














背景
我司使用的是亚马逊厂商的云服务,厂商的消息队列产品我们并没有用,我们选择自建,自建的好处是更灵活,定制性更广。公司内部有多套Kafka集群,100+broker节点,针对kafka我司也有比较完善的自动化运维管理体系,最近出现过一次业务连接kafka集群频繁超时的情况,在这里记录下处理过程,加深对网络知识的理解。
问题现象
业务收到服务可用性下降报警,分析日志发现是连接亚马逊kafka集群有频繁超时,超时日志如下:

基本分析
- 影响因素:多台主机同时报警,排查单台主机问题。
- 集群检查:立即确认kafka集群以及涉及到topic健康状态。集群状态正常,收发消息正常,压力负载正常;topic读写正常。
- 变更操作:近期未做关于kafka的任何变更操作,排查变更影响。
- 确定影响范围:确认其他业务是否有超时情况。大部分业务反馈未出现超时情况,问题规模限定在当前业务。
定位
网络问题从表面看不到细节,只能通过抓包分析,同时抓取了客户端和服务端的数据包,抓包命令如下:
说明: 开启抓包后,在客户端主机过滤超时日志,出现超时后即可停止抓包操作。
数据包分析
- 错误日志:
- 2023-05-24 20:46:29.947 kafka client/metadata got error from broker while fetching metadata: read tcp 10.66.67.166:37272->10.68.0.151:9092: i/o timeout
- 客户端报文
- 服务端报文
- 报文分析
- 客户端报文:
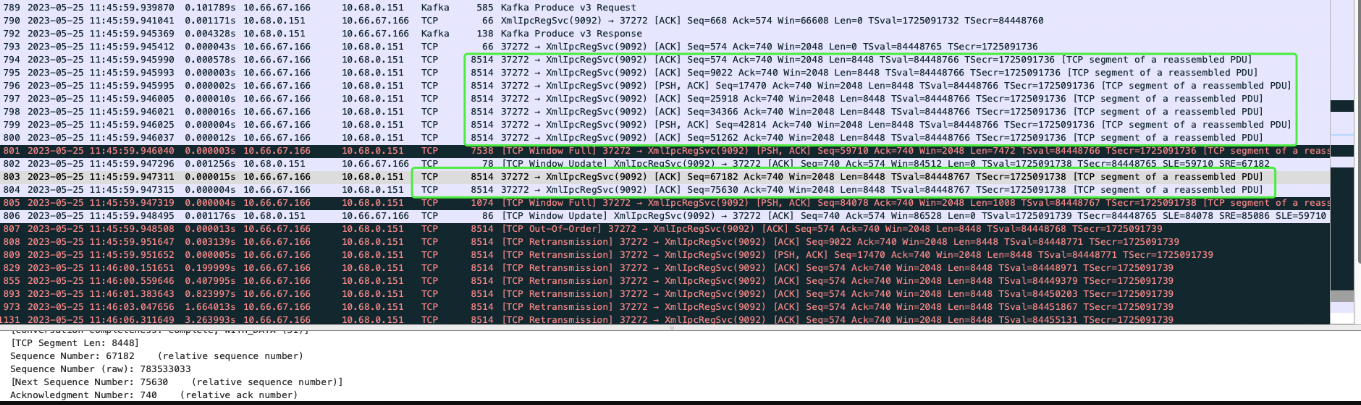
- 在序号为793以上的报文都收到了服务端的响应,而且可以看到使用的是kafka协议进行了消息的投递(kafka produce respone)。
- 在序号为794的时候,客户端发送了7个长度是8514的tcp报文,未看到服务端的回应。
- 在序号是803,804的时候,客户端又发送了2个长度的tcp报文。
- 从序号是807开始,发现客户端重传了之前发送的所有长度是8514的tcp报文。(丢包了。客户端未收到服务端的响应所以重传了)。
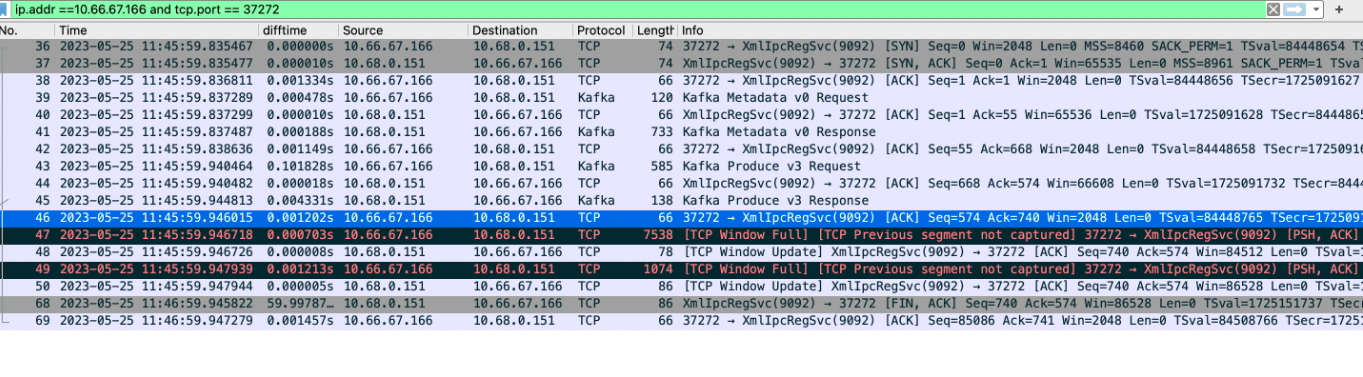
- 服务端报文。
- 从服务端看,客户端前面的几个tcp报文都被服务端正常处理。(前面的报文长度都很小,小于1000)。
- 客户端发送的9个长度为8514的包,服务端根本没收到。
- 服务端等待了60s后,关闭了tcp连接。(服务端配置的空闲连接时间就是1min,符合预期)。
丢包问题分析
