












作者 | 崔皓
审校 | 重楼
摘要
AutoGen是基于AI Agent的框架,通过模拟人类决策过程来解决复杂问题。它利用AI Agent来处理大量数据,做出快速决策,并优化用户交互。具备数据处理、自动化决策、用户交互和复杂问题解决能力的AutoGen,为用户提供了处理复杂问题的新思路。通过构建包含多个AI代理的应用程序,AutoGen简化了LLM应用程序的构建过程,并支持多样化的对话模式,提升了效率和生产力。

本文中,我们通过一个具体的例子——A股小助手,展示了如何使用AutoGen框架。在这个示例中,用户通过代理发起请求,助手代理通过自动生成和验证代码的方式,协助用户完成了股票数据的下载、分析和图表绘制任务。
从AI Agent开始
在当今时代,人工智能技术已深入渗透到我们生活和工作的方方面面,从简化日常任务到优化复杂的业务流程,AI的影响无处不在。然而,尽管AI技术的发展迅速,但在处理一些特别复杂的问题时,它仍然面临挑战。这些问题往往涉及到大量数据的处理、复杂决策的制定,以及对动态环境的快速适应,这些都是传统AI系统难以克服的难题。
正是在这种背景下,AI Agent的概念应运而生。AI Agent是一种特殊类型的人工智能系统,它通过模拟人类的决策过程来处理复杂的任务。这些智能代理能够处理和分析大量数据,提供快速且准确的解决方案,从而在那些对人类来说过于耗时或复杂的任务中大放异彩。AI Agent的核心优势在于其能够极大地提高处理这些复杂问题的效率和生产力,从而推动技术的进一步发展和应用。
AI Agent解决的具体问题包括:
数据处理和分析:AI Agent能够快速处理和分析大量数据,提供有洞察力的结果,这对于人类来说可能既费时又费力。
自动化决策:在需要快速响应的场景中,AI Agent可以自动做出决策,减少了人为干预的需要。
用户交互:通过聊天机器人等形式,AI Agent能够提供7*24小时的客户服务,改善用户体验。
复杂问题解决:AI Agent能够解决复杂的问题,如预测分析优化问题等,这些通常超出了人类的直接处理能力。
什么是AutoGen
AI Agent为我们提供了一种处理复杂问题的思路,那么如何实现AI Agent呢?那就是AutoGen, AutoGen作为一个框架,提供了创建和管理AI Agent的必要工具和结构。它不仅仅是一个简单的代理实现,而是一个全面的解决方案,使得开发者能够构建复杂的基于多个AI代理的应用程序。
Microsoft AutoGen,用于开发使用多个代理进行对话以解决任务的大型语言模型(LLM)应用程序。AutoGen的代理是可定制的、可对话的,并且无缝地允许人类参与。它们可以在使用LLM人类输入和工具的组合的各种模式下操作。
主要特点:
AutoGen使构建基于多代理对话的下一代LLM应用程序变得简单,它简化了复杂LLM工作流的编排自动化和优化。
它支持复杂工作流的多样化对话模式,并提供了不同复杂度的工作系统示例,展示了AutoGen如何轻松支持多样化的对话模式。
AutoGen提供了增强的LLM推理功能,包括API统一缓存以及高级使用模式,如错误处理多配置推理上下文编程等。
AutoGen不仅功能强大,而且安装简单,通过pip安装:
pip install pyautogen接下来,我们想通过AutoGen示例,让大家对其有更加全面的了解。
A股小助手:用户代理与智能助手
在快节奏的职场环境中,经常会遇到需要对公开的商业数据进行汇总和分析的任务。想象一下,您的老板要求您收集和分析某些关键数据,比如股票市场的表现。这项任务不仅包括搜索和下载相关数据,还涉及到对数据的深入分析,并且需要将分析结果以可视化的形式呈现。这个过程不仅繁琐,而且在处理数据时还存在潜在的风险和偏差,因此,一个能够有效协助您的工具变得至关重要。
在这种情境下,让我们以一个具体的例子来展示如何使用AutoGen来简化这一过程。假设您需要比较中国A股市场中两只知名股票——万科A和招商银行的表现。具体任务是下载这两只股票的历史数据,对它们的收益情况进行比较,并生成相应的分析图表。这不仅需要对数据进行准确的提取和处理,还要求能够以一种清晰直观的方式展示结果。
使用AutoGen,您可以构建一个流程,其中包括多个AI代理,每个代理负责处理流程的不同部分。例如,一个代理可以负责从金融数据库中下载所需的股票数据,另一个代理则专注于数据的分析和处理,最后一个代理则将分析结果转化为易于理解的图表。通过这种方式,AutoGen不仅大大减轻了您的工作负担,还提高了整个分析过程的准确性和效率。最终,您可以向老板展示一份既全面又直观的股票表现对比报告,这份报告不仅基于最新的数据,而且以一种易于理解的图形方式呈现。
