作者 | 波哥
审校 | 重楼
Spring作为当前使用最广泛的框架之一,其重要性不言而喻。所以充分理解Spring的底层实现原理对于咱们Java程序员来说至关重要,那么今天笔者就详细说说Spring框架中一个核心技术点:如何解决循环依赖问题?

什么是循环依赖问题?
Spring的循环依赖问题是指在使用Spring容器管理Bean的依赖关系时,出现多个Bean之间相互依赖,形成一个循环的依赖关系。这意味着Bean A 依赖于Bean B,同时Bean B 也依赖于Bean A,从而形成一个循环。Spring容器需要确保这些循环依赖关系被正确解决,以避免初始化Bean时出现问题。
如果你去网上搜索“Spring是如何解决循环依赖问题的”,绝大部分答案都是:Spring使用三级缓存确保循环依赖的解决,包括"singletonObjects"、"earlySingletonObjects"和"singletonFactories"等缓存,以及占位符的使用等等。这当然没有错,可是看到这些文章的朋友们,你们真的理解了这其中的原理吗?还是只是会背答案呢?那么,今天笔者就来扒一扒Spring是如何解决这一问题的底层实现原理。当然要明白这个问题的底层实现原理,你得有一定的Spring源码基础才行哦。
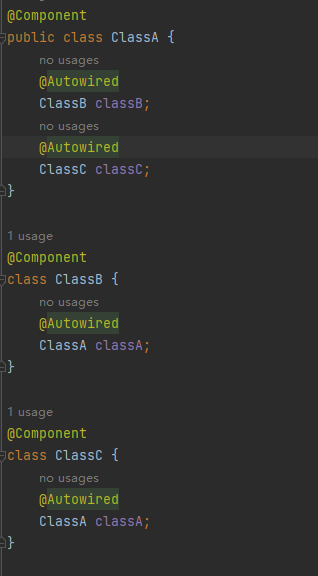
现在假设我们有三个类,ClasssA、ClassB、ClassC,代码如下:
下面,我们根据Spring关于Bean的生命周期管理过程进行分析:
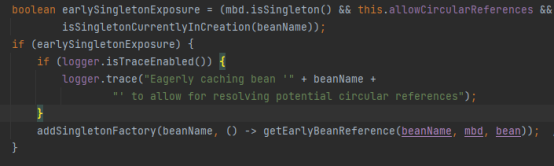
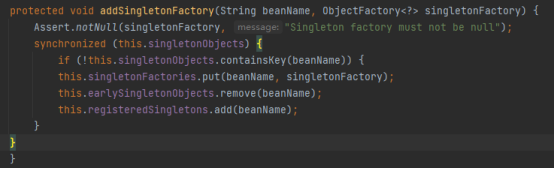
假设首先实例化ClassA。我们知道在ClassA实例化完成后,需要填充属性classB,在填充classB属性之前,会调用addSingletonFactory方法,把一个Lambda表达式添加到了singletonFactories集合中,这个Lambda表达式的代码如下:
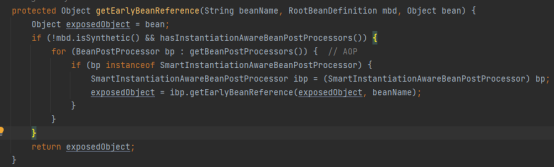
在填充属性时,需要获取到classB的实例对象,也就是说会调用getBean("classB")来走classB这个bean实例的生命周期流程。
在获取classB实例时,首先会调用getSingleton从singletonObjects获取(而这个singletonObjects就是我们平常所说的单例池, 其实就是个map集合):
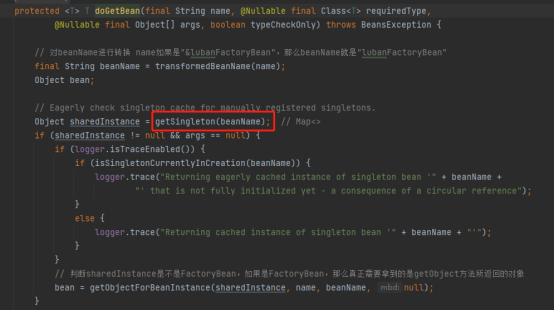
如果单例池中没有才会去创建,那么此时单例池中肯定没有ClassB的实例,所以针对classB实例也会走一遍创建实例的生命周期的流程,同样的也会把上述Lambda表达式添加到singletonFactories集合中。
此时singletonFactories集合中就有了classA和classB的两个表达式。
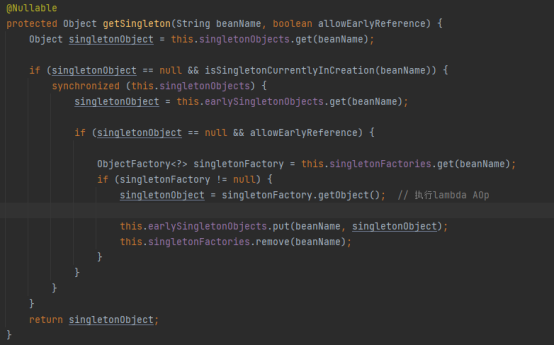
但是这里我们要特别注意classB中需要填充属性classA,所以在填充classB实例的classA属性时,同样需要调用getBean("classA")方法来获取到classA的实例,在获取classA实例时,同样首先会调用getSingleton从单例池中获取:
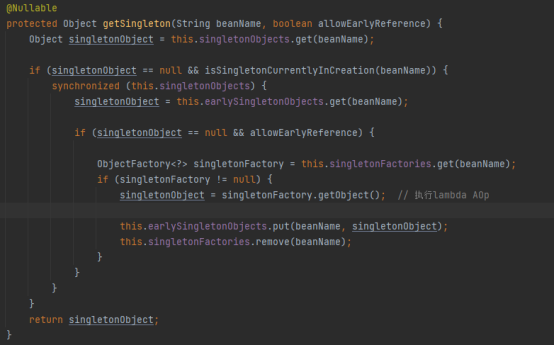
如代码所示,首先会根据beanName从singletonObjects获取,也就是获取classA,很显然,classA还没有放到单例池里面去,只有完全创建好的实例才会放到单例池里面去。可以看到代码同时执行
