本文经自动驾驶之心公众号授权转载,转载请联系出处。
背景:
16-18年做过一阵子无人驾驶,那时候痴迷于移动规划;然而当时可学习的资料非常少,网上的论文也不算太多。基本就是Darpa的几十篇无人越野几次比赛的文章,基本没有成系统的文章和代码讲解实现。所以对移动规划的认识不算全面,这几年随着自动驾驶、无人机的研究和应用的增多,很多的论文课程成体系的开始介绍这方面的内容。对于一个理工男来说机器人并且是能自动的、智能规划的,相信没有多少理工男是可以抗拒不想去做进一步了解的。所以一直在收集资料,筹划这哪一天可以出一个这方面系列,然后在code一个项目出来在机器人上捣腾各种实现。再一次加速本人对这一想法落实是两年前看到fast-lab高飞团队出的一系列飞行走廊解决无人机路径规划的工作视频。第一次看到视频时候真被震惊到,移动规划原来还可以这么玩,如此优美的数学框架。讲了这么多只是想致敬过去的经历,开启这个专题第一讲。这个系列主线就是围绕高飞老师《移动机器人动态规划》课程讲稿,里面会补充一些算法细节和自己的思考。这个课程对移动规划体系框架构建非常棒,内容排布的也非常好,唯一缺憾就是对于动态不确定障碍物的规划会少一些,因为课程本来就是针对无人机设计的。
正文:
现代机器人学和自动驾驶等领域,路径规划是一个重要的主题. 它涉及到在给定的环境中找到从起点到终点的最优路径. 这个过程通常分为两个部分:前端路径搜索和后端轨迹规划. 前端路径搜索在地图中搜索出一条避开障碍物的轨迹,而后端轨迹规划则对搜索到的轨迹进行优化,使其符合机器人的运动学和动力学约束.
实环境中的机器人运动规划是一个比较复杂的问题,对于复杂的问题人类的解法一般都是分步求解:先做个大概、然后在大概轮廓上逐步的复杂精细。机器人运动规划的学院派解法也是如此:
1.前端:路径规划
- 基于搜索的方法
- 通用图搜索:深度优先搜索(DFS),广度优先搜索(BFS)
- Dijkstra 和 A* 搜索
- 跳点搜索
- 基于采样的方法
- 概率路线图(PRM)
- 快速探索随机树(RRT)
- RRT,有信息的 RRT
- 带动力学约束路径规划
- 状态-状态边界值最优控制问题
- 状态栅格搜索
- 动力学RRT*
- 混合A*
2.后端:轨迹生成
- 最小抖动轨迹生成
- 微分平坦性
- 最小抖动优化
- 最小抖动的闭式解
- 时间分配
- 实际应用
- 软硬约束轨迹优化
- 软约束轨迹优化
- 硬约束轨迹优化
3.不确定性状态求解:移动障碍物、突变环境、设备建模变化
- 基于马尔可夫决策过程的规划(MDP)
- 规划中的不确定性和马尔可夫决策过程
- 最小最大成本规划和期望成本最小规划
- 值迭代和实时动态规划
- 机器人规划的模型预测控制(MPC)
- 线性模型预测控制
- 非线性模型预测控制
前端——搜索路径规划
在开始这部分内容介绍前,需要介绍几个概念。介绍这几个概念的目的在于更贴近实际的去理解搜索在业务中应用。搜索路径规划中是把机器人当成一个质点来考虑的,然而实际的机器人是有一定形状和占用空间的,如果把机器人当成质点来考虑很可能是会搜索出一条实际上不可行的(会碰到障碍物的)路径的。为了解决这个问题呢,我们可以简单的物体的形状转移到地图(让地图障碍物区域加上物体占用空间)。在这样的地图里把机器人当成质点来搜索可行路径。
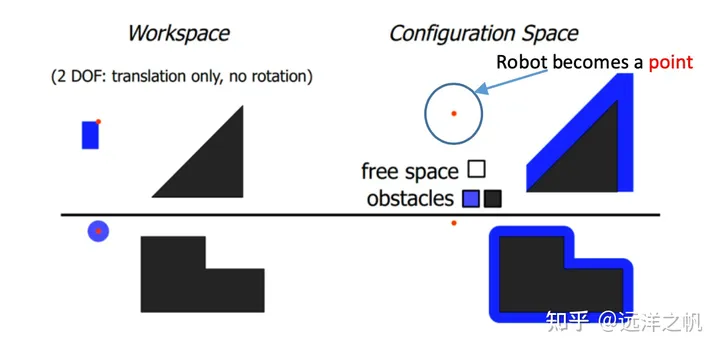
在配置空间中规划¹²³
- 机器人在C-space中被表示为一个点,例如,位置(在R3中的一个点),姿态(在 (3)中的一个点),等等⁴⁷⁸
- 障碍物需要在配置空间中表示(在运动规划之前的一次性工作),称为配置空间障碍物,或C-障碍⁴⁵⁶
- C-space = (C-障碍) ∪ (C-自由)⁴⁵⁶
- 路径规划是在C-自由中找到从起点qstart到目标点qgoal的路径⁹[10]¹⁵
在工作空间中
- 机器人有形状和大小(即,难以进行运动规划)
- 在配置空间:C-space中
- 机器人是一个点(即,易于进行运动规划)⁶
- 在进行运动规划之前,障碍物在C-space中表示⁸[10]
- 在C-space中表示障碍物可能非常复杂。因此,在实践中使用近似(但更保守)的表示。
如果我们保守地将机器人建模为半径为 _ 的球,那么可以通过在所有方向上膨胀障碍物 _ 来构造C-space1。这是一种常见的机器人碰撞检测方法,通过确保球体中心在膨胀地图的自由空间中来实现碰撞评估1。然而,这种保守的方法并未考虑到机器人的形状和大小。
构建地图:
在路径规划中,构建搜索地图是一个关键步骤。这通常涉及到将实际环境抽象为一个图(Graph),其中节点(Nodes)代表可能的位置,边(Edges)代表从一个位置到另一个位置的移动。以下是一个详细的例子:
假设我们有一个机器人需要在一个室内环境中导航。这个环境可以是一个房间,有一些障碍物,比如桌子和椅子。
- 定义节点(Nodes):首先,我们需要确定节点的位置。在这个例子中,我们可以将房间的每一个可达的位置定义为一个节点。例如,我们可以创建一个网格(Grid),每一个网格单元都是一个节点。
- 定义边(Edges):然后,我们需要确定边。如果机器人可以直接从一个节点移动到另一个节点,那么这两个节点之间就有一条边。在我们的例子中,如果两个网格单元相邻,并且没有障碍物阻挡,那么这两个网格单元(即节点)之间就有一条边。
