排序是计算机中常见且重要的操作,用于使数据按照某种规则或标准进行有序化,便于后续的搜索、查找和处理。
为什么排序算法很重要?
由于排序通常有助于降低问题的算法复杂性,因此它在计算机科学中具有重要用途。百度搜索显示,当今计算世界中有 40 多种不同的排序算法。疯狂吧?那你知道几个呢!
现实世界中实现这一点的一些最佳示例是。
- 冒泡排序用于电视节目中,根据观众观看时间对频道进行排序!
- 数据库使用外部合并排序对太大而无法完全加载到内存中的数据集进行排序!
- 体育比分通过快速排序算法实时快速组织!
数据结构中的排序类型
- 基于比较的排序:在基于比较的排序技术中,定义比较器来比较数据样本的元素或项目。该比较器定义元素的顺序。例子有:冒泡排序、归并排序。
- 基于计数的排序:这些类型的排序算法中的元素之间不涉及比较,而是在执行过程中进行计算假设。例如:计数排序、基数排序。
- 就地与非就地排序(In-Place vs Not-in-Place Sorting):数据结构中的就地排序技术会修改原始数组中数组元素的顺序。另一方面,非就地排序技术使用辅助数据结构对原始数组进行排序。就地排序技术的示例有:冒泡排序、选择排序。非就地排序算法的一些示例包括:合并排序、快速排序。
PS:GIF图较大,耐心等待打开,值得反复去看!
1、冒泡排序
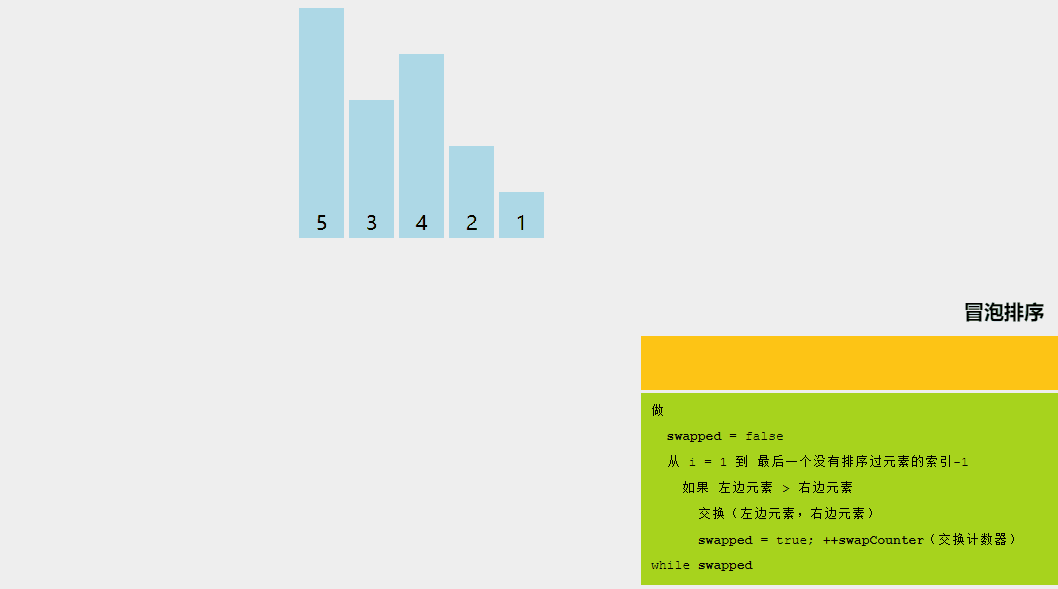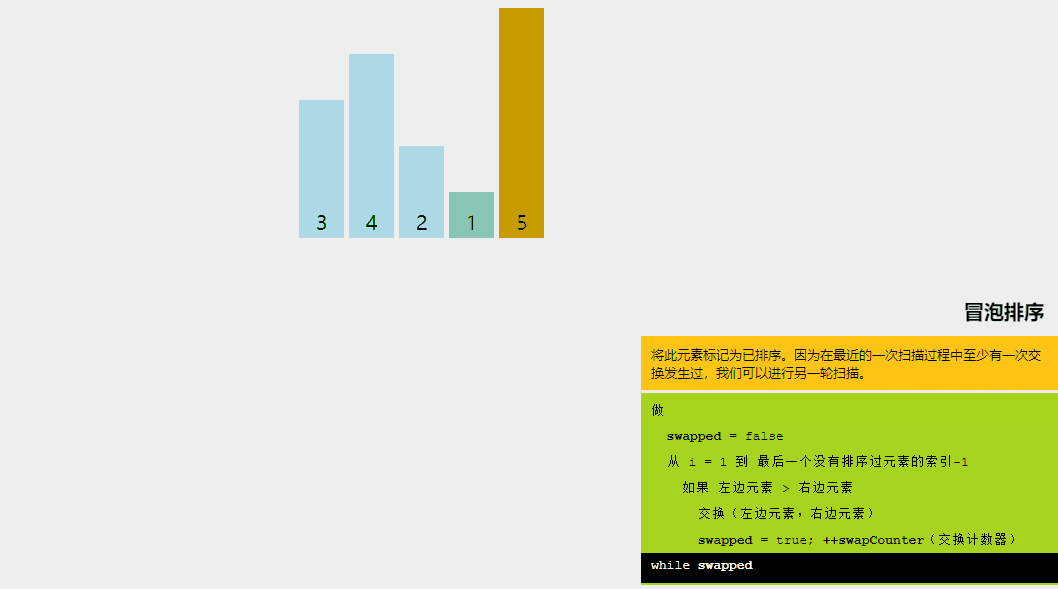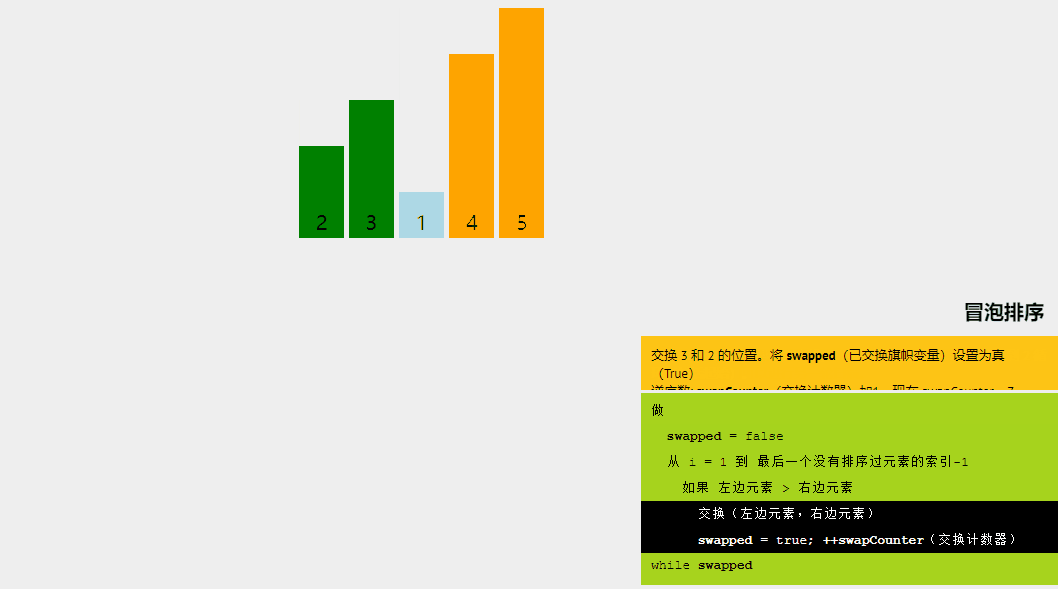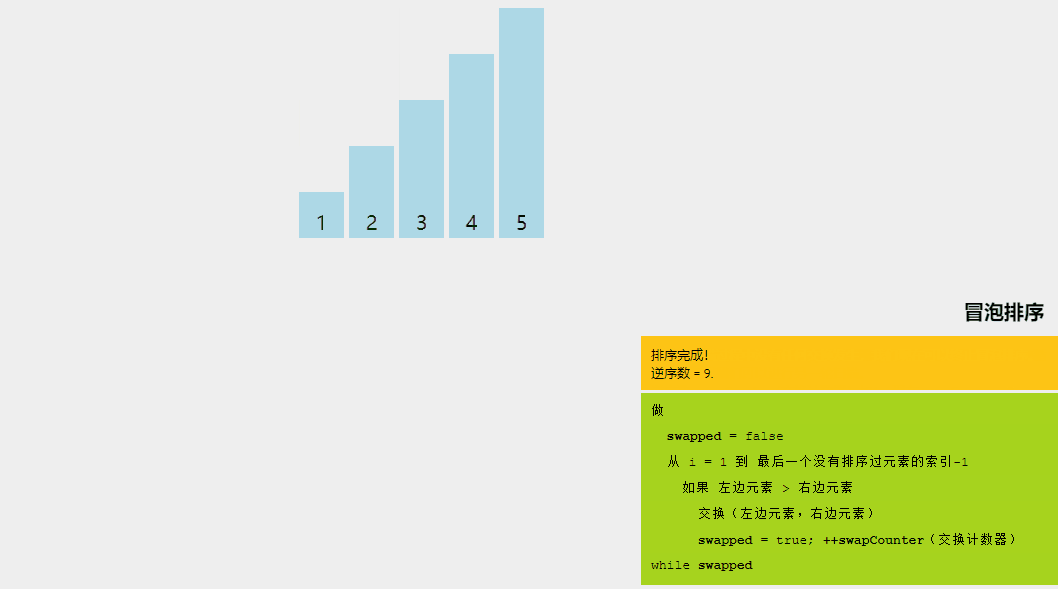
冒泡排序的基本思想是,如果相邻元素的顺序不符合要求,则重复交换相邻元素。是的,就是这么简单。
如果给定的数组元素必须按升序排序,则冒泡排序将首先比较数组的第一个元素与第二个元素,如果结果大于第二个元素,则立即交换它们,然后继续比较第二个和第三个元素,依此类推。
让我们尝试通过一个例子来理解冒泡排序背后的直观方法:

冒泡排序算法解释
Java 中的实现
import java.util.Arrays;
public class BubbleSort {
public static void bubbleSort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
public static void main(String[] args) {
int[] arr = {5, 3, 4, 2, 1};
bubbleSort(arr);
System.out.println("Sorted array: ");
