大家好,我是君哥。
使用消息队列时,为了提高生产和消费的性能,有时会开启批量处理。
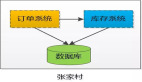
在生产端,生产者发送的消息先发送到一个消息列表,积累到一定的消息量之后再批量发送给 Broker,如下图:

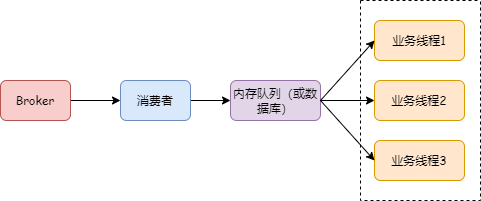
在消费端,消费者拉取消息后先不立即处理,而是把消息转存到一个内存队列或数据库,由业务线程去处理,如下图:
无论是生产者做批量发送,还是消费者做批量处理,都需要考虑使用批量消息的业务场景,避免踩坑。下面看一下批量操作可能会遇到哪些坑。
批量大小
当生产者采用批量发送的方式来提高发送性能时,一定要考虑发送消息的批量大小。下面是 RocketMQ 批量发送的官方示例:
String topic = "BatchTest";
List<Message> messages = new ArrayList<>();
messages.add(new Message(topic, "TagA", "OrderID001", "Hello world 0".getBytes()));
messages.add(new Message(topic, "TagA", "OrderID002", "Hello world 1".getBytes()));
messages.add(new Message(topic, "TagA", "OrderID003", "Hello world 2".getBytes()));
try {
producer.send(messages);
} catch (Exception e) {
e.printStackTrace();
//handle the error
}RocketMQ 默认消息大小是 4M,由 maxMessageSize 参数控制,如果批量消息大小超过 maxMessageSize,则会抛出异常。
如果遇到消息大小超过 maxMessageSize 的情况时,可以用下面方法进行处理:
- 把这个参数改大,但需要考虑 Broker 的性能和网络带宽;
- 将消息进行拆分后分批发送;
- 对消息进行压缩处理。
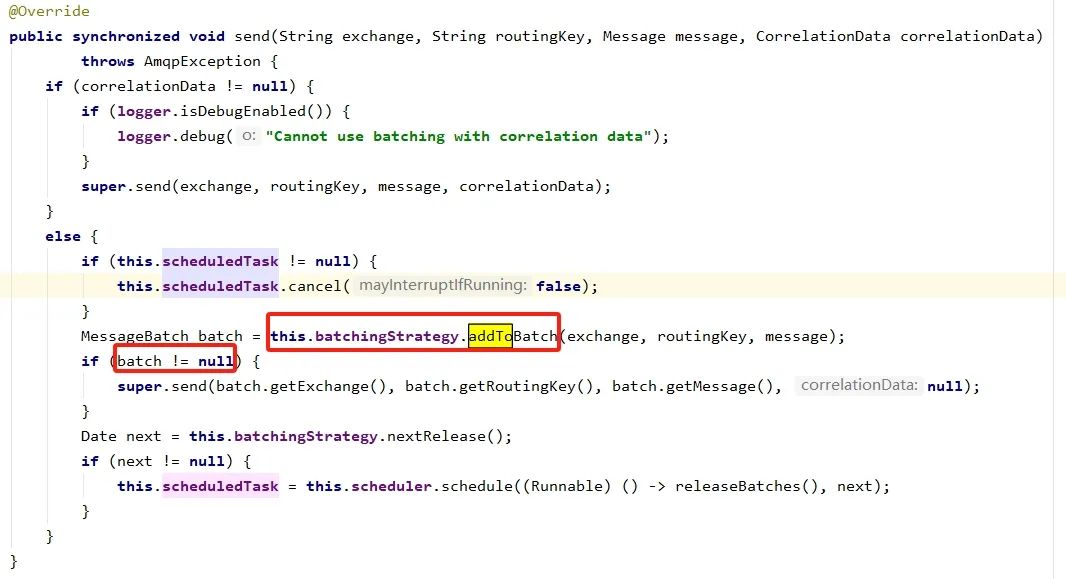
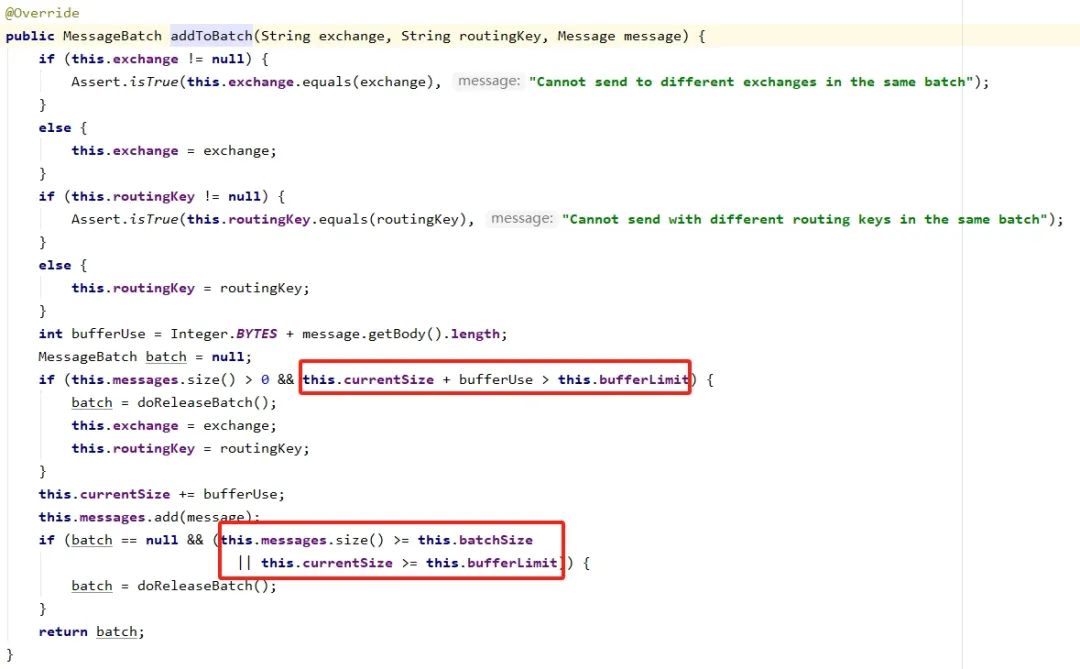
RabbitMQ 相关的 API 则提供了更加灵活的批量控制,对消息数量和消息大小都做了控制,下面看一下源码:
幂等
消费端可以批量拉取消息进行消费,这样可以减少拉取消息时的 RPC 次数,提升消费性能。比如在 RocketMQ 中,可以通过 Consumer 中的 pullBatchSize 来设置一次拉取的消息数量,通过 consumeMessageBatchMaxSize 参数来设置一次消费的消息数量。
但需要注意的是,如果批量消息中一条消息消费失败了,这一批消息都需要进行重试,已经消费成功的消息会被重复消费,带来业务问题。
为了不对业务造成影响,必须考虑幂等。一个简单的方法是在消息中增加全局唯一 id 属性,对消息消费结果进行记录,消费成功后保存 id。这样在消费消息之前先查询是否存在消费成功的记录,如果存在则直接返回处理成功。
时延
在使用消息队列进行批量操作时,必须要考虑到时延问题。比如我们设置一个批次 100 条消息,积累够 100 条消息后再发送,在消息量小的情况下,可能积累够 100 条消息会很长时间,导致消费端拉取到一条消息时延很大。
