一、百度视频背景介绍
1、统一产品形态

一方面,百度 APP 的所有视频场景已经升级成统一的沉浸式(上下滑)交互形态;另一方面,基于百度统一的大模型,我们打通了所有场景的数据和推荐体验。交互和数据的统一可以更好地实现生态共赢,促进百度视频的长远发展。
为了更好地培养用户对视频的消费习惯,我们还打造了一个视频消费的一级入口(底部导航栏入口)。大家如果有兴趣可以去下载百度 APP,有好的建议和 badcase 随时欢迎反馈给我们。
2、搜+推双引擎满足用户需求
值得一提的是,百度是做搜索起家,搜索的使用率极高,在推荐场景中需要更好地使用搜索的数据,通过”搜+推”双引擎来满足用户的需求。搜索主要是“人找内容”,用户会明确地输入自己的需求,而推荐是“内容找人”。将搜索的信号和推荐的信号进行跨域整合,做到更好的推搜融合,这也是百度的优势之一。

二、推荐系统概述
1、推荐系统解决的问题

考虑到不少听众非推荐背景,简单介绍下推荐要解决的问题。推荐平台有三个player:
- 用户:在这里探索世界、发现新的感知。
- 创作者:平台推荐的基础,为平台提供内容供给;平台为其提供广阔的空间,激发他们无限的灵感和创作。
- 广告主:提供平台生存下去的资金支持,大部分平台都是以广告为生。
推荐平台希望实现生产、消费和收入的良性循环,推荐系统作为平台的核心部件,主要解决两方面的问题:
- 优胜劣汰的内容选择机制(B 端):优质的内容如何获得更多的分发,留住优质的创作者。
- 极致的用户消费体验(C 端):只有用户诉求得到满足了,才能促进规模上的持续提升。
这是推荐系统的两个使命,我们后面设计目标的时候也会综合考虑这两个方面。
2、推荐系统概览

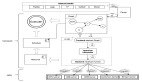
推荐系统的流程大致如下:审核后的资源会先推送到存储 meta 信息的统一正排库;推荐系统收到请求后,先通过图引擎、多目标召回等,召回相关资源;召回之后会经过两轮排序,分别为粗排和精排,再经过多目标的融合模型,选出一些与用户强相关的内容;最后通过多样性感知、序列建模、流量分配机制等策略,生成一个视频列表,下发到用户的手机。
接下来的分享将主要集中在精排的目标设计和模型的融合上。
三、多目标的设计和建模
首先介绍视频推荐的多目标设计。
1、目标设计的思考

先请大家思考一下视频沉浸式的场景下,如何设计推荐系统的目标呢?
传统的推荐系统中,通过点击内容或者视频进行消费,用户用点击行为明确表达了对这条资源的喜欢。因此在传统的推荐场景下,点击是非常重要的信号,是一个明确且简单的反馈。但是在沉浸式的场景下缺乏明确的反馈,用户的喜欢通过“隐藏”的行为表现出来,消费时长成为沉浸式推荐场景非常重要的信号。

除了上述消费时长以外,还需要考虑用户在系统中主动留下的行为,比如关注、评论、分享、点赞。但这类行为数据相比播放数据是非常稀疏的,可能只有千分之一这个量级。
除了这些交互信号以外,在百度 APP 的推荐里面还有一部分很重要的数据就是搜索信号,在百度 70% 的用户既会消费推荐信息流,又会用搜索,因此推荐系统也需要刻画用户搜索域的满意度信号。
除了 C 端让用户更满意的消费信号以外,B 端的创作者则需要一套优胜劣汰的机制,实现劣质作者的筛选,激发优质作者的持续创作潜力,才能实现生产和消费的良性循环。
2、目标设计考虑的维度

从推荐系统角度看,用户就是样本标注员,用户有一些明确的正向表达,比如播放、点赞、收藏、评论等行为;还有一些明确的负向表达,比如 Dislike、负向评论、举报等等。除了明确表达,用户还会有一些隐式的表达,比如通过完播、播放时长、作者页消费、阅读相关推荐等表达出的喜欢,或是通过短播、快速跳出等表达出的不喜欢。因此在设计目标的时候,要全方面地思考,平衡明确的信号和隐式的信号,避免设计出一个“偏科”的推荐系统。
3、综合满意度建模

除了上述基础目标,我们还会设计一些高阶的目标,不再是简单地使用用户的反馈。举个例子,如上图右侧所示,我们上线了基于用户满意度反馈的模型。第一阶段,通过完播、时长这种稠密的信号,利用简单的规则或者模型去拟合用户的满意反馈,得到一个比较稠密的用户满意度 label。第二阶段,基于这个 label 建一个满意度模型,利用推搜全域大模型产生的 Embedding、文心底层 Embedding,以及用户画像和行为序列特征建模,以评估推荐域相对于搜索域的满意度增益。如果某个兴趣点用户在搜索里消费过了,推荐系统可以基于该满意度模型推荐出更优质的内容,这样就可以使搜推融合更加平滑,将搜索的兴趣更好地迁移到 Feed。
4、长期价值建模(Long Term Value)

前文介绍的是如何预估当前内容的播放时长和互动,将用户的历史消费行为作为样本或者特征,预测即将推出的内容是正反馈还是负反馈,以及是否会有互动和消费的满意情况。
进一步思考,用户未来消费的内容与当前消费的这条内容是否存在关系?比如用户当前看的是郭德纲的视频,如果接下来第 N 天还消费了于谦的视频,于谦视频是否是由郭德纲视频“激发”的呢?未来兴趣点的消费是否可以认为是当前兴趣点的“延续”呢?结果是肯定的。因此我们在系统中引入了 LTV 的体系,将未来长期价值的内容归因到当前的视频推荐上来。