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
}冒泡排序的实现
时间复杂度:
- 最坏情况: O(n^2)
- 平均情况:O(n*logn)
- 最好的情况:O(n*logn)
空间复杂度: O(1)。
2、选择排序
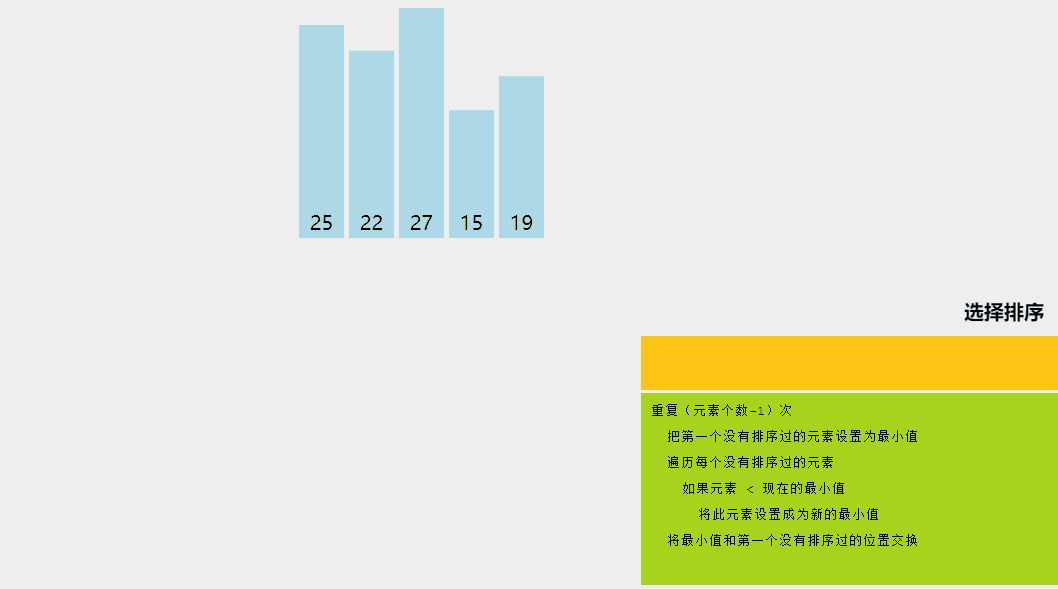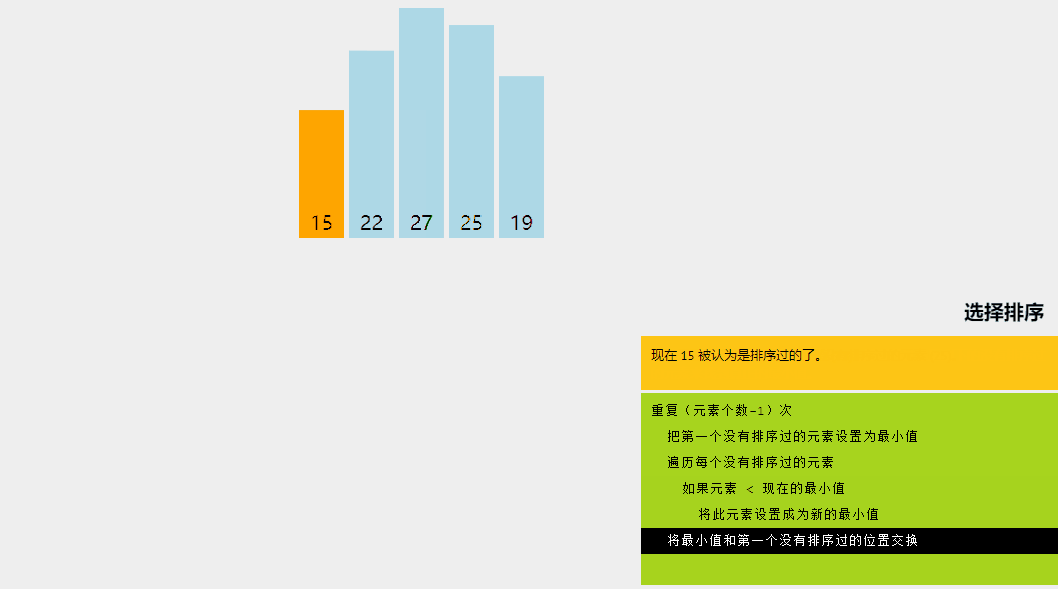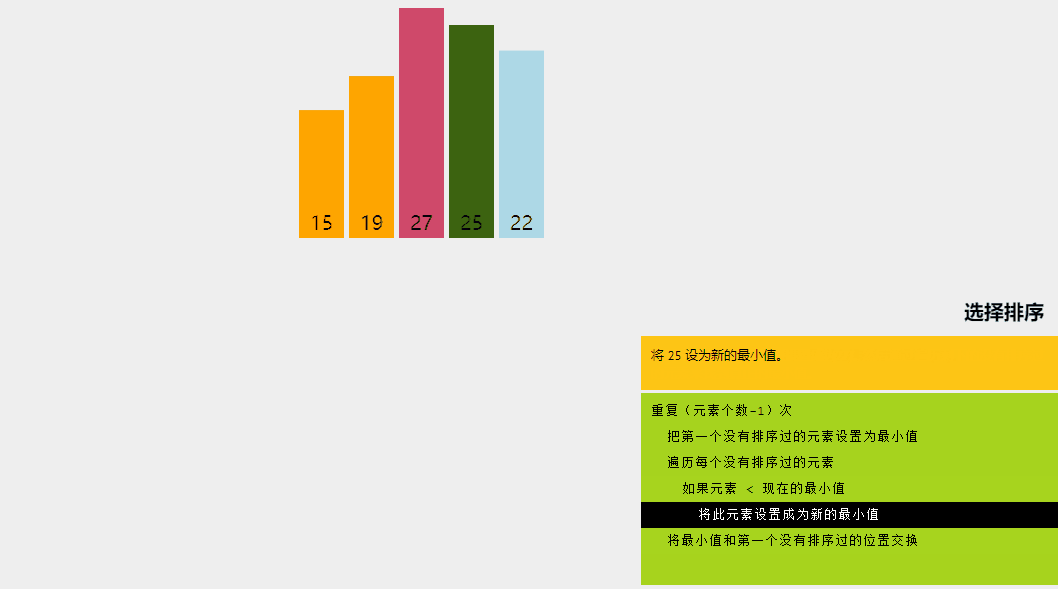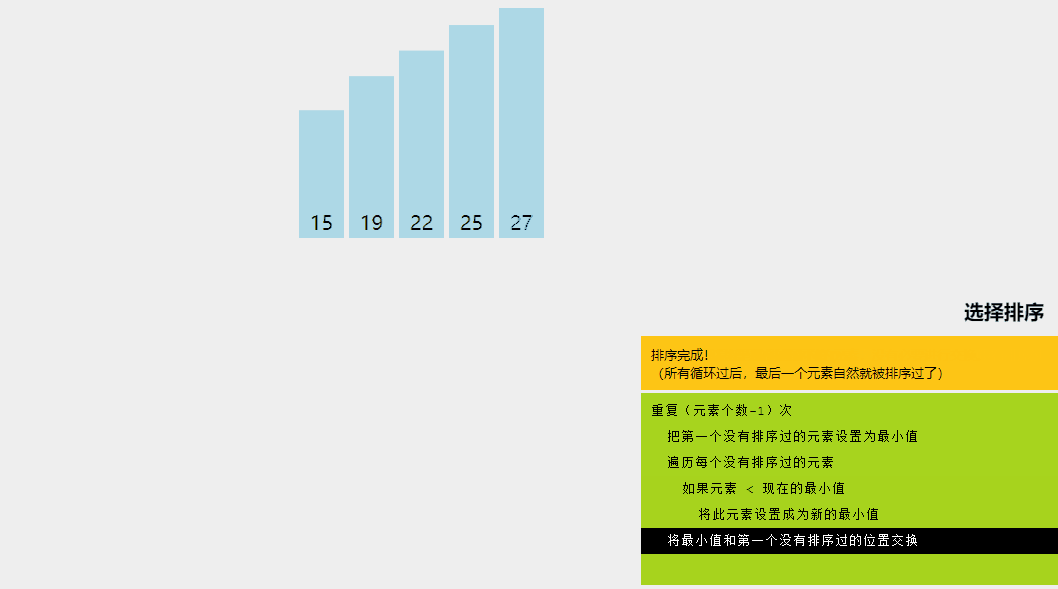
选择排序是一种排序算法,其中给定数组分为两个子数组:已排序的左部分和未排序的右部分。
最初,已排序部分为空,未排序部分是整个列表。在每次迭代中,我们从未排序列表中获取最小元素并将其推送到已排序列表的末尾,从而构建已排序的数组。
让我们尝试用一个简单的例子来理解选择排序背后的直观想法:

选择排序算法解释
Java 中的实现
import java.util.Arrays;
public class SelectionSort {
public static void selectionSort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
int temp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = temp;
}
}
public static void main(String[] args) {
int[] arr = {25, 22, 27, 15, 19};
selectionSort(arr);
System.out.println("Sorted array:");
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
}选择排序的实现
时间复杂度:
- 最坏情况: O(n*n)
- 平均情况: O(n*logn)
- 最好情况: O(n*logn)
空间复杂度: O(1)。
3、插入排序

插入排序是一种将给定数组分为已排序部分和未排序部分的排序算法。在每次迭代中,要插入的元素必须在已排序的子序列中找到其最佳位置,然后插入,同时将剩余元素向右移动。
通过示例了解插入排序算法。
下面是一个例子,可以帮助更好地理解插入排序:

插入排序算法解释
现在已经了解了插入排序的实际工作原理,接下来看一下 Java的 实现。
import java.util.Arrays;
public class InsertionSort {