- 定义权重(Weights):最后,我们需要为每一条边定义一个权重。权重可以根据实际的移动成本来确定。例如,如果从一个节点到另一个节点的距离更远,或者路径上有斜坡,那么这条边的权重就应该更大。
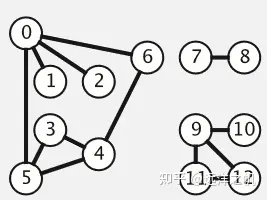
地图种类:
栅格地图(Grid Map)则是把环境划分成一系列栅格,在数学视角下是由边联结起来的结点的集合,一个基于图块拼接的地图可以看成是一个栅格图,每个图块(tile)是一个结点,图块之间的连接关系如短线。
概率图(Cost Map)如果在栅格图的基础上,每一栅格给定一个可能值,表示该栅格被占据的概率,则该图为概率图。
特征地图(Feature Map)特征地图用有关的几何特征(如点、直线、面)表示环境。常见于vSLAM(视觉SLAM)技术中。它一般通过如GPS、UWB以及摄像头配合稀疏方式的vSLAM算法产生,优点是相对数据存储量和运算量比较小,多见于最早的SLAM算法中。
拓扑地图(Topological Map)是指地图学中一种统计地图, 一种保持点与线相对位置关系正确而不一定保持图形形状与面积、距离、方向正确的抽象地图。包括有有向图和无向图(字面意思)。

栅格地图
概率图

特征地图
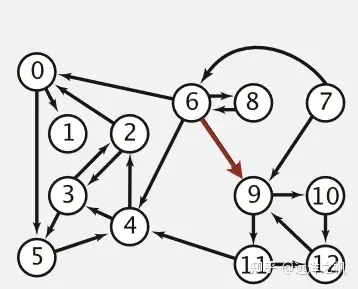
拓扑地图-有向图
拓扑地图-无向图
搜索算法介绍
有了这么多种的地图,那么对应每种图可以用什么对应的算法来做路径的规划呢?下面是地图对应路径搜索算法:
1. 栅格地图 / 概率图
1. Dijkstra
2. BFS(Best-First-Search)
3. A*
4. hybrid A*
5. D *
6. RRT
7. RRT*
8. 蚁群算法
9. Rectangular Symmetry Reduction (RSR)
10. BUG
11. Beam search
12. Iterative Deepeningc
13. Dynamic weighting
14. Bidirectional search
15. Dynamic A* and Lifelong Planning A *
16. Jump Point Search
17. Theta *
2. 拓扑地图
1. Dijkstra
2. BFS(Best-First-Search)
3. A*
4. CH
5. HH
6. CRP图搜索算法结构
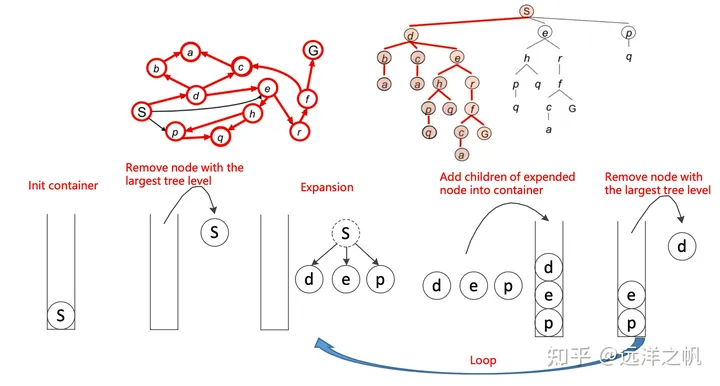
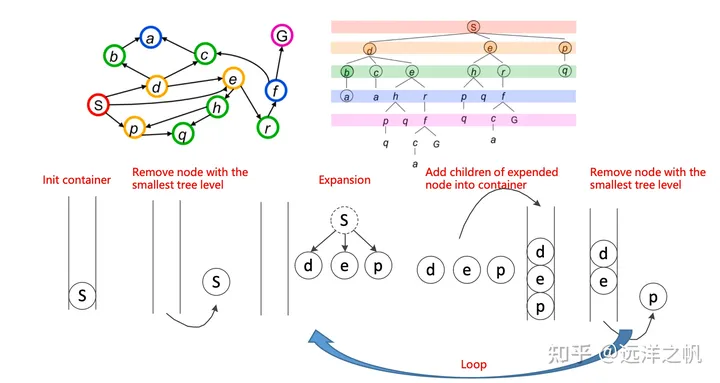
:::success
- 维护一个容器来存储所有待访问的节点
- 该容器以起始状态XS进行初始化
- 循环
- 根据某个预定义的评分函数从容器中移除一个节点
- 访问一个节点
- 扩展:获取该节点的所有邻居
- 发现所有的邻居
- 将它们(邻居)推入容器
- 扩展:获取该节点的所有邻居
- 结束循环 :::
通用搜索算法结构
常用的图搜索有3大类的搜索结构,其它算法都是在这三个大的框架之下做改进。
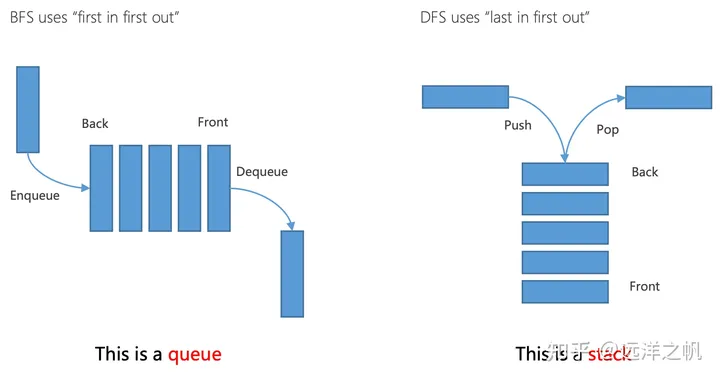
深度优先搜索(Depth-First Search, DFS):
- 原理:DFS是一种用于遍历或搜索树或图的算法。这个算法会尽可能深地搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
- 优点:实现简单,当目标明确时,搜索效率高。
- 缺点:不保证找到最短路径,有可能会导致搜索陷入无限循环。
广度优先搜索(Breadth-First Search, BFS):
- 原理:BFS是一种广度优先的搜索算法,用于搜索树或图。这个算法从根节点开始,沿着树的宽度遍历树的节点,如果所有节点均被访问,则算法结束。
- 优点:可以找到最短路径,结果可靠。
- 缺点:空间复杂度高,当解空间大时,内存消耗大。
贪婪搜索(Greedy Search):
- 原理:贪婪搜索是一种在每一步选择中都采取在当前看来最好的选择,希望通过一系列的最优选择,能够产生一个全局最优的解决方案。
- 优点:简单,易于实现,计算速度快。
- 缺点:不能保证找到全局最优解,只能保证找到局部最优解。
- 深度优先搜索(DFS):DFS会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条路径。这种搜索策略可以看作是“先入后出”,因此在实现DFS时通常使用栈(Stack)这种数据结构。DFS的优点是实现简单,当目标明确时,搜索效率高。然而,DFS的缺点是不保证找到最短路径,有可能会导致搜索陷入无限循环。
- 广度优先搜索(BFS):相比之下,BFS会根据离起点的距离,按照从近到远的顺序对各节点进行搜索。这种搜索策略可以看作是“先入先出”,因此在实现BFS时通常使用队列(Queue)这种数据结构。BFS的优点是可以找到最短路径,结果可靠。然而,BFS的缺点是空间复杂度高,当解空间大时,内存消耗大。
算法核心的三个问题是:
- 问题1:何时结束循环?
