












AI大佬的激战再次掀起。
Hinton在线直接点名LeCun,说他对AI接管风险的看法对人类的影响微乎其微。
这意味着,他把自己的意见看得很重,而把许多其他同样有资格的专家的意见看得很轻。

在Hinton看来,他们之间意见分歧的核心论点是「LLM是真正理解自己说什么」。

当然了,一直站在末日派中的Hinton认为大模型有了意识,而LeCun、吴恩达等人却认为LLM不明白自己所说。
对此,LeCun反驳道,大模型显然对其阅读和生成的内容有「一些」理解,但这种理解是非常有限和肤浅的。

总的来说,目前自回归大模型没有对推理和规划能力,远未及人类水平的智能。
恰在近日,LeCun发表了一篇新论文,再提自回归LLM做得不好。

论文中,研究人员介绍了一个通用AI助手基准GAIA。
其中提出了需要一系列基本能力的现实世界问题,比如推理、多模态处理、网页浏览和一般的工具使用熟练程度。

论文地址:https://arxiv.org/pdf/2311.12983.pdf
结果表明,GAIA设计的问题对人类来说简直轻而易举,而对大多数高级AI来说却很有挑战性。
即,人类回答准确率为92%,而用上插件的GPT-4回答准确率仅为15%。
通用人工智能助手基准——GAIA
GAIA的产生,既是因为需要修订AI基准,也是因为发现了LLM评估的不足之处。
研究人员提出的通用人工智能助手的基准——GAIA,包含了466个精心设计的问题和答案,以及相关的设计方法。
这些问题对AI系统具有挑战性,大多数需要复杂的代数。
但又能给出唯一的、符合事实的答案,从而实现简单而稳健的自动评估。

GAIA问题示例
设计选择
第一个原则:瞄准概念上简单但对人类来说可能乏味的问题。
这些问题多种多样的,植根于现实世界,对当前的人工智能系统具有挑战性。
因此,这些问题的设计将重点放在基本能力上,如通过推理快速适应、多模态理解和潜在的多样化工具使用,而不是专业技能上。
问题一般包括查找和转换从不同来源收集到的信息,如提供的文档或开放且不断变化的网络,从而得出准确的答案。
第二个原则:可解释性。
由于高度精选的问题数量有限,因此与汇总问题相比,该基准更易于使用。
任务的概念简单性(人类成功率为 92%)使得用户很容易理解模型的推理轨迹。
第三个原则:对记忆的鲁棒性。
为了完成一项任务,GAIA系统必须计划并成功地完成一些步骤,因为从当前的训练前数据中,得到的答案是设计成纯文本的。
第四个原则:易用性。
研究者的任务是附加文件的简单提示。至关重要的是,问题的答案是事实,简明和明确的。
这些特性允许简单、快速和事实性的评估。
评估
GAIA的设计的评估是自动化的、快速的、真实的。
在实践中,除非另有说明,否则每个问题都需要一个答案,这个答案要么是一个字符串(一个或几个单词) ,一个数字,要么是用逗号分隔的字符串或浮点列表。
每个问题,只有一个正确答案。
因此,评估是通过模型的答案和地面真值之间的准确匹配来完成的。
如下图,回答GAIA问题时,像GPT-4这样的人工智能助手,需要完成几个步骤,可能需要使用工具或者读取文件。

GAIA的构成
想要在GAIA上获得完美的分数,大模型需要先进的推理能力、多模态的理解、编码能力和一般的工具使用,例如网页浏览。
根据解决问题所需步骤的数量和回答问题所需的不同工具的数量,可以将问题分为三个难度增加的级别。
- 1级问题通常不需要任何工具,或者最多只需要一个工具,但不超过5个步骤。
- 第2级问题通常涉及更多的步骤,大约在5到10之间,需要结合不同的工具。
- 第三级是一个近乎完美的普通助理的问题,需要采取任意长的动作序列,使用任意数量的工具,并进入一般的世界。
GPT-4表现如何
使用GAIA评估大型语言模型只需要具备向模型发出提示的能力,即API访问权限。
研究人员在提问前使用一个前缀提示词,以便于提取答案,具体参见下图。