public static void insertionSort(int[] arr) {
int n = arr.length;
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
public static void main(String[] args) {
int[] arr = {25, 22, 27, 15, 19};
insertionSort(arr);
System.out.println(Arrays.toString(arr));
}
}插入排序的实现
时间复杂度:
- 最坏情况: O(n*n)
- 平均情况: O(n*logn)
- 最好情况: O(n*logn)
空间复杂度: O(1)。
4、快速排序
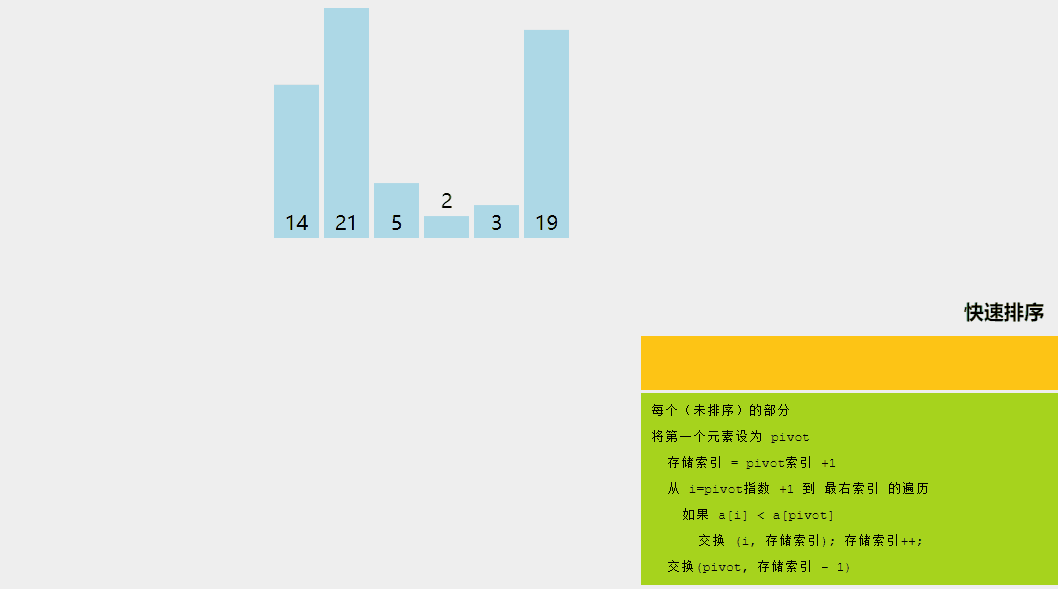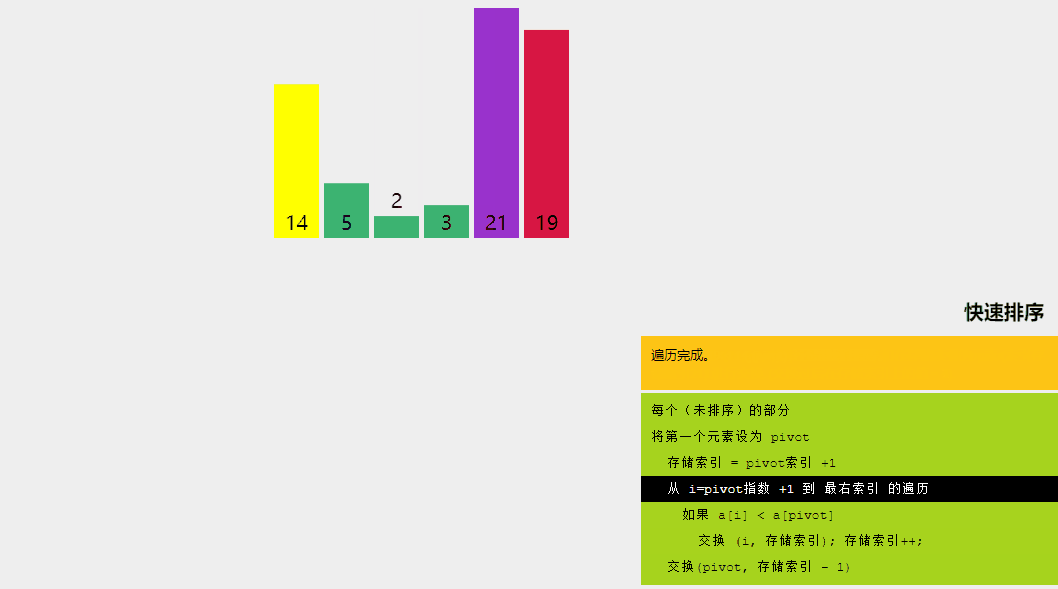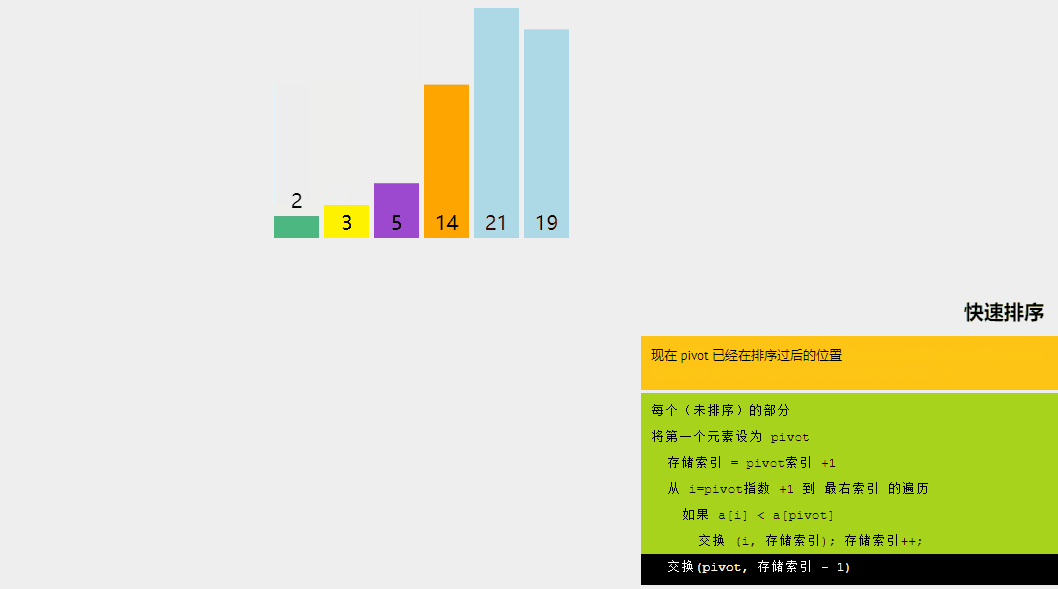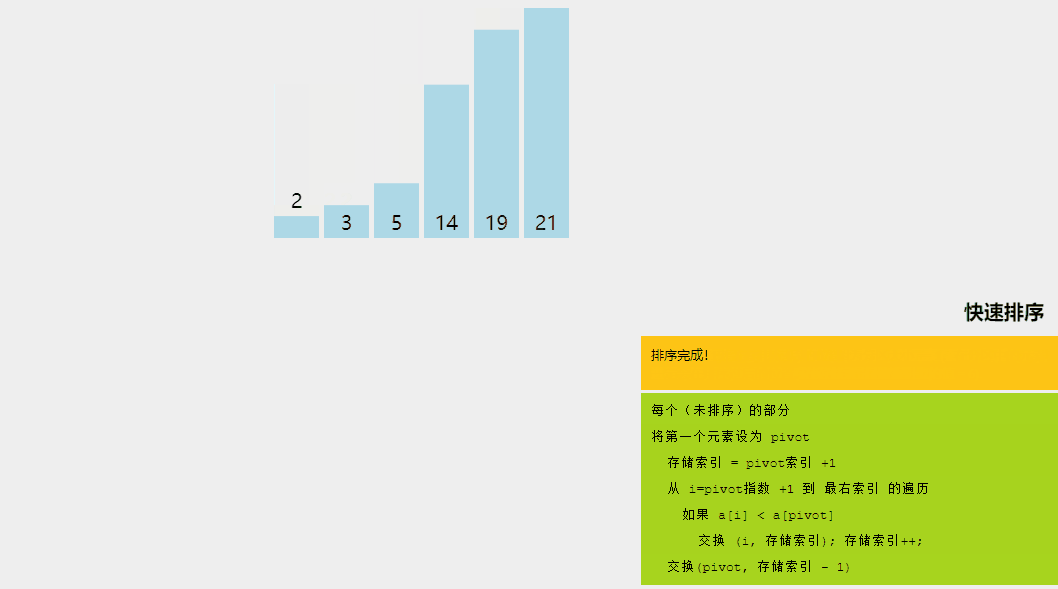
快速排序是一种分而治之的算法。快速排序背后的直观概念是,它从给定的元素数组中选择一个元素作为主元,然后围绕主元元素对数组进行分区。随后,它递归地调用自身并随后对两个子数组进行分区。
通过可视化了解快速排序算法。
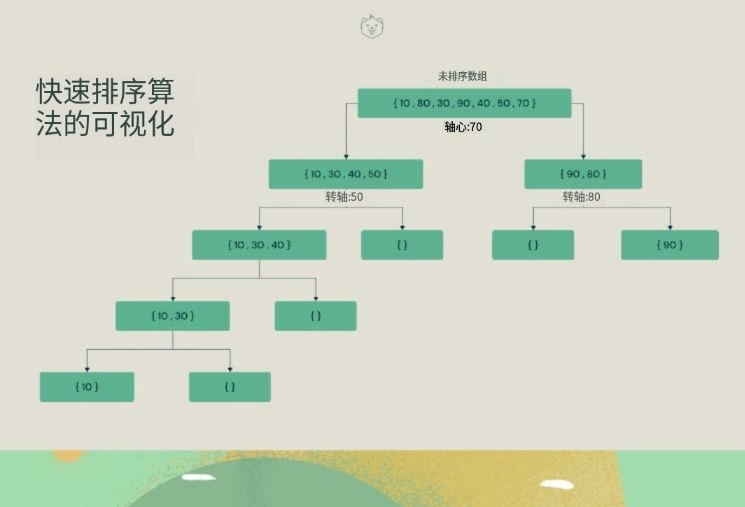
快速排序算法涉及的逻辑步骤如下:
- 枢轴选择:选择一个元素作为枢轴(这里,我们选择最后一个元素作为枢轴)。
- 分区:数组的分区方式使得所有小于主元的元素都位于左子数组中,而所有严格大于主元的元素都存储在右子数组中。
- 递归调用快速排序:对上面创建的两个子数组再次调用快速排序函数,并重复步骤。
下面的实现中包含了注释,以帮助更好地理解快速排序算法。
import java.util.Arrays;
public class QuickSort {
public static int partition(int[] arr, int low, int high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j <= high - 1; j++) {
if (arr[j] < pivot) {
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high);
return i + 1;
}
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