- 可能的选项:当容器为空时结束循环
- 问题2:如果图是循环的怎么办?
- 当一个节点从容器中移除(扩展/访问)后,它就不应该再被添加回容器
- 问题3:如何移除正确的节点以便尽快到达目标状态,从而减少图节点的扩展。
深度优先算法:数据结构维护一个后进先出(LIFO)的容器(即栈),算法移除/扩展容器中最深的节点
#生成示例数据
graph = {}
graph["A"] = ["B", "D", "F"]
graph["B"] = ["C", "E"]
graph["D"] = ["C"]
graph["F"] = ["G", "H"]
graph["C"] = []
graph["E"] = []
graph["G"] = []
graph["H"] = []
from collections import deque
search_queue = deque() # 创建一个节点列表
search_queue += graph["A"] # 表示将"A"的相邻节点都添加到节点列表中
from collections import deque
def search(start_node):
search_queue = deque()
search_queue += graph[start_node]
searched = [] # 这个数组用于记录检查过的节点
while search_queue: # 只要节点列表不为空
node = search_queue.pop() #深度优先
#node = search_queue.popleft() # 广度优先取出节点列表中最左边的节点
print(node, end=' ') # 打印出当前节点
if not node in searched: # 如果这个节点没检查过
if node == 'G': # 检查这个节点是否为终点"G"
print("\nfind the destination!")
return True
else:
search_queue += graph[node] # 将此节点的相邻节点都添加到节点列表中
searched.append(node) # 将这个节点标记为检查过
# 如果节点列表为空仍没找到终点,则返回False
return False
print(search("A"))广度优先搜索算法:
数据结构:维护一个先进先出(FIFO)的容器(即队列),算法操作:移除/扩展容器中最浅的节点。具体代码参考上面深度搜索算法,把“node = search_queue.pop() #深度优先”换成“node = search_queue.popleft() # 广度优先取出节点列表中最左边的节点”即可。可以看出BFS和DFS差别就在于根据“先入”或“后入”的原则,从边界中选择下一个节点。
贪婪搜索(Greedy Search):
贪心算法的特点是考虑了从目标节点找到任意点的代价,而一般算法考虑的是从起始节点到任意点的代价。即贪心算法考虑的是如何快速的找到目标节点,使得到达目标节点的时间成本最小;而一般算法考虑的是目标节点到达目标节点的花费代价是最小的,而不是快速找到目标节点。基于贪心策略试图向目标移动尽管这不是正确的路径。由于它仅仅考虑到达目标的代价,而忽略了当前已花费的代价,于是尽管路径变得很长,它仍然继续走下去。
贪婪算法中“行动的成本”可以用启发式函数h(n)来算从任意结点n到目标结点的最小代价评估值;启发函数决定了贪婪算法运算书读,所以选择一个好的启发函数很重要。
- 实际的搜索问题中,从一个节点到其邻居有一个“C”的成本
- 可以作为启发函数计算代价的有:长度,时间,能量等
- 当所有权重都为1时,贪婪算法找到最优解
- 对于一般情况,如何尽快找到最小成本路径?