假设 V0 是当前视频的价值,V1,V2,… Vn 是用户未来消费的视频,假设 V2 和 Vn 是满意的消费,并且是 V0 的一个延续,就可以将其归因到V0 。
归因方式有多种,根据百度 Feed 的业务场景,归因包括以下三大块:
- 功能的归因:如通过相关推荐看了挂载的资源,那么这部分资源消费信号可以归因到 V0 上来。
- 召回关联的归因:如召回阶段是通过 itemCF 等隐式召回的。
- 相关性关联:如通过多模态 embedding 或者推荐大模型的 embedding 可以衡量资源之间的相关性,比如 Vn 和 V0 有比较高的相关性得分,就可以把 Vn 的价值归因到 V0 上来。
当然这个归因是有权重的,我们通过距离 V0 的时间间隔,和 V0 的相关性等因子来调节用户未来消费视频的归因权重,从而得到当前视频 V0 的长期价值。有了长期价值目标后,学习就比较简单了,首先是目标的归一化,然后直接建模即可。

简单总结一下,基于对业务现状的抽象和梳理,我们设计推荐系统目标时候会从下面三个方向入手:
- 多目标,首先进行基础物理目标建模,接下来是一些高阶目标的建模,刻画全场景的满意度,同时还需要对生态进行调控。
- 刻画未来的价值。
- 除了资源维度还可以考虑其他维度,例如作者维度的建模。
总之,推荐系统的目标要从多角度、各个发展方向综合地去考虑。
5、百度 Feed 模型技术变革联动体验进化

百度推荐场景发展到现在的三大场景:
- 「推荐」信息流:已经存在了很多年。
- 『发现』场景:相比之下,主 Feed 偏信息资讯,『发现』则更轻松活泼,贴近生活。
- 「沉浸式」场景:纯视频形态的消费流。
随着百度产品的演变,排序目标的预估也是逐步演进的。从一开始的单域的主目标到多域多目标,再到现在综合建模的全域综合多目标,把多域的样本整合到一起,充分共享信息。下面就来介绍全域的综合建模。
6、跨域多目标建模

首先来看下业界都做了哪些工作,无论是 MMoE、PLE,还是阿里在做的 STAR 网络、PEPNet 等这些结构,还有谷歌、腾讯等公司都在不遗余力地根据自己的业务设计各种各样的网络结构,希望在异构场景下共享更多有用的信息。其主要解两大问题:
- 跨域信号的迁移问题,如何在两个不同的域之间更好地迁移,实现跨域信息共享。
- 多目标之间负迁移的问题,即多目标的跷跷板效应。
同样百度推荐系统也面临这两个问题。

百度的场景下子域目标众多,且各目标之间的相关性较低,这容易导致多目标之间发生负迁移。为了解决这问题,需要分析不同目标间的 PNR,并找出它们之间的相关性差异。即异构场景下如何刻画用户信息,以及如何实现异构信息的迁移,是模型结构需要去解决的问题。
结合百度的业务,我们利用 Gating 结构设计了跨域分层多目标网络结构,主要分三层:首先是个性化 common 网络,作为底座;第二层是跨域的信息提取 GCG 网络;最后一层是子域的多目标网络,这样就可以在共享信息的同时,对每一个域都有一个多目标的预估。
这套方案与单域多目标相比有着显著提升,初次上线 AUC 约提升 3-9 个千分。如上图右下角所示,获取用户特征在多个域的 embedding,做了一个 TSNE 降维后,除了搜 C 和二跳这两个比较接近以外,其它两个场景的区分还是比较明显的,说明模型可以学到场景间的差异。搜 C 和二跳两个场景区别不大也是合理的,都是视频场景,用户的交互和兴趣也都差别不大。

百度业务场景有 40 多个物理目标,还有 4 个大的子域,6 种形态,包括视频、图文、动态、小程序等。我们希望模型在众多复杂业务中都能有较好的表现。简单介绍一下模型结构。第一层是 common 网络,作为分域的底座,筛选各个场景中多目标的满意样本,通过 gate 网络实现个性化 embedding 映射。第二层是域间信息的提取,将域内独有的特征和个性化共享特征通过 CGC 网络实现。两者共同构建了跨域的信息提取,其好处是既保留了域内的信息丰富度,同时又提取出了异构场景的共享信息。第三层是子域的多目标建模。这块我们还有对应的论文在发表中,对细节感兴趣的朋友可以看论文。
四、多目标融合

百度多目标融合的演进过程与业界也较为接近,首先是先验知识融合,简单直接,但是比较耗费人力。接着我们升级到了 LTR,效果明显,但弊端是业务变化的时候需要频繁调整,同时偏序关系也会随着业务和用户分层的变化而变化。之后我们也使用过多目标融合价值模型,采用序列最优的方法,短期使用后,就升级到了正在使用的方法—ES(Evolution Strategy)进化学习。

要使用 ES,首先要定义一个 Reward,即北极星指标。百度的 Reward 是 Session 的深度(时长+步长)和互动,时长和步长对应的业务指标是时长和视频播放量,这两个指标反映的是 LT,也就是用户的留存。除此以外,还有互动信息,代表了用户在 APP 中资产的沉淀,比如关注作者的行为,其实是期望这个作者再有更新后能够找到。无论是提升消费条数还是互动个数,都是希望用户更长远地使用这个 APP。
我们的第一版是一个简单的启发式的模型,当前线上的 ES 会做更高阶的计算,例如引入分场景、分人群等信息。