int partitionIndex = partition(arr, low, high);
quickSort(arr, low, partitionIndex - 1);
quickSort(arr, partitionIndex + 1, high);
}
}
public static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
int[] arr = {14, 21, 5, 2, 3, 19};
int n = arr.length;
quickSort(arr, 0, n - 1);
System.out.print("Sorted array: ");
for (int i = 0; i < n; i++) {
System.out.print(arr[i] + " ");
}
}
}快速排序的实现
时间复杂度:
- 最坏情况: O(n*n)
- 平均情况: O(n*logn)
- 最好情况: O(n*logn)
空间复杂度: O(1)。
5、随机快速排序
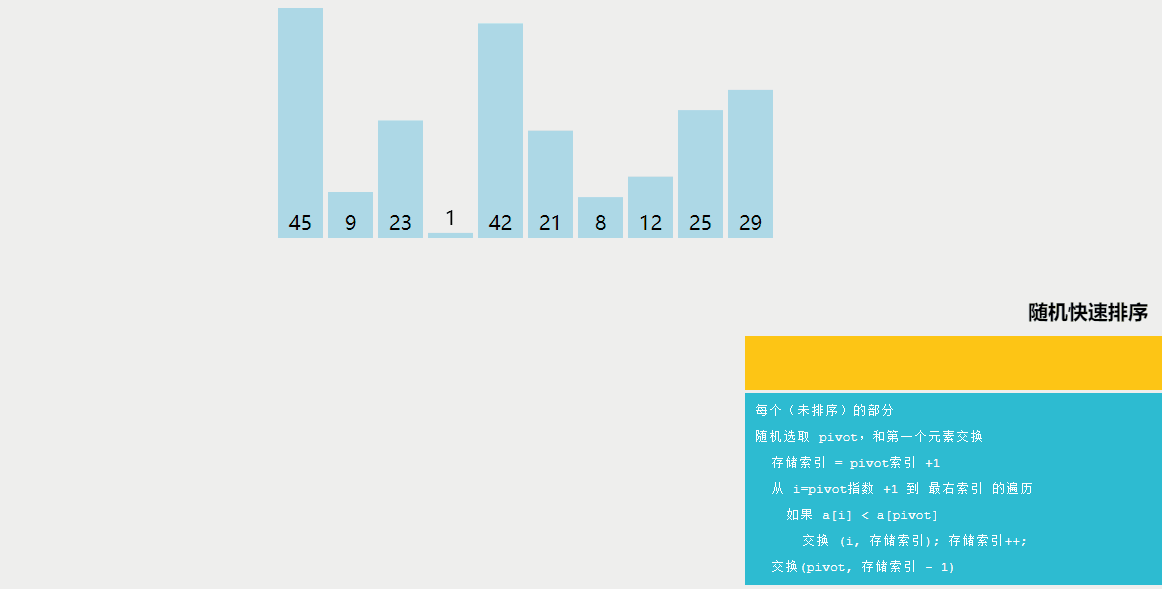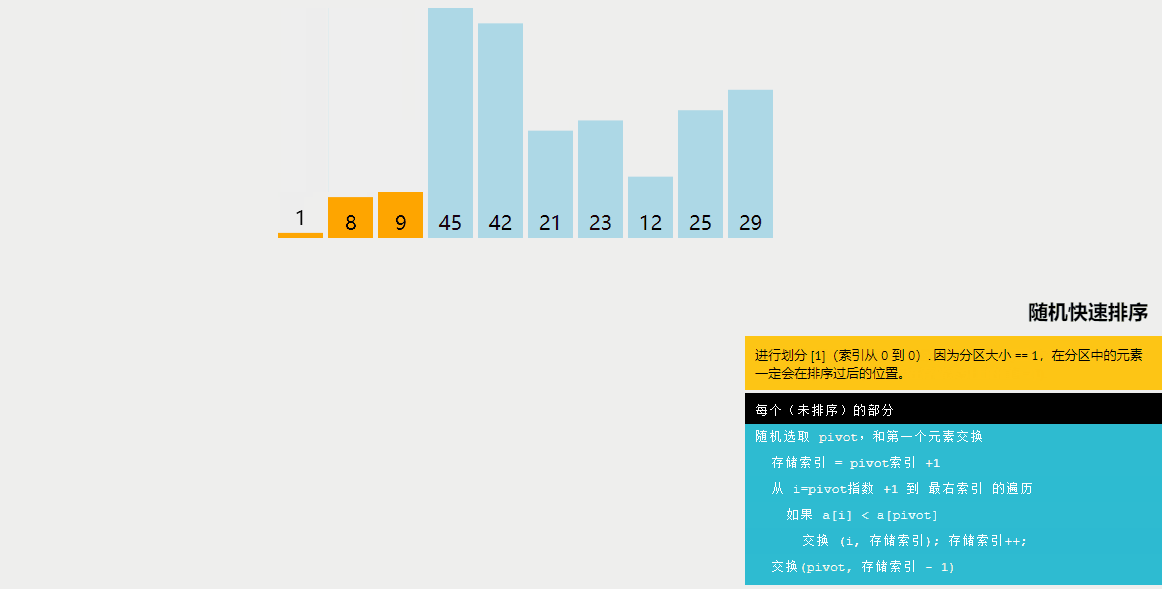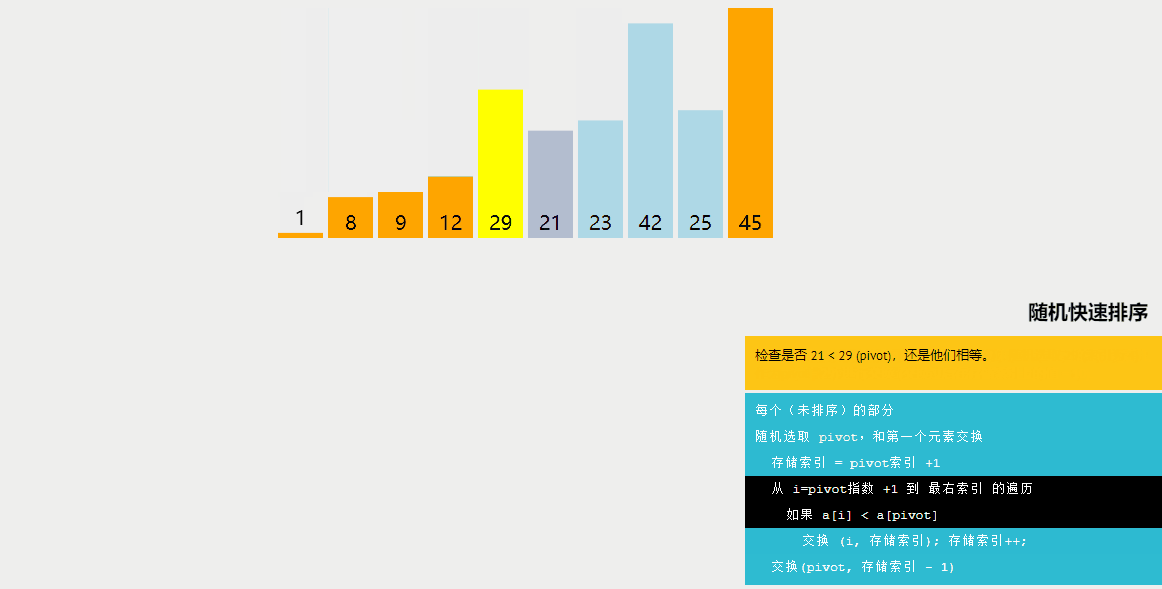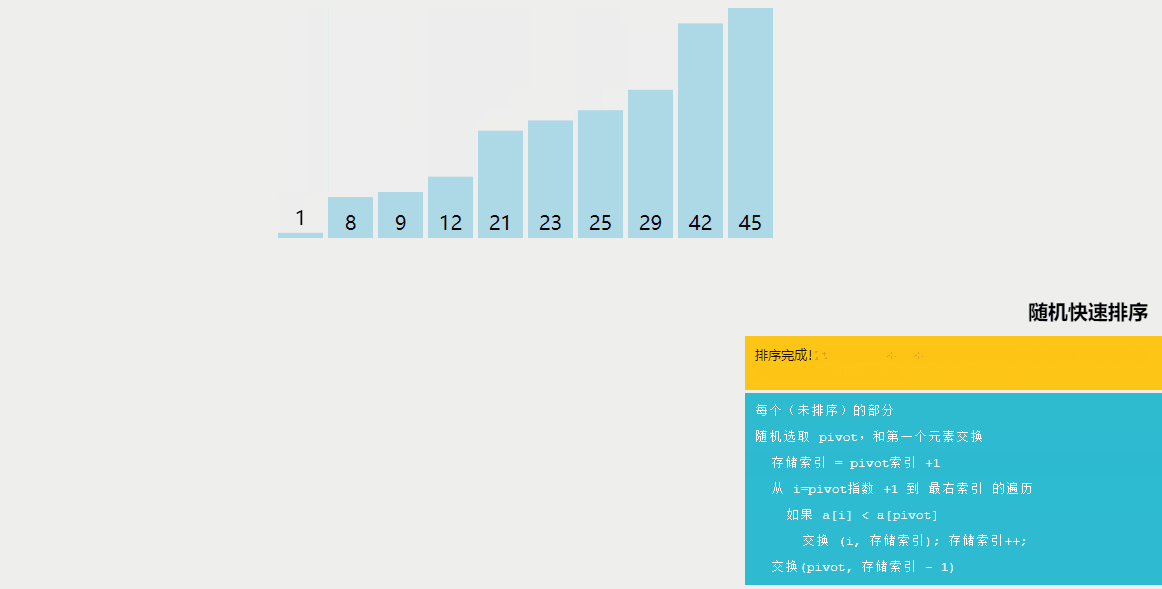
随机快速排序与快速排序的区别:
快速排序是一种分治算法,通过选择一个基准元素(通常是数组中的一个元素),将数组划分为两个子数组,一个子数组中的所有元素都小于基准元素,另一个子数组中的所有元素都大于基准元素。然后递归地对这两个子数组进行排序。快速排序的平均时间复杂度为O(nlogn)。
随机快速排序与快速排序的不同之处在于选择基准元素的方式。在快速排序中,通常选择数组的第一个或最后一个元素作为基准元素。而在随机快速排序中,首先从数组中随机选择一个元素作为基准元素,然后进行划分。
随机快速排序的主要优点是减少了快速排序中最坏情况出现的概率。在快速排序中,如果选择的基准元素是数组中的最小或最大元素,或者数组已经是有序的,那么划分结果可能会非常不平衡,导致算法的时间复杂度接近O(n^2)。通过随机选择基准元素,可以有效地降低这种情况发生的概率,提高算法的平均性能。
因此,随机快速排序相对于快速排序来说,具有更好的性能保证,尤其是在面对特定情况下的输入数据时。它在实践中通常被认为是快速排序的一种优化版本,可以提供更一致的性能,并减少最坏情况的发生概率。
时间复杂度:
- 最坏情况: O(n*n)
- 平均情况: O(n*logn)
- 最好情况: O(n*logn)