思路整理
在开始实现上述功能之前,先让我们把参与者和流程整理一下,如下图所示:
AutoGen处理股票数据比较的过程,有用户、用户代理、用户助手三个参与者。用户负责提出问题。用户代理由AutoGen的对象扮演,它负责理解用户提出的问题,并向用户助手发出命令,如果在执行过程中用户助手遇到问题,用户代理需要对其进行解释。用户助手负责拿出解决方案,生成执行代码,同时还需要评估代码的正确性。最终,将执行的代码交给用户代理执行。
流程的步骤如下:
- 用户提出问题,需要将股票的比较信息通过画图的方式展示出来。
- 用户助手收到问题后,进行理解和解释,随后判断问题的性质,并且转交给用户助手进行执行。
- 用户助手采取相应的处理措施,按照得到的方案生成执行任务,在模拟代码执行的时候发现问题。
- 针对问题,用户助手进行自我修复,再次模拟执行代码。在代码通过执行之后,将其交给用户代理执行。
- 用户代理执行代码之后,将结果返回给用户。
 股票比较流程图
股票比较流程图
代码编写
清楚流程之后我们来看看代码,如下:
# 导入autogen模块。这个模块可能是一个自动生成某些配置的库。
import autogen
# 使用autogen模块中的config_list_from_json函数。
# 此函数的作用是从一个JSON格式的配置文件中创建配置列表。
config_list = autogen.config_list_from_json(
# 第一个参数是JSON配置文件的名称,这里指定的是"OAI_CONFIG_LIST.json"。
# 这个JSON文件包含了一些配置数据。
"OAI_CONFIG_LIST.json",
# 第二个参数是一个字典,它用于过滤配置文件中的内容。
# 这里的字典指定了只选择模型为"gpt-4"的配置。
filter_dict={
"model": ["gpt-4"],
},
)这段代码用于导入AutoGen 的模块并调用其中的 config_list_from_json 函数加载与大模型相关的配置信息。下面按照要求进行解释:
1. 导入模块:
import autogen:导入名为 autogen 的Python模块。这个模块的具体功能未在代码中说明,但根据名称推测,它可能与自动生成配置或代码有关。
2. 函数调用:
config_list_from_json 函数从JSON文件中读取配置,并根据提供的过滤条件生成一个配置列表。
过滤字典:
3. filter_dict:用于过滤JSON文件中的内容。在这个例子中,它指定了["gpt-4"] 作为AutoGen要使用的模型。
接下来看看 OAI_CONFIG_LIST.json文件长什么样子。文件包含了一个JSON数组,每个元素是一个JSON对象,代表一个API配置。这个文件可能被用于存储不同API环境的配置信息,如API密钥和基础URL。
[
{
#大模型的名字
'model': 'gpt-4',
#对应的API的Key
'api_key': '<your OpenAI API key here>',
},
{
'model': 'gpt-4',
'api_key': '<your Azure OpenAI API key here>',
'base_url': '<your Azure OpenAI API base here>',
'api_type': 'azure',
'api_version': '2023-06-01-preview',
},
{
'model': 'gpt-4-32k',
'api_key': '<your Azure OpenAI API key here>',
'base_url': '<your Azure OpenAI API base here>',
'api_type': 'azure',
'api_version': '2023-06-01-preview',
},
]接着重头戏上演,我们创建了两个对象:assistant 和 user_proxy。它们用来创建用户代理和用户助手。用于模拟用户代理和用户助手之间的交互。下面是对代码的逐行解释:
1.创建用户助手 (assistant)