isSingletonCurrentlyInCreation,此时这个方法返回的是true,内容如下:

那这个isSingletonCurrentlyInCreation方法是干嘛用的呢?看方法名字就知道了,就是判断当前这个bean是否正在创建中,我们在开始创建classA的时候就已经把他的名字添加到singletonsCurrentlyInCreation这个集合中,表明正在创建classA。
很显然满足了if (singletonObject == null &&isSingletonCurrentlyInCreation(beanName))这个条件,于是就进入到if的方法体中。
然后从earlySingletonObjects这个集合中获取对象,那这个earlySingletonObjects又是个啥玩意?只用singletonFactories和singletonObjects两个缓存集合不就好了吗?还要多此一举使用earlySingletonObjects干啥呢?是不是感觉没什么用?千万别这么看,大师们考虑问题比咱们要考虑的周到,不服都不行。
我们这个案例中ClassA依赖ClassB和ClassC,ClassB依赖ClassA,ClassC也依赖ClassA,假如我们没有这个earlySingletonObjects会出现什么情况呢?我们调用singletonFactories.get(beanName)得到前面说的classA的那个Lambda表达式,然后执行
singletonFactory.getObject()就开始执行这个Lambda表达式,在填充ClassB中的classA属性时是不是相当于执行了这个Lambda表达式获取了这个classA对象。
好了,到此为止classA中的classB属性获取到了,接下来填充classC了,上述同样的流程,当填充classC的classA属性时,是不是还得从singletonFactories中获取classA的Lambda表达式,然后再执行那个Lambda表达式,于是执行了两次,正常情况下是没有问题的,因为两个Lambda表达式返回的结果都是classA的实例对象,但是有一种情况下就会有问题了?老铁们此时心中肯定充满疑惑,神马情况呢?
如果执行这个Lambda表达式返回的是classA的代理对象呢?如果执行了两次,是不是就表明classB中的classA属性和classC中的classA属性是两个不同的对象了?这问题可就大了,那么问题又来了,神马情况下会返回classA的代理对象?不卖关子了,直接上答案:在classA需要AOP的情况下,是需要生成代理对象的,而这个生成AOP的骚操作就是在这个Lambda表达式中实现的,我们下面会详细介绍。
所以这里Spring使用了earlySingletonObjects这个我们称为二级缓存的集合来暂存下,这样在classC填充classA属性的时候就不用再次调用lambda表达式了,是不是完美的解决了上述的问题?剩下的几行代码很简单,就不多废话了,大家自己看看就知道了。
总结下,Spring解决循环依赖问题其实就是使用了几个集合类,它们分别是:singletonsCurrentlyInCreation(Set)、singletonFactories(Map)、earlySingletonObjects(Map)、singletonObjects(Map),通过这几个集合的相互配合,最终解决循环依赖问题。
作者介绍
波哥,互联行业从业10余年,先后担任项目总监及架构师。目前专攻技术,喜欢研究技术原理。技术全面,主攻Java,精通JVM底层机制及Spring全家桶底层框架原理,熟练掌握当前主流的中间件、服务网格等技术原理。