研究人员评估了GPT-4带插件和不带插件的版本,以及以GPT-4为后端的AutoGPT。
目前,GPT-4需要手动选择插件。相反,AutoGPT能够自动进行这一选择。
研究人员采用的的非LLM基准包括人类注释者和网络搜索。对于后者,他们在搜索引擎中输入问题,并检查是否能从搜索结果的第一页中推导出答案。
这使他们能够评估研究人员的问题答案是否可以轻松地在网络上找到。只要API可用,就运行模型三次,并呈现得到的平均结果。
GPT-4插件
与GPT-4不同的是,目前还没有带插件的GPT-4 API,研究人员不得不手动进行ChatGPT查询。
在撰写本文时,用户必须手动在一个高级数据分析模式(具有代码执行和文件读取能力)和最多三个第三方插件之间进行选择。研究人员根据任务给定的最重要功能的最佳猜测,选择第一种模式或选择第三方插件。研究人员通常依赖于:
(i)一个用于阅读各种类型链接的工具,
(ii)一个网络浏览工具,
(iii)一个用于计算的工具。
遗憾的是,目前无法在一段时间内使用一组稳定的插件,因为插件经常更改或从商店中消失。
同样,GPT-4的官方搜索工具也被移除,因为它可能绕过付费墙,但最近又重新推出。因此,研究人员对带插件的GPT4的评分是GPT-4潜力的「预估」,是基于更稳定和自动选择插件的估计。
结果
研究人员的评估结果如下图所示。
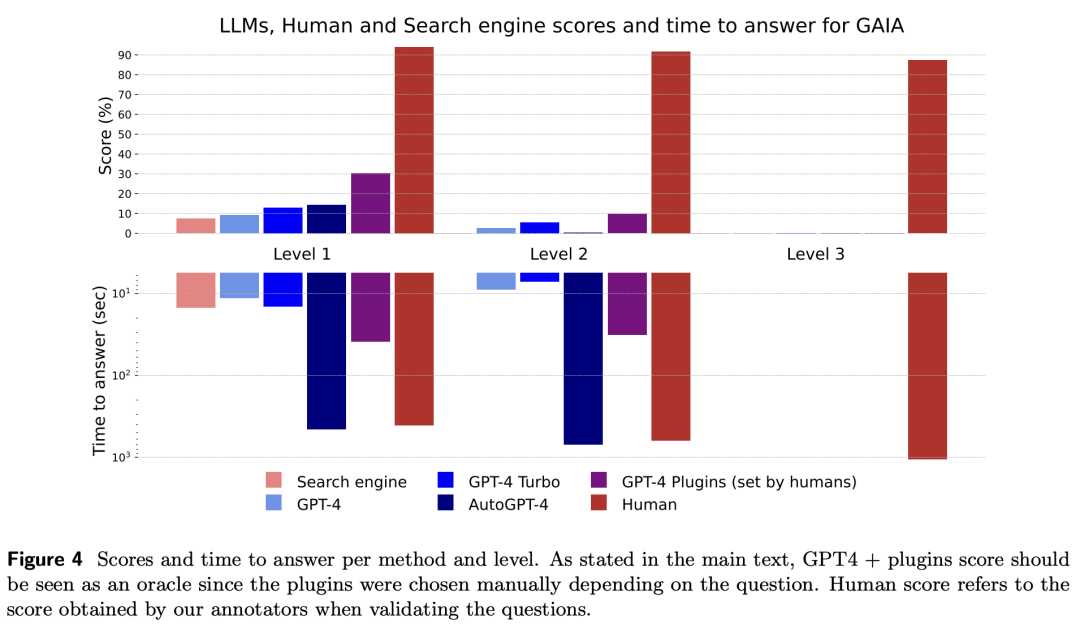
研究人员提出的难度等级,大致根据步骤数量和使用的不同能力数量定义,与当前模型的性能相关,增强了它们的有效性。
虽然人类在所有层面上表现出色,但当前最好的LLM表现不佳。
总的来说,GAIA允许清晰地对有能力的助手进行排名,同时也为未来几个月甚至几年的改进留下了很大的空间。
人类通过网络搜索可能会获得文本结果,从中可以推断出一级难度问题的正确答案,但当涉及到稍微复杂一点的查询时,这种方法就不那么有效了,并且比典型的大型语言模型(LLM)助手稍慢,因为用户需要浏览首批搜索结果。
这证实了LLM助手作为搜索引擎的竞争者的潜力。
GPT-4在没有插件的情况下的结果与其他情况的差异表明,通过工具API或访问网络增强LLM可以提高答案的准确性,并解锁许多新的用例,确认了这一研究方向的巨大潜力。
特别是,GPT-4加上插件表现出了诸如回溯或查询优化等行为,当结果不令人满意时,以及相对较长的计划执行时间。
AutoGPT-4允许GPT-4自动使用工具,但其在二级难度,甚至与不带插件的GPT-4相比,一级难度的结果也令人失望。这种差异可能来自AutoGPT-4依赖GPT-4 API(提示和生成参数)的方式。
与其他LLM相比,AutoGPT-4也较慢。总的来说,人类与带插件的GPT4的合作似乎到目前为止提供了最佳的得分与所需时间比。
下图显示了按能力划分的模型得分。

不出所料,GPT-4无法处理文件和多模态问题,但能够解决注释者使用网络浏览解决的问题,主要是因为它正确地记住了需要结合起来才能得到答案的信息片段。





