空间复杂度: O(logn)。
6、归并排序
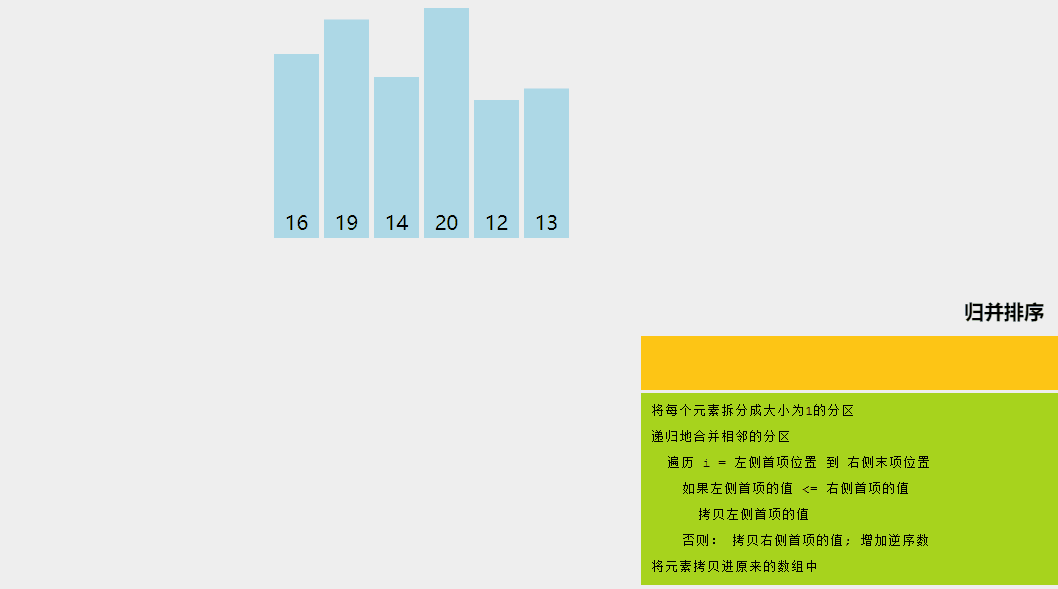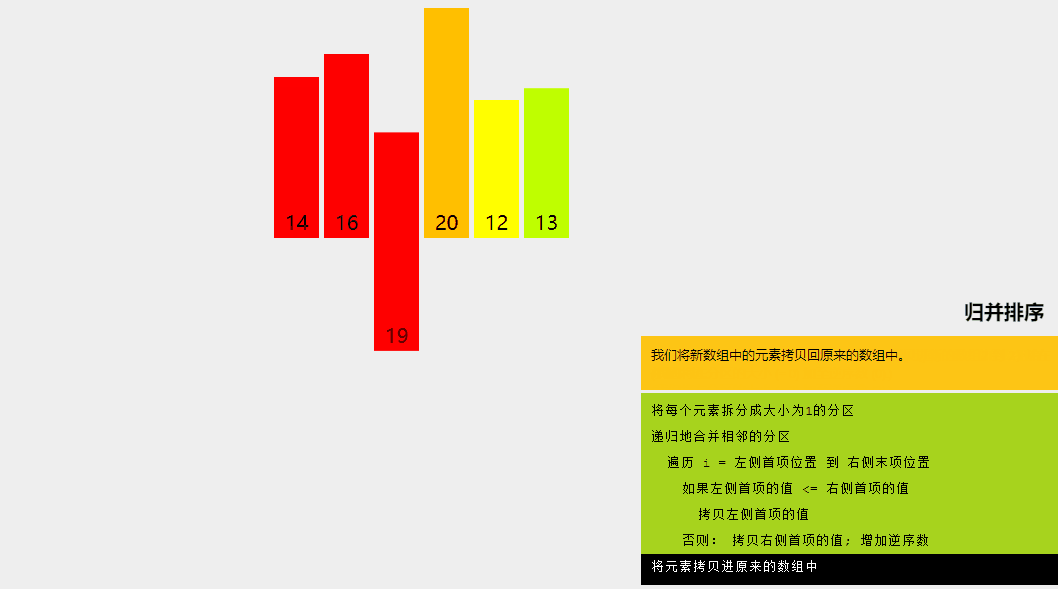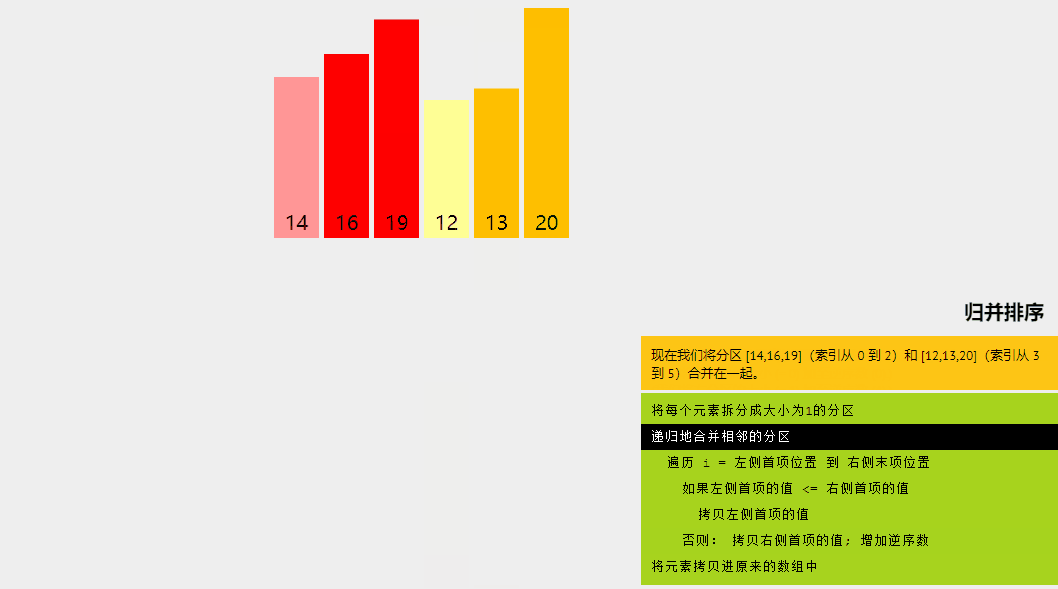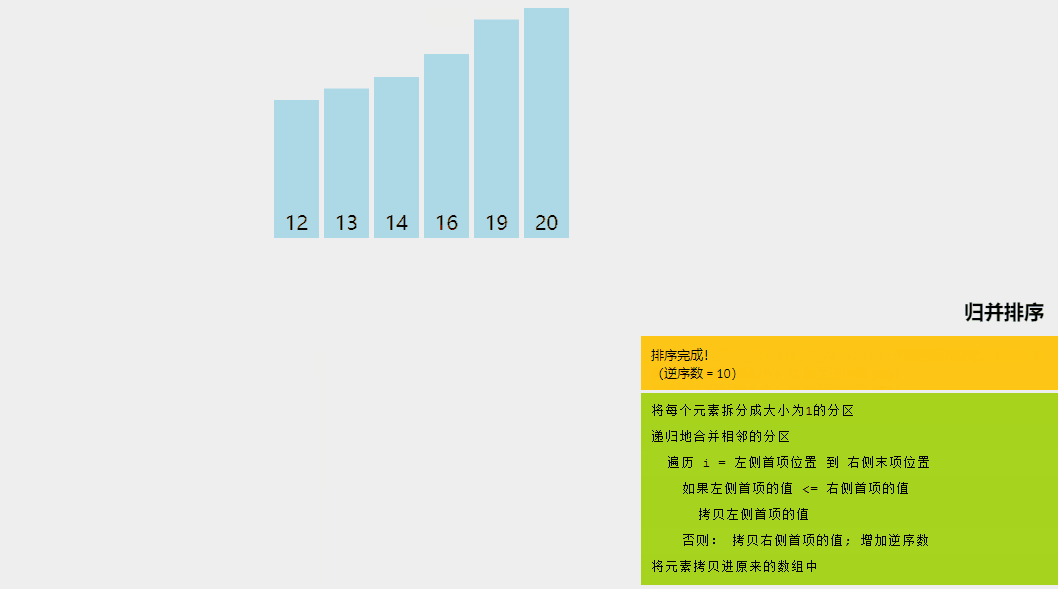
归并排序是一种分而治之的算法。在每次迭代中,归并排序将输入数组划分为两个相等的子数组,为这两个子数组递归地调用自身,最后合并已排序的两半。
通过可视化了解合并排序算法。
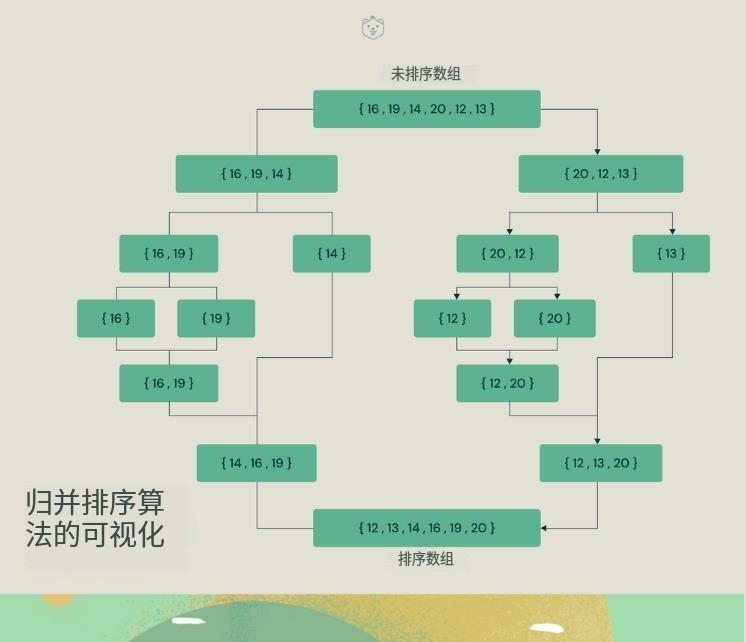
归并排序算法解释
看一下它的实现。
import java.util.Arrays;
public class MergeSort {
public static void merge(long[] arr, long lt, long m, long rt) {
long n1 = m - lt + 1;
long n2 = rt - m;
long[] L = new long[(int) n1];
long[] R = new long[(int) n2];
for (int i = 0; i < n1; i++)
L[i] = arr[(int) (lt + i)];
for (int j = 0; j < n2; j++)
R[j] = arr[(int) (m + 1 + j)];
int i = 0, j = 0;
int k = (int) lt;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
public static void mergeSort(long[] arr, long lt, long rt) {
if (lt >= rt)
return;
long m = lt + (rt - lt) / 2;
mergeSort(arr, lt, m);
mergeSort(arr, m + 1, rt);
merge(arr, lt, m, rt);
}
public static void printArray(long[] arr) {
for (int i = 0; i < arr.length; i++)
System.out.print(arr[i] + " ");
}
public static void main(String[] args) {
long[] arr = {16, 19, 14, 20, 12, 13};
System.out.print("Unsorted array is: ");