# 创建一个名为'assistant'的AssistantAgent对象,这个对象可能代表一个智能助手。
assistant = autogen.AssistantAgent(
name="assistant", # 名字属性被设置为'assistant'。
llm_config={ # llm_config是一个字典,用于配置助手的行为。
"cache_seed": 42, # 'cache_seed'可能用于初始化随机数生成器,以保持结果的一致性。
"config_list": config_list, # 'config_list'是之前从JSON文件中得到的配置列表。
"temperature": 0, # 'temperature'设置为0,可能用于控制生成内容时的随机性或创造性。
},
)2.创建用户代理 (user_proxy)
# 创建一个名为'user_proxy'的UserProxyAgent对象,这个对象可能代表一个用户界面或代理。
user_proxy = autogen.UserProxyAgent(
name="user_proxy", # 名字属性被设置为'user_proxy'。
human_input_mode="NEVER", # 'human_input_mode'被设置为'NEVER',表明不预期会有来自真人的输入。
max_consecutive_auto_reply=10, # 'max_consecutive_auto_reply'设定在需要用户输入而没有输入时,自动回复的最大次数。
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"), # 'is_termination_msg'是一个函数,用于判断消息内容是否表示终止对话。
code_execution_config={ # 'code_execution_config'配置代码执行的环境。
"work_dir": "coding", # 'work_dir'设定工作目录为'coding'。
"use_docker": False, # 'use_docker'表明在执行代码时不使用Docker容器。
},
)3.初始化聊天和发送消息
# user_proxy使用initiate_chat方法向助手发起聊天,并发送一条消息。
user_proxy.initiate_chat(
assistant, # 指定要发送到的助手。
message="""今天是几号? 请帮我比较万科A股票和招商银行股票的收益情况,用图表的形式对两者进行比较。""", # 发送的消息内容。
)assistant 是一个配置了特定参数的助手代理,可能用于执行某种自动化任务或处理。
user_proxy 是一个模拟用户的代理,配置了自动回复和终止对话的条件。
user_proxy 通过 initiate_chat 方法与 assistant 开启对话,并发送了一个关于比较股票收益的任务描述。
结果展示
在执行代码之后可以产生结果,由于结果内容比较长,涉及到方案的提出,代码生成,代码验证,代码修改等过程。这是一个复杂的自我修正过程,主要体现了用户代理与助手之间的互动中,我把结果的输出整理成如下内容,方便大家阅读:
提问-用户代理To助手:
用户询问了当前的日期,并请求比较万科A股票与招商银行股票的收益情况,并要求以图表形式展示。
得出方案-助手To用户代理:
助手提出了一个解决方案,该方案分为三个主要步骤:
1. 使用Python的datetime库获取当前日期。
2. 利用pandas_datareader库从Yahoo Finance获取股票的历史数据。
3. 使用matplotlib库将数据绘制成图表形式,比较两只股票的收益情况。
然而,当尝试执行获取Yahoo财经数据的代码时遇到了问题,错误提示表明类型错误,字符串索引必须是整数。
再次执行代码-助手To用户代理:
助手建议使用yfinance库来替代pandas_datareader,以解决从Yahoo财经获取数据的问题。在成功安装yfinance库后,助手提供了新的代码片段来重新获取股票数据,并将数据保存到CSV文件中。然后,又提供了另一段代码来创建图表,这次的代码执行成功。
最终得到结果-助手To用户代理:
助手确认万科A和招商银行的历史价格数据已成功获取,并且图表已创建。由于环境限制,助手指出无法直接显示图表,并建议用户在本地环境中运行代码以查看图表。最终,通过发送“TERMINATE”,结束了对话。