Dijkstra算法:
Dijkstra算法算是贪心思想实现的,其可以适用与拓扑图或者栅格图,具体实现方法是,首先把起点到所有点的距离存下来找个最短的,然后松弛一次再找出最短的,所谓的松弛操作就是,遍历一遍看通过刚刚找到的距离最短的点作为中转站会不会更近,如果更近了就更新距离,这样把所有的点找遍之后就存下了起点到其他所有点的最短距离:
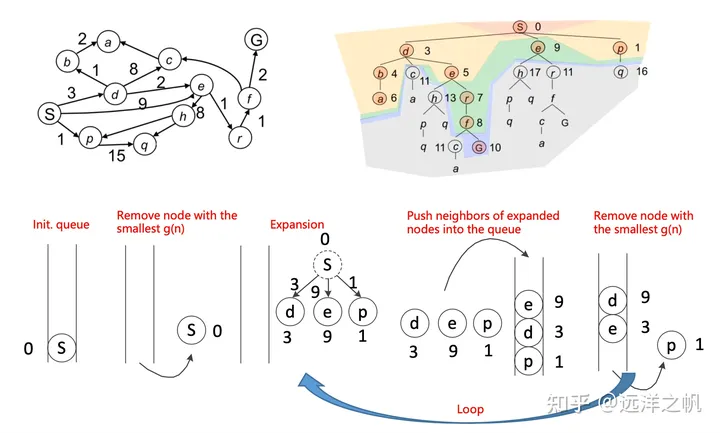
- 策略:扩展/访问具有最低累积成本g(n)的节点
- g(n):从起始状态到节点“n”的累积成本的当前最佳估计
- 更新所有未扩展邻居“m”的累积成本g(m)
- 已经被扩展/访问的节点保证具有从起始状态到该节点的最小成本 :::success
- 维护一个优先队列来存储所有待扩展的节点
- 用起始状态XS初始化优先队列
- 设置g(XS)=0, 对图中的其他所有节点设置g(n)=无穷
- 循环:
- 如果队列为空,返回FALSE并退出循环
- 从优先队列中取出g(n)最小的节点“n”
- 将节点“n”标记为已扩展
- 如果节点“n”是目标状态,返回TRUE并退出循环
- 对节点“n”的所有未扩展的邻居节点“m”:
- 如果g(m) = 无穷
- g(m)= g(n) + Cnm
- 将节点“m”加入队列
- 如果g(m) > g(n) + Cnm
- g(m)= g(n) + Cnm
- 结束对邻居节点的循环
- 结束主循环 ::: BFS(Best-First-Search)算法
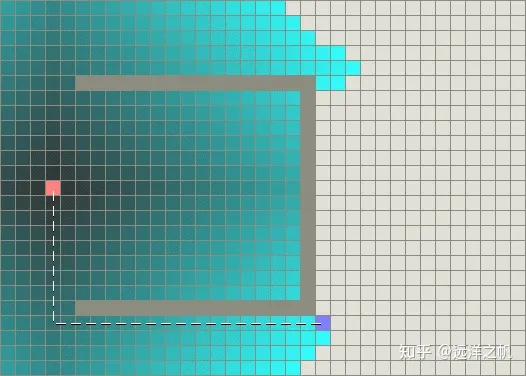
BFS(Best-First-Search)算法也是可以看作基于启发式的深度优先算法,其按照和Dijkstra类似的流程运行,不同的是它能够评估任意结点到目标点的代价(即启发式函数)。与选择离初始结点最近的结点不同的是,它选择离目标最近的结点。BFS不能保证找到一条最短路径。但是它比Dijkstra算法快的多,因为它用了一个启发式函数(heuristic )能快速地导向目标结点。例如,如果目标位于出发点的南方,BFS将趋向于导向南方的路径。在下面的图中,越黄的结点代表越高的启发值(移动到目标的代价高),而越黑的结点代表越低的启发值(移动到目标的代价低)。这表明了与Dijkstra 算法相比,BFS运行得更快。

然而,这两个例子都仅仅是最简单的情况——地图中没有障碍物,最短路径是直线的。现在我们来考虑前边描述的凹型障碍物。Dijkstra算法运行得较慢,但确实能保证找到一条最短路径:
另一方面,BFS运行得较快,但是它找到的路径明显不是一条好的路径:
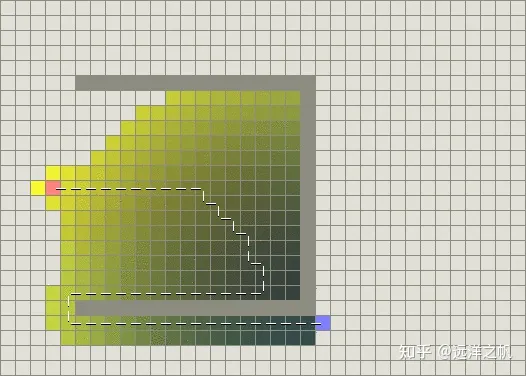
由于BFS是基于贪心策略的,它试图向目标移动尽管这不是正确的路径。由于它仅仅考虑到达目标的代价,而忽略了当前已花费的代价,于是尽管路径变得很长,它仍然继续走下去。
结合两者的优点不是更好吗?1968年发明的A算法就是把启发式方法(heuristic approaches)如BFS,和常规方法如Dijsktra算法结合在一起的算法。有点不同的是,类似BFS的启发式方法经常给出一个近似解而不是保证最佳解。然而,尽管A基于无法保证最佳解的启发式方法,A却能保证找到一条最短路径。
A: 带有启发式函数的Dijkstra算法*
把Dijkstra算法(靠近初始点的结点)和BFS算法(靠近目标点的结点)的信息块结合起来。在A的标准术语中,g(n)表示从初始结点到任意结点n的代价,h(n)表示从结点n到目标点的启发式评估代价(heuristic estimated cost)。当从初始点向目标点移动时,A* 权衡这两者。每次进行主循环时,它检查f(n)最小的结点n,其中f(n) = g(n) + h(n)。
- 累积成本
- g(n): 从起始状态到节点“n”的累积成本的当前最佳估计
- 启发式函数
- h(n): 从节点n到目标状态(即目标成本)的预计最小成本
- 从起始状态到通过节点“n”的目标状态的最小预计成本是 f(n) = g(n) + h(n)
- 策略: 扩展具有最便宜的 f(n) = g(n) + h(n) 的节点
- 更新所有未扩展邻居“m”的节点“n”的累积成本 g(m)
- 已经扩展的节点保证具有从起始状态到该节点的最小成本 :::success
- 维护一个优先队列来存储所有待扩展的节点
- 对所有节点预定义启发函数h(n)
- 用起始状态XS初始化优先队列
- 设置g(XS)=0,对图中的其他节点设置g(n)=无穷
- 循环:
- 如果队列为空,返回FALSE并退出循环
- 从队列中取出f(n)=g(n)+h(n)最小的节点“n”
- 将节点“n”标记为已扩展
- 如果节点“n”是目标状态,返回TRUE并退出循环
- 对节点“n”的所有未扩展邻居节点“m”:
- 如果g(m)=无穷
- g(m)= g(n) + Cnm
- 将节点“m”加入队列
- 如果g(m)>g(n)+Cnm
- g(m)= g(n) + Cnm
- 结束对邻居节点循环
- 结束主循环 ::: 通过对启发式函数的调节,可以达成控制A* 的行为:
