有的方法只关注于获得三维语义占用,而忽略了其时间演变,这对自动驾驶的安全至关重要。
自动驾驶的世界模型:世界模型在控制工程和人工智能领域有着悠久的历史,通常被定义为在给定动作和过去的情况下产生下一个场景观察。深度神经网络的发展促进了深度生成模型作为世界模型的使用。基于StableDiffusion等大型预训练图像生成模型,可以生成不同场景的逼真驾驶序列。然而,它们在2D图像空间中产生未来的观测结果,缺乏对3D周围场景的理解。其他一些方法使用未标记的激光雷达数据来探索预测点云,这些方法忽略了语义信息,无法应用于基于视觉或基于融合的自动驾驶。考虑到这一点,Occworld在3D占用空间中探索了一个世界模型,以更全面地模拟3D场景的演变!
端到端自动驾驶:自动驾驶的最终目标是基于对周围场景的观察来获得控制信号。最近的方法遵循这一概念,在给定传感器输入的情况下输出ego汽车的规划结果。它们大多遵循传统的感知、预测和规划流程。通常首先执行BEV感知以提取相关信息(例如,3D agent框、语义map、轨迹),然后利用它们来推断agent和ego的未来轨迹。Occworld提出了一个世界模型来预测周围动态和静态元素的演变!
Occworld结构

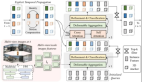
图2:用于三维语义占用预测和运动规划的OccWorld框架。
采用类似GPT的生成架构,以自回归方式从先前场景预测下一个场景,通过两个关键设计使GPT适应自动驾驶场景:
1) 训练3D占用场景标记器来产生3D场景的离散高级表示;
2) 在空间-时间因果自注意之前和之后进行空间混合,以有效地产生全局一致的场景预测,分别使用GT和预测场景标记作为后代的输入进行训练和推理。
1)自动驾驶中的World Model
自动驾驶旨在完全防止或部分减少人类驾驶员的行为,形式上自动驾驶的目标是在给定传感器输入的情况下,获得当前时间戳T的控制命令(例如,油门、转向、制动)。由于从轨迹到控制信号的映射高度依赖于车辆规格和状态,因此通常假设给定的令人满意的控制器,因此重点关注ego车辆的轨迹规划。一个自动驾驶模型A然后将传感器输入和来自过去T帧的ego轨迹作为输入,并预测未来f帧的ego trajectory :
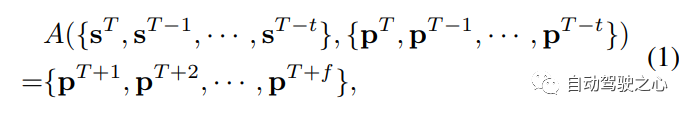
自动驾驶的传统pipeline通常遵循感知、预测和规划的设计,感知模块per感知周围场景,并从输入传感器数据s中提取高级信息z。预测模块Pre集成高级信息z以预测场景中每个agent的未来轨迹ti。规划模块pla最终处理感知和预测结果{z,{ti}},以规划ego车辆的运动,常规pipeline可以公式化为:
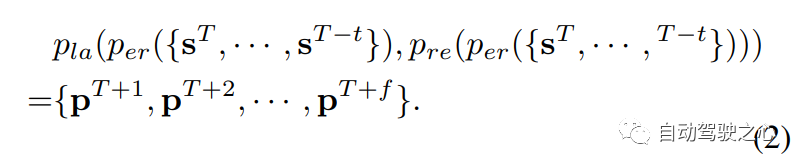
尽管该框架具有良好的性能,但它通常需要在每个阶段进行监督,标注很困难。而且它只考虑目标级别的移动,没有更细粒度的演进建模。受此启发,Occworld探索了一种新的基于世界模型的自动驾驶范式,以全面模拟周围场景的演变和自我运动。受生成预训练transformer(GPT)在自然语言处理(NLP)中最近取得的成功的启发,Occworld提出了一种用于自动驾驶场景的自回归生成建模框架。定义了一个世界模型w来作用于场景表示y,并能够预测未来的场景。形式上,将世界模型w的函数公式化如下:
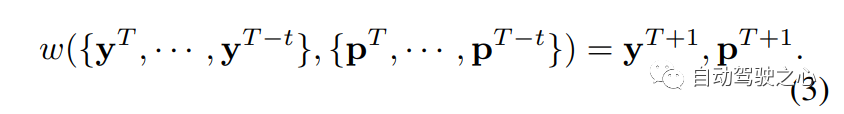
在获得预测场景和ego位置后,可以将它们添加到输入中,并以自回归的方式进一步预测下一帧,如图2所示,考虑到它们的高阶相互作用,世界模型w捕捉到了周围场景和ego载体进化的联合分布!