printArray(arr);
mergeSort(arr, 0, arr.length - 1);
System.out.print("\nSorted array is: ");
printArray(arr);
}
}归并排序的实现
时间复杂度:
- 最坏情况: O(n*logn)
- 平均情况: O(n*logn)
- 最好情况: O(n*logn)
空间复杂度: O(n)。
7、计数排序
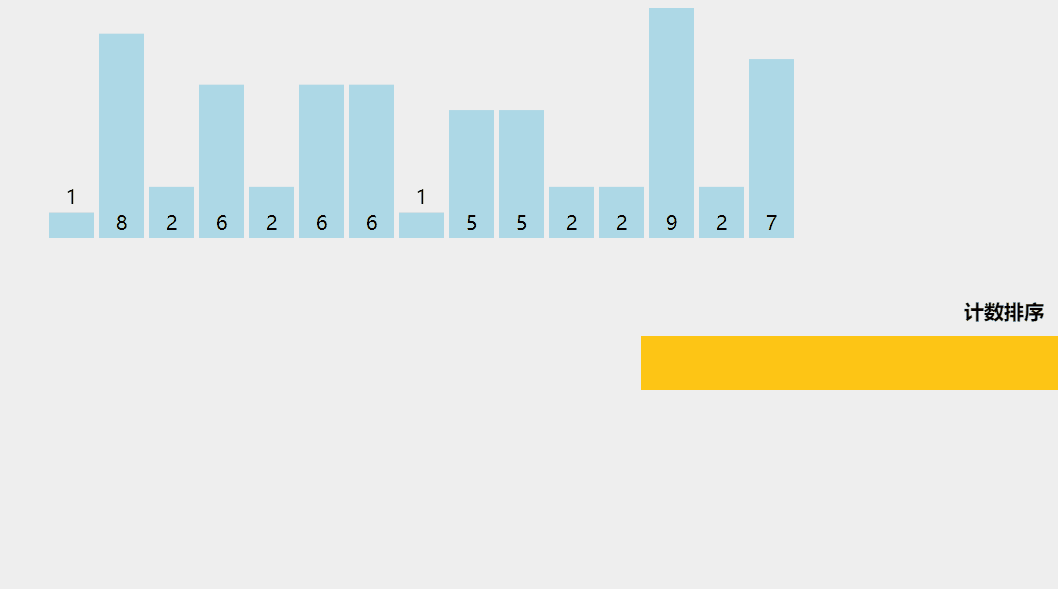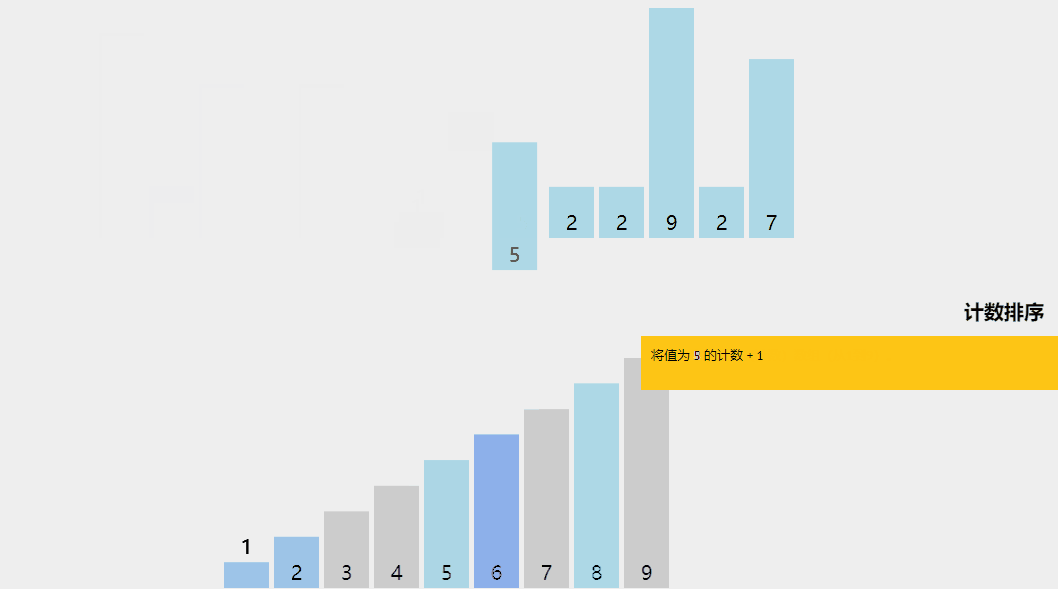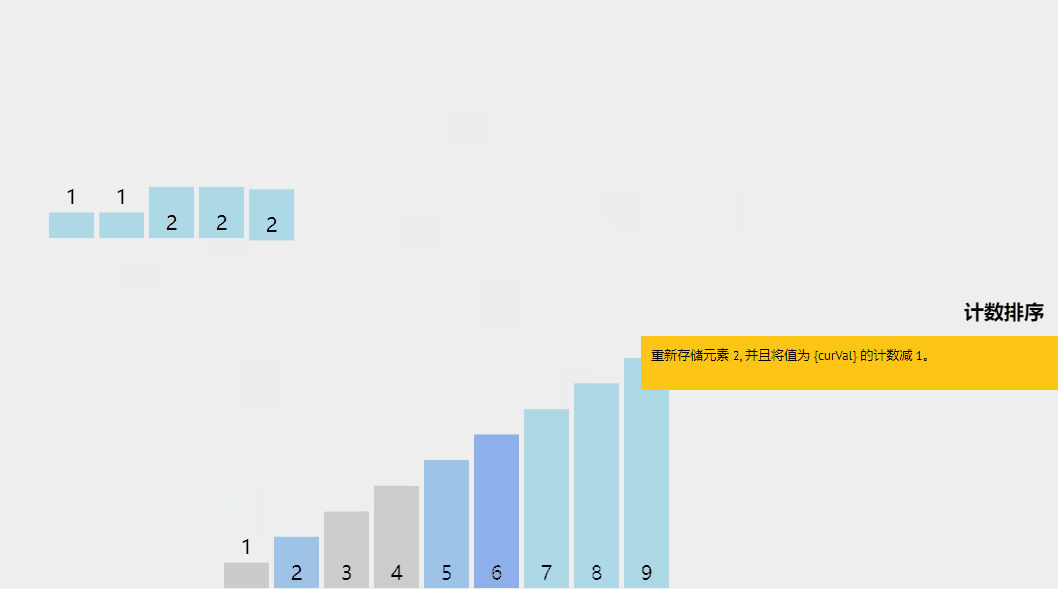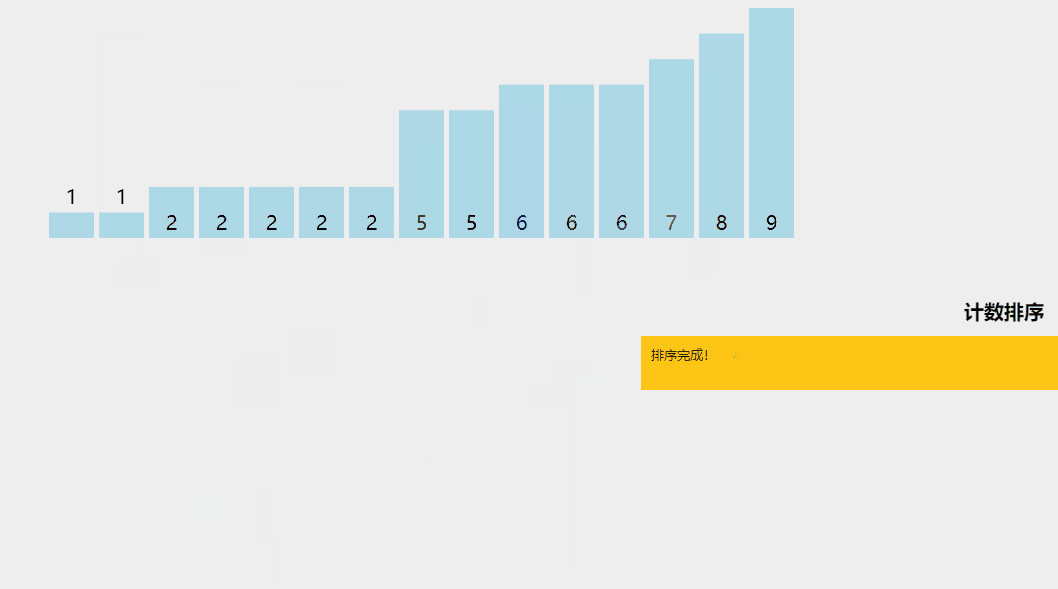
计数排序是一种有趣的排序技术,主要是因为它关注特定范围内唯一元素的频率(类似于散列)。
它的工作原理是计算具有不同键值的元素数量,然后在计算未排序序列中每个唯一元素的位置后构建排序数组。
它与上面列出的算法不同,因为它实际上涉及输入数据元素之间的零比较!
通过示例了解计数排序算法。

计数排序算法解释
现在继续看一下它在 Java 中的实现。
import java.util.Scanner;
public class CountSort {
public static void print(long[] vec, long n) {
for (long i = 1; i <= n; i++)
System.out.print(vec[(int) i] + " ");
System.out.println();
}
public static long getMax(long[] vec, long n) {
long max = vec[1];
for (long i = 2; i <= n; i++) {
if (vec[(int) i] > max)
max = vec[(int) i];
}
return max;
}
public static void countSort(long[] vec, long n) {
long[] output = new long[(int) (n + 1)];
long max = getMax(vec, n);
long[] count = new long[(int) (max + 1)];
for (int i = 0; i <= max; i++)
count[i] = 0;
for (long i = 1; i <= n; i++)
count[(int) vec[(int) i]]++;
for (int i = 1; i <= max; i++)