AutoGen任务代码
在整个过程中,用户代理与助手之间的交互主要集中在解决问题和代码执行上。助手在诊断并解决问题时表现出适应性和灵活性,最终提供了满足用户请求的结果。
下面我们把用户助理生成的代码放在下面,大家可以参考。这段Python代码用于比较两只股票(万科A和招商银行)的每日收益情况,并将结果以图表形式展示。下面是对每一部分代码的详细解释:
# 导入必要的Python库。
import datetime # 用于处理日期和时间。
import pandas as pd # 用于数据分析和操作。
import matplotlib.pyplot as plt # 用于数据可视化。
import yfinance as yf # 用于从Yahoo Finance下载股票数据。
# 获取当前日期并打印。
today = datetime.date.today()
print("今天是:", today)
# 设置获取股票数据的起始和结束日期。
start_date = '2020-01-01' # 设置起始日期为2020年1月1日。
end_date = today # 设置结束日期为当前日期。
# 使用yfinance下载万科A和招商银行的股票数据。
vanke = yf.download('000002.SZ', start=start_date, end=end_date) # 下载万科A的数据。
cmb = yf.download('600036.SS', start=start_date, end=end_date) # 下载招商银行的数据。
# 计算每日收益率。收益率是通过将每日的收盘价与前一日的收盘价进行比较计算得出的。
vanke['Daily Return'] = vanke['Close'].pct_change() # 计算万科A的每日收益率。
cmb['Daily Return'] = cmb['Close'].pct_change() # 计算招商银行的每日收益率。
# 使用matplotlib创建图表并设置图表大小。
plt.figure(figsize=(12,6))
# 设置图表的标题。
plt.title('Daily Return Comparison')
# 绘制两只股票的每日收益率曲线。
vanke['Daily Return'].plot(label='Vanke A') # 绘制万科A的收益率曲线。
cmb['Daily Return'].plot(label='CMB') # 绘制招商银行的收益率曲线。
# 添加图例。
plt.legend()
# 显示图表。
plt.show()代码整体比较简单,其执行过程如下:
1. 导入所需的库。
2. 获取并打印当前日期。
3. 定义获取股票数据的时间范围。
4. 从Yahoo Finance下载指定日期范围内的万科A和招商银行股票数据。
5. 计算并添加每日收益率到下载的数据中。
6. 绘制并显示两只股票的每日收益率对比图表。
代码中使用的yfinance库是一个流行的金融数据接口,可从Yahoo Finance下载历史市场数据。Matplotlib是一个广泛使用的Python绘图库,可以创建多种静态动态和交互式图表。.pct_change()函数用于计算数据帧中元素的百分比变化,常用于金融数据分析中计算收益率。plt.show()函数调用会打开一个窗口展示生成的图表。在Jupyter Notebook或其他交互式环境中,图表通常会直接显示。
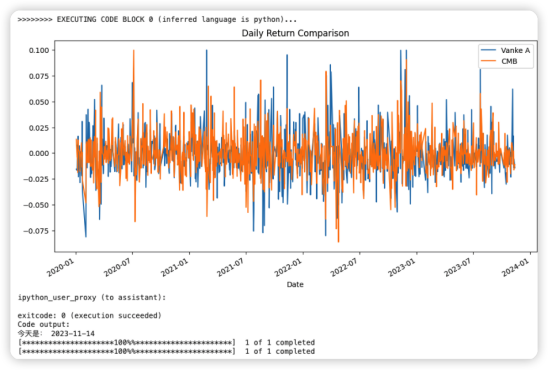 两只股票收益的比较图
两只股票收益的比较图
总结
本文介绍了AutoGen框架及其在金融数据分析中的应用。用户通过代理请求帮助,AutoGen框架的助手代理接收任务后,使用Python代码处理股票数据并绘制比较图表。这个过程展示了AutoGen在处理数据下载、分析和可视化方面的能力。
通过实现一个简单的A股小助手,AutoGen减轻了用户的工作负担,提高了任务执行的准确性和效率。使用AutoGen,即使是复杂的任务,也可以通过构建流程、分配代理和自动化代码执行来简化,从而使用户能够以更直观的方式呈现数据和分析结果。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。