- 一种极端情况,如果h(n)是0,则只有g(n)起作用,此时A* 演变成Dijkstra算法,这保证能找到最短路径。
- 如果h(n)经常都比从n移动到目标的实际代价小(或者相等),则A保证能找到一条最短路径。h(n)越小,A扩展的结点越多,运行就得越慢。
- 如果h(n)精确地等于从n移动到目标的代价,则A 将会仅仅寻找最佳路径而不扩展别的任何结点,这会运行得非常快。尽管这不可能在所有情况下发生,但是你仍可以在一些特殊情况下让它们精确地相等。只要提供完美的信息,A会运行得很完美,认识这一点很好。
- 如果h(n)有时比从n移动到目标的实际代价高,则A* 不能保证找到一条最短路径,但它运行得更快。
- 另一种极端情况,如果h(n)比g(n)大很多,则只有h(n)起作用,A* 就演变成了BFS算法。
如果目标的引力太低,会得到最短路径,不过速度变慢了;如果目标引力太高,那就放弃了最短路径,但A运行得更快,所以最优路径和最快搜索在复杂情况下需要有一个取舍/平衡。
A的这个特性非常有用。例如,你会发现在某些情况下,你希望得到一条好的路径,而不是一条完美的路径,为了权衡g(n)和h(n),你可以修改任意一个。
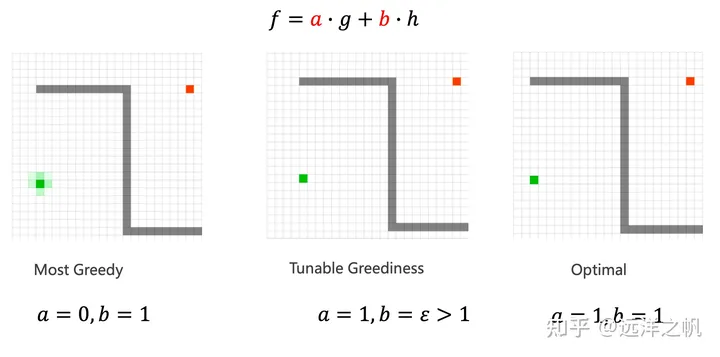
如果alpha是0,则改进后的代价函数的值总是1。这种情况下,地形代价被完全忽略,A工作变成简单地判断一个网格可否通过。如果alpha是1,则最初的代价函数将起作用,然后你得到了A的所有优点。你可以设置alpha的值为0到1的任意值。
可以考虑对启发式函数的返回值做选择:绝对最小代价或者期望最小代价。例如,如果你的地图大部分地形代价为2,其它一些地方是代价为1的道路,那么你可以考虑让启发式函数不考虑道路,而只返回2距离。
速度和精确度之间的选择并不是全局固定对。在地图上的某些区域,精确度是重要的,你可以基于此进行动态选择。例如,假设我们可能在某点停止重新计算路径或者改变方向,则在接近当前位置的地方,选择一条好的路径则是更重要的,对于在地图上的一个安全区域,最短路径也许并不十分重要,但是当从一个危险区域脱离对时候,轨迹的精度是最重要的。
同样通过对g(n)或者f(n)的调节,也可以达成A具体动作的控制
- 通过加上障碍物cost function到g(n)或者f(n)(这两个动作是一个意思),可以实现规划路径在障碍物中间。
- 通过加上车辆几何或者轨迹kappa平滑度cost function的到g(n)或者f(n),可以实现规划出来的路径是平滑变化的。
- 通过加上到way point的cost function的到g(n)或者f(n),规划出来的路径则倾向于走way points的方向。
- 构造精确启发函数的一种方法是预先计算任意一对结点之间最短路径的长度。有几种方法可以近似模拟这种启发函数:
1. 【降采样地图-预计算】在密集栅格图的基础上添加一个分辨率更大的稀疏栅格图。预计算稀疏图中任意两个栅格的最短路径。
2. 【waypoings-预计算】在密集栅格图上,预计算任意两个way points的的最短路径。通过以上方法,添加一个启发函数h’用于评估从任意位置到达邻近导航点/中继点(waypoints)的代价。最终的启发式函数可以是:
h(n) = h'(n, w1) + distance(w1, w2), h'(w2, goal)
网格地图中的启发式算法
在网格地图中,有一些众所周知的启发式函数计算方法:
1. 曼哈顿距离
2. 对角线距离
3. 欧几里得距离
4. 欧几里德距离平方曼哈顿距离
标准的启发式函数是曼哈顿距离(Manhattan distance)。考虑代价函数并找到从一个位置移动到邻近位置的最小代价D。因此,h是曼哈顿距离的D倍:
``` H(n) = D \ * (abs ( n.x – goal.x ) + abs ( n.y – goal.y ) ) ```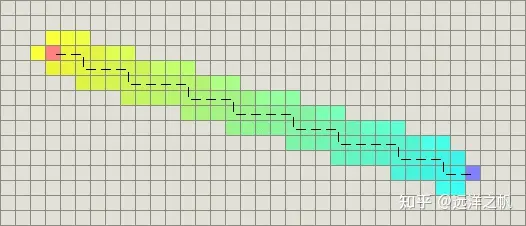
对角线距离
如果在地图中允许对角运动那么需要考虑对角线距离。(4 east, 4 north)的曼哈顿距离将变成8D。然而,可以简单地移动(4 northeast)代替,所以启发函数应该是4D。这个函数使用对角线,假设直线和对角线的代价都是D:
H(n) = D * max(abs(n.x - goal.x), abs(n.y - goal.y))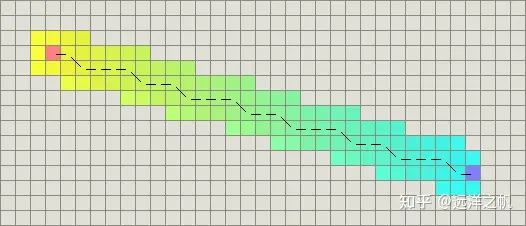
如果对角线运动的代价不是D,但类似于D2 = sqrt(2) * D,则准确的计算方法如下:
h_diagonal(n) = min(abs(n.x - goal.x), abs(n.y - goal.y))
h_straight(n) = (abs(n.x - goal.x) + abs(n.y - goal.y))
H(n) = D2\* h_diagonal(n) + D\* (h_straight(n) - 2\ *h_diagonal(n)))计算h_diagonal(n):沿着斜线可以移动的步数;h_straight(n):曼哈顿距离;然后合并这两项,让所有的斜线步都乘以D2,剩下的所有直线步(注意这里是曼哈顿距离的步数减去2倍的斜线步数)都乘以D。