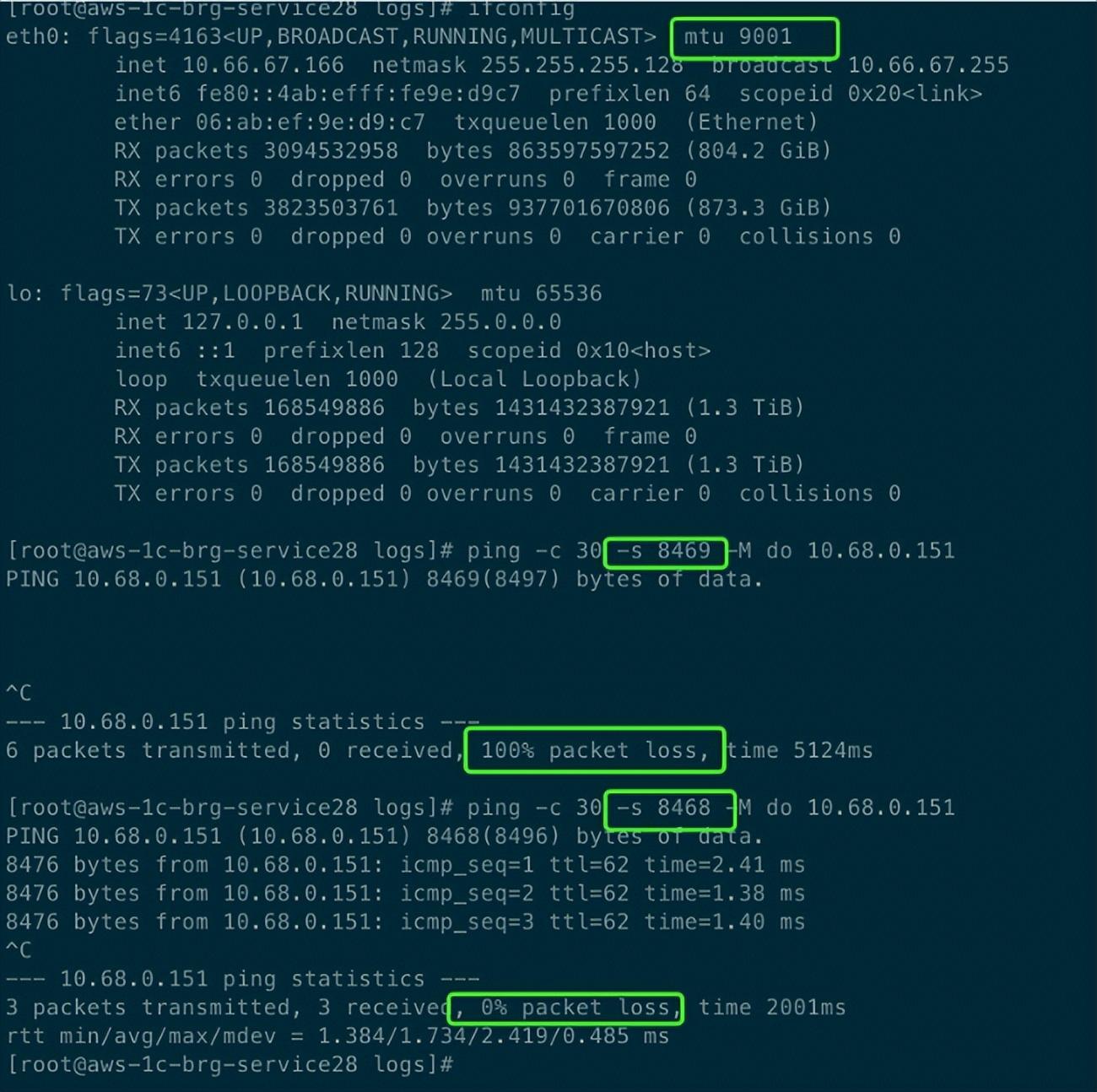
- 被丢弃的数据报长度都比较大,是否是报长度过大的问题?
- 查询机器的网卡mtu配置,发现是9001(TCP/IP 巨型帧),随机使用ping命令指定size进行测试。
- TCP 最大段大小(Max Segment Size,MSS)是会根据网卡设置的mtu值决定,即使设置的是9001,测试最大MSS最大支持到8468,超过后就直接丢了。
- 对比测试规律总结
- 腾讯、阿里主机(mtu=1500):因为网卡配置的都是1500,所以不存在报过大丢弃的情况。
- 亚马逊主机(mtu=9001):包大于8468后,就会直接丢弃(问题产生在新老账户通信上)。
刨根问底
其他亚马逊业务网卡mtu配置配置也是9001,为啥没问题?
- 第一时间和出问题的业务方确认业务是否有调整或者变更,他们说明了服务没有调整,他们在亚马逊有开了一个新账户部署了服务,目前业务访问是跨账户调用。
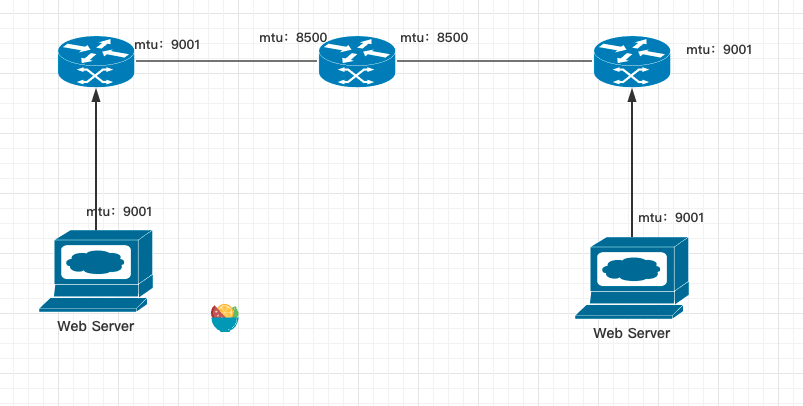
联系厂商确认跨账户网络链路。
- mtu 问题反馈给厂商技术支持人员,给到的结论是:新老账户网络连通设备(TGC),最大的mtu上限是8500,所以我们通过网关设备的包就丢弃了。

解放方案
- 调整主机mtu值,已匹配厂商的mtu限制。