2)3D占用场景标记器
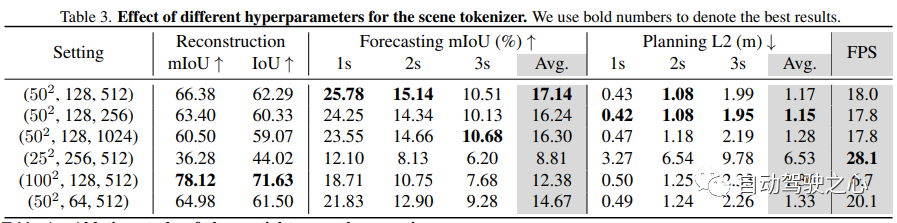
由于世界模型w对场景表示y进行操作,因此其选择对世界模型的性能至关重要。根据三个原则选择y:
1)expressiveness,它应该能够全面地包含3D场景的3D结构和语义信息;
2) 效率,学习应该是经济的(例如,弱监督或自监督中学习);
3) 多功能性,它应该能够适应视觉和激光雷达模式。
考虑到上述所有原理,建议采用3D占用作为3D场景表示。3D占用将自车周围的3D空间划分为H×W×D体素,并为每个体素分配一个标签l,表示它是否被占用以及被哪个类别占用。3D占用提供了3D场景的密集表示,并且可以描述场景的3D结构和语义信息。它可以从稀疏激光雷达注释或可能从时间帧的自监督中有效地学习。3D占有率也是模态认知的,可以从单目相机、surround相机或激光雷达中获得。
尽管3D占有率很全面,但它只提供了对场景的低级理解,很难直接模拟其演变。因此,Occworld提出了一种自监督的方法,将场景标记为来自3D占用的高级标记。在y上训练矢量量化自动编码器(VQ-VAE),以获得离散标记z,从而更好地表示场景,如图3所示。
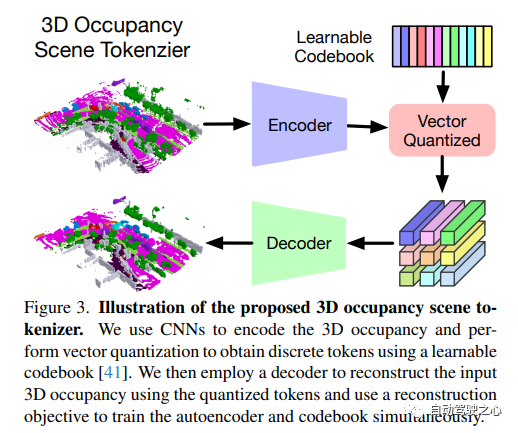
3)Spatial-Temporal Generative Transformer
自动驾驶的核心在于预测周围世界如何演变,并相应地规划自车运动。虽然传统方法通常分别执行这两项任务,但建议学习一个世界模型w来联合建模场景进化和ego轨迹的分布。
如(3)中所定义的,世界模型w将过去的场景和ego位置作为输入,并在一定时间间隔后预测它们的结果。基于表现力、效率和多功能性,采用3D占用y作为场景表示,并使用自监督标记器来获得高级场景标记T={zi}。为了整合ego运动,进一步将T与自我标记聚合,以编码ego车辆的空间位置!然后,所提出的OccWorld w在世界标记T上起作用,其可以公式化为:
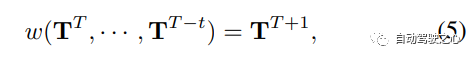
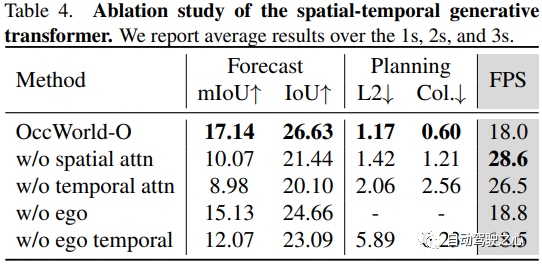
其中T是当前时间戳,并且T是可用的历史帧的数量。应考虑每个时间戳内世界tokens的空间关系和不同时间戳之间tokens的时间关系,以全面模拟世界变化。因此,Occworld提出了一种时空生成transformer架构,以有效地处理过去的世界tokens并预测下一个未来,如图4所示!