欧几里德距离
如果单位可以沿着任意角度移动(而不是网格方向),那么应该使用直线距离:
``` H(n) = D* sqrt((n.x-goal.x)^2 + (n.y-goal.y)^2) ```然而,如果是这样的话,直接使用A时将会遇到麻烦,因为代价函数g不匹配启发函数h。因为欧几里得距离比曼哈顿距离和对角线距离都短,你仍可以得到最短路径,不过A将运行得更久一些:
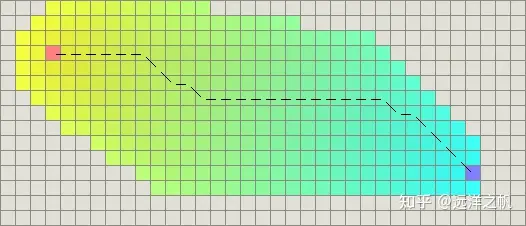
欧几里德距离平方
还有一个方法是,使用距离的平方替代距离,避免进行平方根开方运算,从而减少计算消耗:
``` H(n) = D* ((n.x-goal.x)^2 + (n.y-goal.y)^2) ```不过这样做会明显地导致衡量单位的问题。当A计算f(n) = g(n) + h(n),距离的平方将比g的代价大很多,并且会因为启发式函数评估值过高而停止。对于更长的距离,这样做会靠近g(n)的极端情况而不再计算任何东西,A退化成BFS:
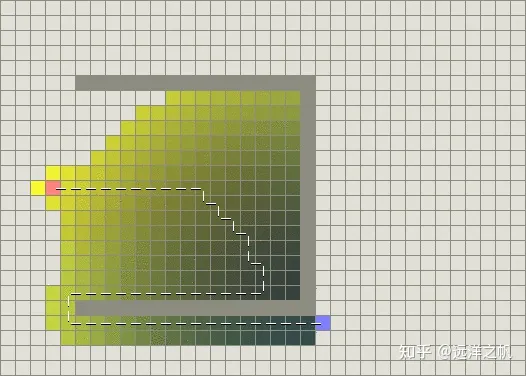
启发函数的启发因子
导致A搜索低性能的另外一个原因是启发函数的启发因子。当某些路径具有相同的f值的时候,它们都会被探索,比较函数无法打破比较平衡点,尽管我们这时候只需要搜索其中的一条,下图为没有添加启发因子的效果:

为了解决这个问题,我们可以为启发函数添加一个较小的启发因子。启发因子对于每个结点必须是确定的唯一的,而且它必须让f值体现区别。因为A将会对f值进行堆排序,让f值不同,意味着只有一个f值会被检测。
一种添加启发因子的方式是稍微改变h的衡量单位。如果我们减少衡量单位,那么当我们朝着目标移动的时候f将逐渐增加。很不幸,这意味着A倾向于扩展到靠近初始点的结点,而不是靠近目标的结点。我们可以稍微的微调h的衡量单位(甚至是0.1%),A就会倾向于扩展到靠近目标的结点。
``` heuristic \ \ *= (1.0 + p) ```其中这里的启发因子需要满足
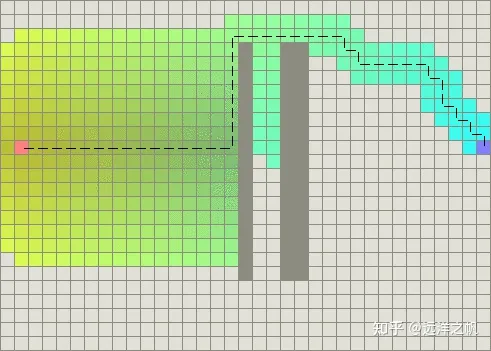
p < 移动一步的最小代价 / 期望的最长路径长度。假设你不希望你的路径超过1000步(step),你可以使p = 1 / 1000。添加这个附加值的结果是,A比以前搜索的结点更少了。如下图所示。

当存在障碍物时,当然仍要在它们周围寻找路径,但要意识到,当绕过障碍物以后,A搜索的区域非常少:
- Steven van Dijk的建议是:直接把h放到比较函数中。当f值相等时,比较函数将会通过比较两个节点h的大小实现启发因子的功能,打破比较平衡点。
- Cris Fuhrman的建议的启发因子是:给每个节点加一个决定性的任意数,例如所在坐标系中位置的hash值
- 最后一种方法类似于frenet坐标系的做法:对比起点到终点的直连线段的投影距离,计算方法入下:
dx1 = current.x - goal.x
dy1 = current.y - goal.y
dx2 = start.x - goal.x
dy2 = start.y - goal.y
cross = abs(dx1*dy2 - dx2*dy1)
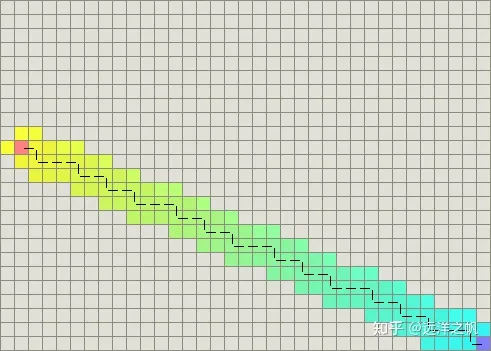
heuristic += cross*0.001其目的是:计算初始->目标向量和当前->目标向量的向量叉乘(cross-product)。当向量偏离方向后,其叉乘将会提供一个较大的启发因子。结果是,这段代码选择的路径稍微倾向于从初始点到目标点的直线。当没有障碍物时,A不仅搜索很少的区域,而且它找到的路径看起来非常棒:
跳点搜索
Jump Point Search (JPS) 是一种改进的 A_ 算法,它保留了 A_ 算法的主体框架,但在寻找后继节点的操作上进行了优化。在 A 算法中,会将当前节点的所有未访问邻居节点加入 openlist。而 JPS 则使用一些方法将有“价值”的节点加入 openlist。JPS 的核心就是寻找跳点 (Jump Point),在 JPS 中,就是将跳点加入 openlist。跳点就是路径的转折点。
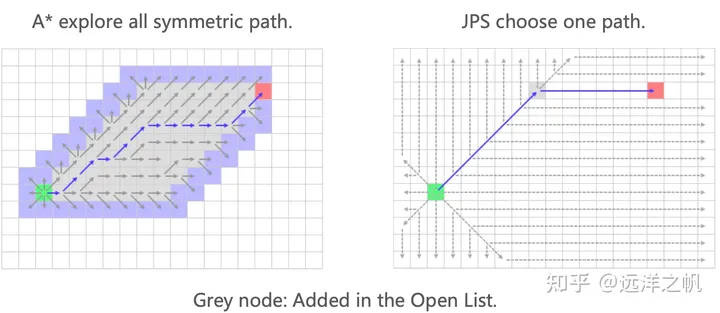
JPS明智地进行探索,因为它总是根据规则向前看。强调了其在搜索过程中的智能性和前瞻性。
JPS 算法的基本流程与 A 一致,代价函数 f(n) 仍然表示如下:f(n)=g(n)+h(n)。
JPS 算法的优点在于,由于它只扩展跳点,跳点间的栅格被跳过,不加入 OpenList,因此,它的搜索效率比 A 算法提高了一个等级。
在实现JPS前先了解它的规则
- 强迫邻居:节点X的邻居节点有障碍物,且X的父节点P经过X到达N的距离代价,比不经过X到达N的任一路径的距离代价都小,则称N是X的强迫邻居。
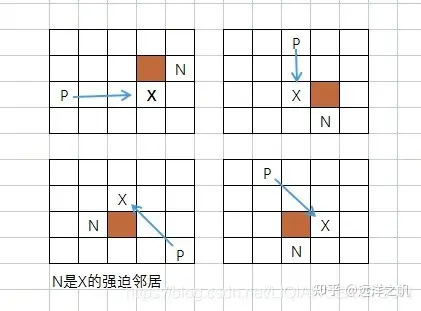
- 跳点(Jump Point):什么样的节点可以作为跳点
(1)节点 A 是起点、终点.