count[i] += count[i - 1];
for (long i = n; i >= 1; i--) {
output[(int) count[(int) vec[(int) i]]] = vec[(int) i];
count[(int) vec[(int) i]] -= 1;
}
for (long i = 1; i <= n; i++) {
vec[(int) i] = output[(int) i];
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.print("Enter the size of array: ");
long n = scanner.nextLong();
long[] arr = new long[(int) (n + 1)];
System.out.println("Enter elements:");
for (long i = 1; i <= n; i++)
arr[(int) i] = scanner.nextLong();
System.out.print("Unsorted array: ");
print(arr, n);
countSort(arr, n);
System.out.print("Sorted array: ");
print(arr, n);
scanner.close();
}
}计数排序实现
时间复杂度:
- 最坏情况: O(n+k),其中 n 是输入数组的大小,k 是数组中唯一元素的数量。
空间复杂度: O(n+k)。
8、基数排序

正如之前所看到的,计数排序之所以与众不同,是因为它不是像合并排序或冒泡排序那样基于比较的排序算法,从而将其时间复杂度降低到线性时间。
但是,如果输入数组的范围从 1 到 n^2,计数排序就会失败,在这种情况下,其时间复杂度会增加到 O(n^2)。
基数排序背后的基本思想是扩展计数排序的功能,以便在输入数组元素范围从 1 到 n^2 时获得更好的时间复杂度。
通过示例了解基数排序。
算法:
对于每个数字 i,其中 i 从数字的最低有效数字到最高有效数字变化,根据第 i 个数字使用计数排序算法对输入数组进行排序。请记住,我们使用计数排序,因为它是一种稳定的排序算法。
例子:

基数排序算法解释
因此,我们观察到基数排序在整个执行过程中使用计数排序作为其子例程。现在看一下它的 Java实现。
import java.util.Arrays;
public class RadixSort {
public static void getMax(long[] vec, int n) {
long maxval = vec[0];
for (int i = 1; i < n; i++) {
if (vec[i] > maxval) {
maxval = vec[i];
}
}
}
public static void countSort(long[] vec, int n, long x) {
long[] res = new long[n];
long[] count = new long[10];
Arrays.fill(count, 0);
for (int i = 0; i < n; i++) {
count[(int)((vec[i] / x) % 10)]++;
}
for (int i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
for (int i = n - 1; i >= 0; i--) {
res[(int)(count[(int)((vec[i] / x) % 10)] - 1)] = vec[i];
count[(int)((vec[i] / x) % 10)]--;
}
for (int i = 0; i < n; i++) {
vec[i] = res[i];
}
}
public static void radixSort(long[] vec, int n) {
long m = vec[0];
for (int i = 1; i < n; i++) {
if (vec[i] > m) {
m = vec[i];
}
}
for (long x = 1; m / x > 0; x *= 10) {
countSort(vec, n, x);
}
}
public static void main(String[] args) {
long[] vec = { 53, 89, 150, 36, 633, 233 };
int n = vec.length;
radixSort(vec, n);
for (int i = 0; i < n; i++) {
System.out.print(vec[i] + " ");
}
}
}基数排序实现
时间复杂度: O(d(n+b)),其中b代表数组元素的基数(例如- 10代表十进制)
空间复杂度: O(n+d),其中 d 是数组元素中的最大位数。
总结
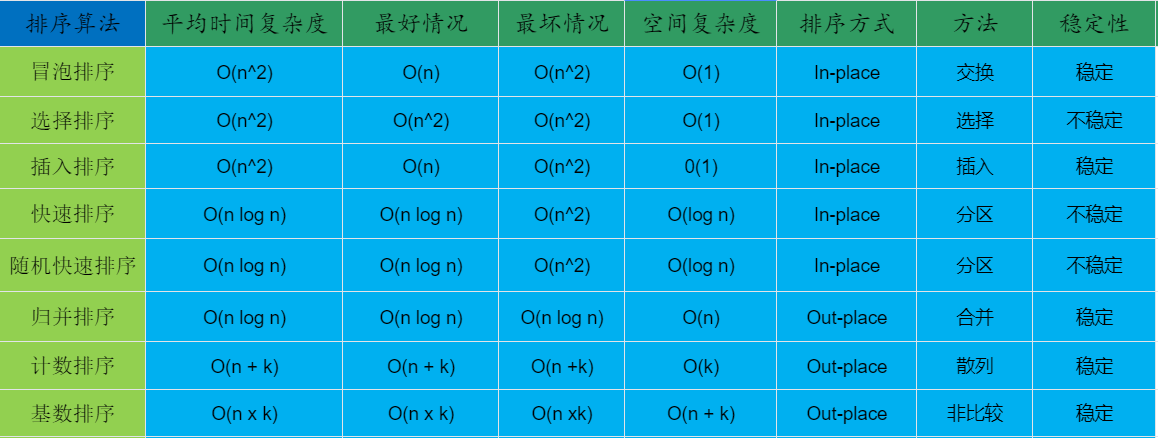
排序算法总结
名词解释:
- n:数据规模
- k:“桶”的个数
- In-place:占用常数内存,不占用额外内存
- Out-place:占用额外内存
- 稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同