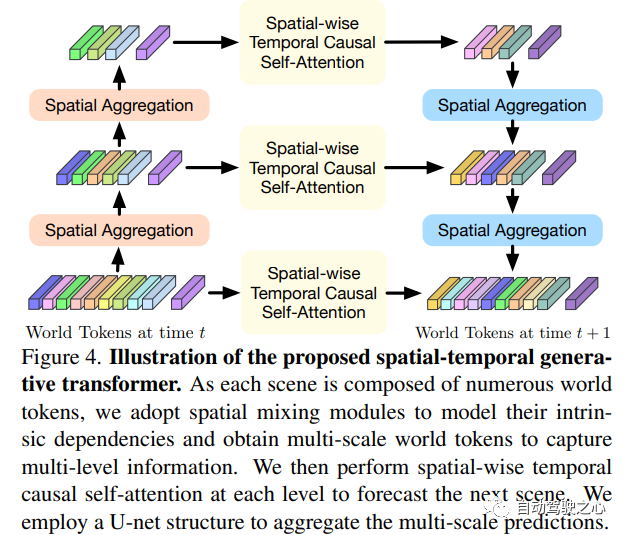
时空生成transformer 可以在考虑每个时间内和跨时间的世界tokens联合分布的情况下,在行驶序列中对世界变化进行建模。时间注意力预测周围区域中固定位置的演变,而空间聚合使每个token都意识到全局场景。
4)OccWorld
采用两阶段的训练策略来训练OccWorld。对于第一阶段,使用3D占用损失训练场景tokenizer e和解码器d:
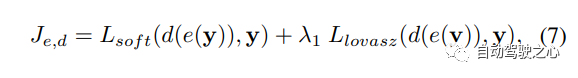
对于第二阶段,采用学习的场景tokenizer e来获得所有帧的场景标记z,并约束预测tokes z^和z之间的差异。
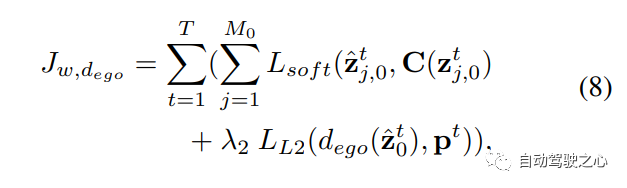
为了有效训练,使用场景标记器e获得的标记作为输入,但应用masked 的时间注意力来阻止未来tokens的效果。在推理过程中,逐步预测下一个帧。
实验对比分析
进行了两项任务来评估OccWorld:在Occ3D数据集上进行4D占用预测和在nuScenes数据集上执行运动规划!