(2)节点A 至少有一个强迫邻居.
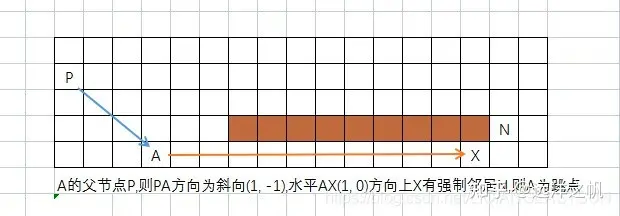
(3)父节点在斜方向(斜向搜索),节点A的水平或者垂直方向上有满足 (1)、(2) 的节点
在搜索过程中它可以将水平和垂直方向两个分量,分解为一个方向为(1, 0)的水平搜索,一个方向为(0, 1)的垂直搜索
同理斜向有四种方向
左上 (-1, 1) ——>对应的水平 (-1, 0),垂直 ( 0, 1)
右上 ( 1, 1) ——>对应的水平 ( 1, 0),垂直 ( 0, 1)
右下 ( 1, -1) ——>对应的水平 ( 1, 0),垂直 ( 0, -1)
左下 (-1, -1) ——>对应的水平 (-1, 0),垂直 ( 0, -1)
如上所说(3)的情形即为如下
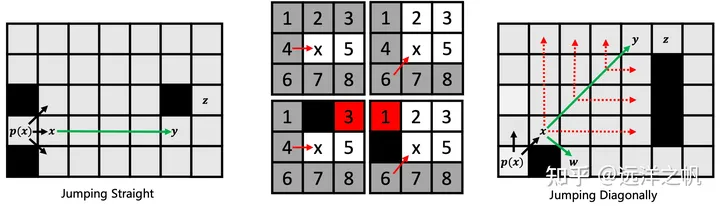
- 递归应用直线剪枝规则,并将 y 识别为 x 的跳点后继。这个节点很有趣,因为它有一个邻居 z,除非通过访问 x 然后 y 的路径,否则无法最优地到达。
- 递归应用对角线剪枝规则,并将 y 识别为 x 的跳点后继。
- 在每次对角线步骤之前,我们首先递归直线。只有当两次直线递归都未能识别出跳点时,我们才再次对角线步进。
- 节点 w,x 的强制邻居,正常扩展。(也推入开放列表,优先队列)。
记住:你只能直线跳跃或对角线跳跃;不能分段跳跃。:::success - 维护一个优先队列来存储所有待扩展的节点
- 对所有节点预先定义启发函数h(n)
- 用起始状态XS初始化优先队列
- 设置g(XS)=0,对图中的其他节点设置g(n)=无穷
- 循环:
- 如果队列为空,返回FALSE并退出循环
- 从队列中取出f(n)=g(n)+h(n)最小的节点“n”
- 将节点“n”标记为已扩展
- 如果节点“n”是目标状态,返回TRUE并退出循环
- 对节点“n”的所有未扩展邻居节点“m”:
- 如果g(m)=无穷
- g(m)= g(n) + Cnm
- 将节点“m”加入队列
- 如果g(m)>g(n)+Cnm
- g(m)= g(n) + Cnm
- 结束对邻居节点的循环
- 结束主循环 ::: openlist查找具体流程如下²:
- 初始化起点节点 start ,将起点周围四个角落的空闲节点相对于起点的相对位置加入起点节点的 forced_neighbor_list。
- 创建一个 openlist ,将 start 加入 openlist。
- while openlist is not empty:
- node ← openlist.Pop ()
- 从 node 开始跳跃,首先进行直线跳跃,再进行对角线跳跃。
- 用 parent 表示从 node 进行对角线跳跃得到的节点,用 current 表示从 parent 进行直线跳跃得到的节点。
- 如果 current 是跳点,而 parent 与 node 是同一个节点,则将 current 加入 openlist,同时将 current 的父节点指向 node;
- 如果 current 是跳点,而 parent 与 node 不是同一个节点,则将 parent 和 current 加入 openlist,同时将 current 的父节点指向 parent,将 parent 的父节点指向 node;
- 如果 current 是障碍物或者边界,则进行对角线跳跃;
- 如果 parent 是障碍物或者边界,则进入下一轮循环。
例子:
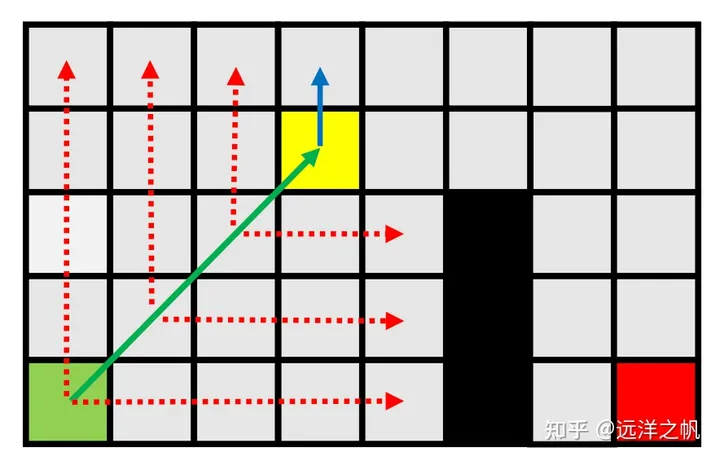
- 扩展—>对角线移动
- 最终找到一个关键节点,将其加入开放列表。
- 从开放列表中弹出它(唯一的节点)。
- 垂直扩展,在障碍物处结束。
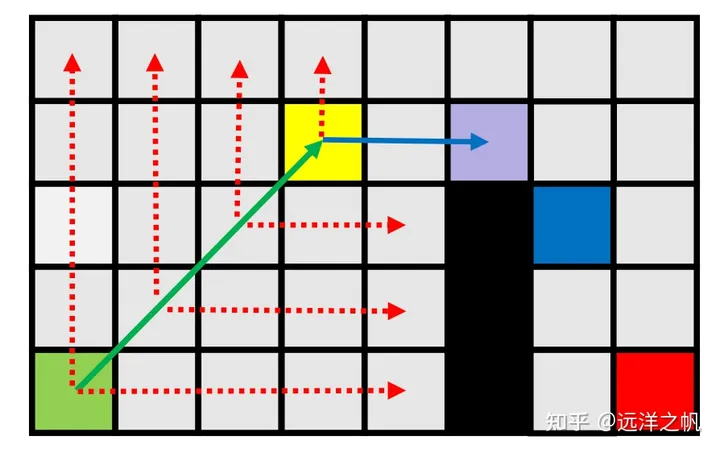
- 水平扩展,遇到一个具有强制邻居的节点。
- 将其添加到开放列表。
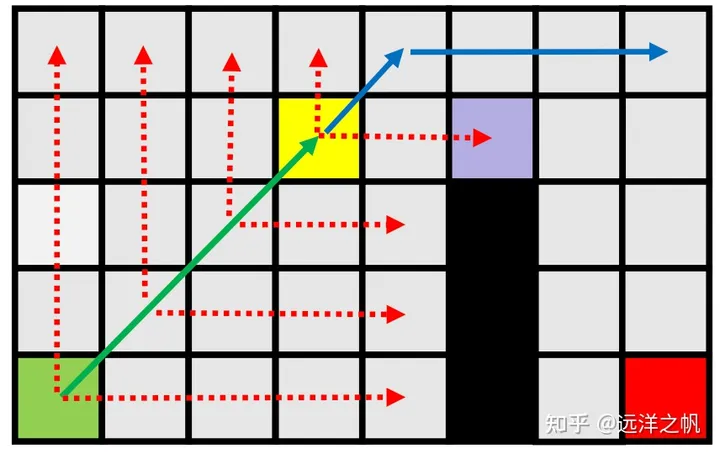
- 对角线扩展,扩展后没有发现任何新的节点。
- 完成当前节点的扩展。
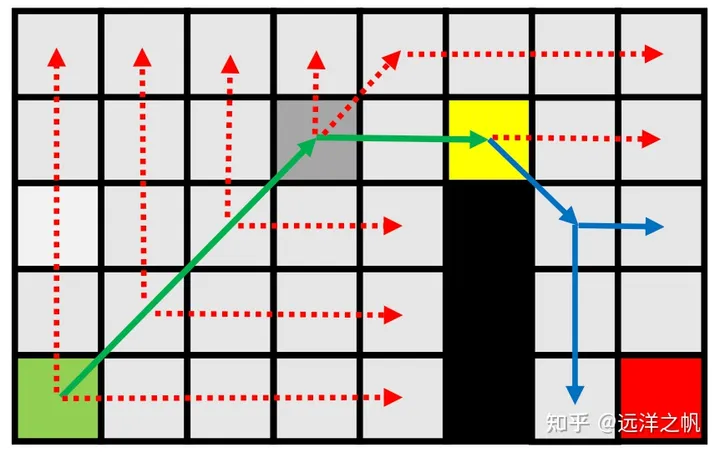
- 对角线移动。
- 先沿垂直和水平方向扩展。
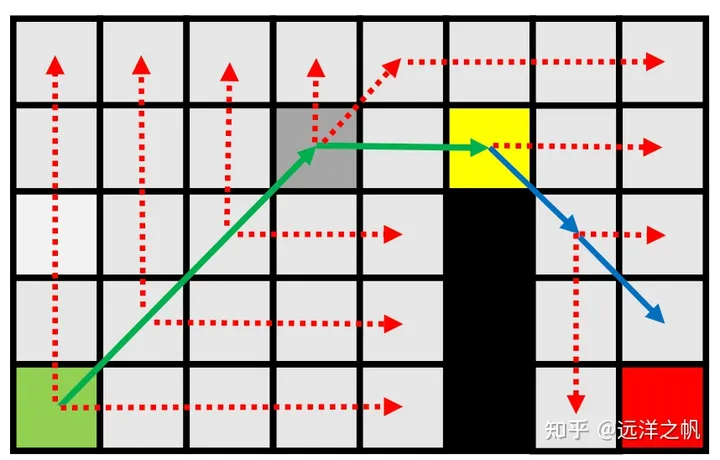
- 没有发现任何新的节点。
- 对角线移动。
更详细跳点搜索可以参考下面文章:
https://blog.csdn.net/LIQIANGEASTSUN/article/details/118766080
小结:
本文介绍了motion plan学院派的框架:
- 前端路径规划
- 后端轨迹生成
- 不确定障碍物预估规划
并且详细介绍了前端路径规划常用的搜索规划,介绍了搜索规划的一些前置知识:
- c-space,为了方便物体质点化处理,建图时把物体形状构建转移到图
- 各种不同图如何构建成适合搜索算法的数据格式,以及不同图适合的搜索算法
- 搜索算法的三个基本框架:深度搜索、广度搜索、贪心搜索
详细介绍了了几种贪心搜索算法原理和实现思路:
- Dijkstra算法:
- A* 搜索
- 跳点搜索
并且介绍了:累计成本,启发函数,以及这两个函数的物理意义;如何调控两个参数来实现计算速度和最优路径的平衡。
- 累积成本
- g(n): 从起始状态到节点“n”的累积成本的当前最佳估计
- 启发式函数
- h(n): 从节点n到目标状态(即目标成本)的预计最小成本