虽然消息队列的一个重要作用是削峰填谷,但在一些场景下,对消息的实时性也有要求。比如在车联网的充电场景,车联网平台需要实时感知充电桩的状态,如果充电桩积累够一批消息再上报平台,平台获取到的状态会不准确,如果心跳消息延时太久,平台会认为充电桩离线。
对于有时延要求又需要批量操作的场景,可以设置一个超时时间,超时后即使消息数量不够,也会发送出去。看下 RabbitMQ 的处理:
public synchronized void send(String exchange, String routingKey, Message message, CorrelationData correlationData)
throws AmqpException {
if (correlationData != null) {
//...
super.send(exchange, routingKey, message, correlationData);
}
else {
if (this.scheduledTask != null) {
this.scheduledTask.cancel(false);
}
MessageBatch batch = this.batchingStrategy.addToBatch(exchange, routingKey, message);
if (batch != null) {
super.send(batch.getExchange(), batch.getRoutingKey(), batch.getMessage(), null);
}
//这里获取到超时时间,到达超时时间后使用定时器将消息发送出去
Date next = this.batchingStrategy.nextRelease();
if (next != null) {
this.scheduledTask = this.scheduler.schedule((Runnable) () -> releaseBatches(), next);
}
}
}可靠性
使用批处理一定要考虑可靠性的问题。
在消费端,消费者批量拉取一批消息后把消息暂存到一个内存临时队列,然后多线程去临时队列消费消息,如果服务宕机,临时队列中的消息会丢失。
为了避免宕机引发的损失,可以拉取一批消息后保存到数据库,然后给 Broker 返回 ACK,之后业务代码去数据库查询消息并消费,不过要考虑数据库大事务、锁竞争等问题。
当然,对于一些消息丢失不敏感的场景,比如日志收集之类的,可靠性这个指标是不用太关注的。
特殊场景
因为批量消息有一些复杂性,消息队列的部分特性不支持。
事务消息
批量消息会增加消息重试的难度,所以对于事务消息,建议使用单条消息,一条消息对应一个事务。
顺序消息
顺序消息的实现思路一般是生产者将消息发送到同一个分区,消费者绑定这个分区并使用单线程消费这个分区的消息。如果对同一个 Topic 下的同一个分区来实现批量发送,难度会增大。所以建议顺序消息使用单条消息进行发送。
延时消息
如果延时消息使用批量进行发送,这一批消息的延时时间必须相同,同时要考虑批量消息的超时时间,超时时间太大会影响延时时间的准确性,生产端实现复杂度大大增加。
总结
使用批量消息,在一定程度上可以提高性能和吞吐量,但是确实也会存在一些问题,使用的时候要结合业务场景避开这些坑。