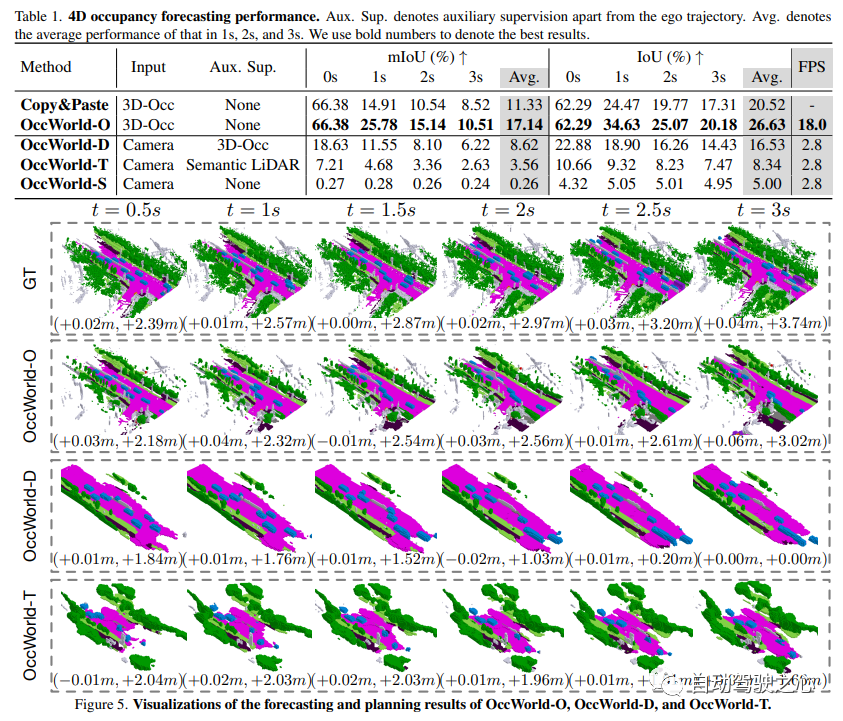
4D occupancy forecasting:3D占用预测旨在重建周围空间中每个体素的语义占用,无法捕捉3D占用的时间演变。这里探讨了4D occupancy forecasting任务,该任务旨在给定一些历史occupancy 输入的情况下预测未来的3Doccupancy,使用mIoU和IoU作为评估度量。
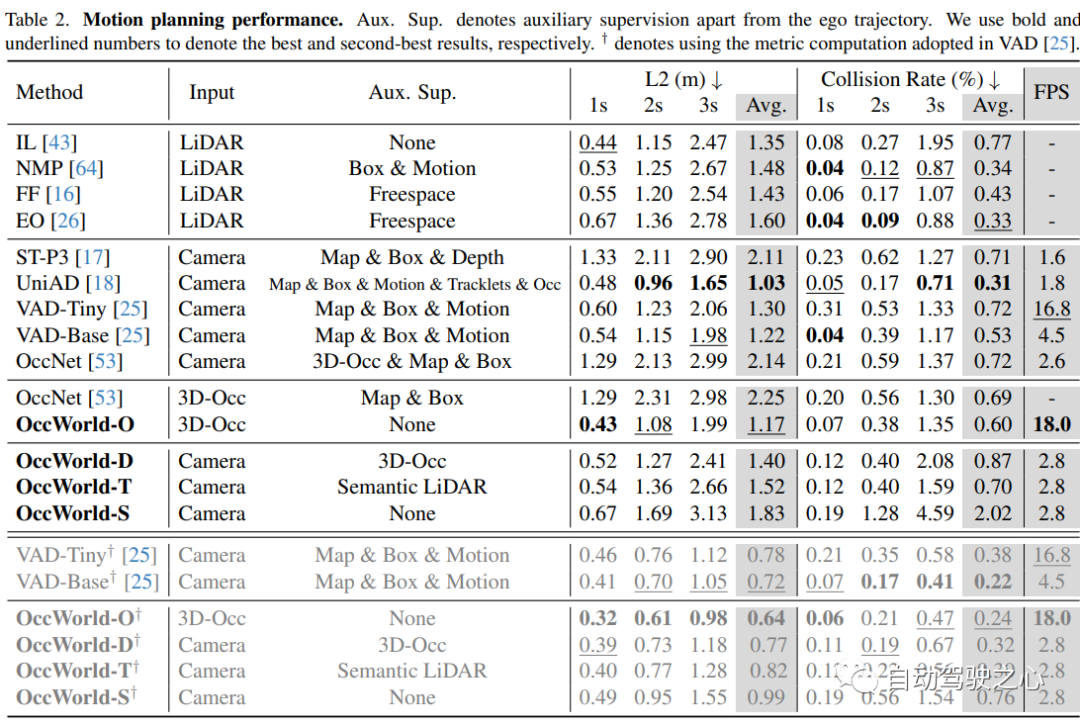
运动规划:运动规划的目标是在给定GT周围信息或感知结果的情况下,为自动驾驶车辆产生安全的未来轨迹。规划轨迹由BEV平面中的一系列2D waypoints 表示,这里使用L2 error和碰撞率作为评估度量。
结果如下: