大型语言模型(LLM)已经是许多自然语言处理任务的强大工具,只要能给出正确的提示。然而,由于模型的敏感性,找到最优提示通常需要进行大量手动尝试和试错努力。此外,一旦将初始提示部署到生产环境中,可能会出现意想不到的边缘情况,需要更多轮的手动调整来进一步完善提示。
这些挑战催生了自动提示工程的新兴研究领域。在这一领域内,一个显著的方法涉及利用 LLM 自身的能力。具体来说,这涉及使用指令对 LLM 进行元提示,例如「检查当前提示和一批示例,然后提出一个新的提示」。
虽然这些方法取得了令人印象深刻的性能,但随之而来的问题是:什么样的元提示适用于自动提示工程?
为了回答这个问题,来自南加州大学、微软的研究者将两个关键观察联系起来:(1)提示工程本身就是需要深层推理的复杂语言任务:这涉及密切审查模型的错误、假设当前提示中缺少或误导了什么、如何将任务更清晰的传递给 LLM。(2) 在 LLM 中,通过促使模型「一步一步地思考」可以引发复杂的推理能力,并通过指导它们反思其输出可以进一步提高这种能力。

论文地址:https://arxiv.org/pdf/2311.05661.pdf
通过连接前面的两个观察,研究者进行提示工程,这样做的目的是构建一个元提示,从而指导 LLM 更有效地执行提示工程 (见下图 2)。通过反思现有方法的局限性并融合复杂推理提示的最新进展,他们引入了元提示组件,如逐步推理模板和上下文规范,明确指导 LLM 在提示工程过程中进行推理。
此外,由于提示工程可以看作是一个优化问题,通过从常见的优化概念中汲取灵感,如批处理大小、步长和动量,并将它们的口头表达引入到元提示中。并且两个数学推理数据集,MultiArith 和 GSM8K 上实验了这些组件和变体,并确定了一个表现最佳的组合,将其命名为 PE2。
PE2 取得了强大的实证性能。在使用 TEXT-DAVINCI-003 作为任务模型时,PE2 生成的提示在 MultiArith 上超过 zero-shot 思维链的一步一步进行思考的提示 6.3%,在 GSM8K 上提高了 3.1%。此外,PE2 在性能上优于两个自动提示工程基线,Iterative APE 和 APO (图 1)。
值得注意的是,PE2 在反事实任务上的表现最为有效。此外,该研究还证明了 PE2 在优化冗长、现实世界提示上具有广泛的适用性。

在审查 PE2 的提示编辑历史时,研究者发现 PE2 始终提供有意义的提示编辑。它能够修正错误或不完整的提示,并通过添加额外的细节使提示更加丰富,从而促成最终性能的提升 (表 4 所示)。
有趣的是,当 PE2 不知道在八进制中进行加法运算时,它会从示例中制定自己的算术规则:「如果两个数字都小于 50,则将 2 添加到总和中。如果其中一个数字是 50 或更大,则将 22 添加到总和中。」尽管这是一个不完美的简便解决方案,但它展示了 PE2 在反事实情境中进行推理的非凡能力。
尽管取得了这些成就,研究者也认识到了 PE2 的局限性和失败案例。PE2 也会受到 LLM 固有限制的影响和限制,比如忽视给定的指令和产生错误的合理性 (下表 5 所示)。

背景知识
提示工程
提示工程的目标是在使用给定的 LLM M_task 作为任务模型时(如下公式所示),在给定数据集 D 上找到达到最佳性能的文本提示 p∗。更具体地说,假设所有数据集都可以格式化为文本输入 - 输出对,即 D = {(x, y)}。一个用于优化提示的训练集 D_train,一个用于验证的 D_dev,以及一个用于最终评估的 D_test。按照研究者提出的符号表示,提示工程问题可以描述为:

其中,M_task (x; p) 是在给定提示 p 的条件下模型生成的输出,而 f 是对每个示例的评估函数。例如,如果评估指标是完全匹配,那么
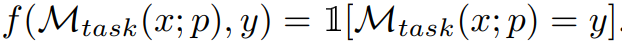
使用 LLM 进行自动提示工程
在给定一组初始提示的情况下,自动提示工程师将不断提出新的、可能更好的提示。在时间戳 t,提示工程师获得一个提示 p^(t),并期望写一个新提示 p^(t+1)。在新的提示生成过程中,可以选择检查一批示例 B = {(x, y, y′ )}。这里 y ′ = M_task (x; p) 表示模型生成的输出,y 表示真实标签。使用 p^meta 表示一个元提示,用于指导 LLM 的 M_proposal 提出新的提示。因此,
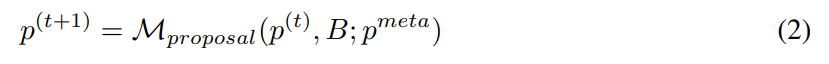
构建一个更好的元提示 p^meta 以提高所提出的提示 p^(t+1) 的质量是本研究的主要关注点。
构建更好的元提示
就像提示在最终任务性能中发挥重要作用一样,引入到公式 2 中的元提示 p^meta 在新提出的提示质量以及自动提示工程的整体质量中起着重要作用。
研究者主要专注于对元提示 p^meta 进行提示工程,开发了可能有助于提高 LLM 提示工程质量的元提示组件,并对这些组件进行系统的消融研究。
研究者基于以下两个动机来设计这些组件的基础:(1)提供详细的指导和背景信息:(2)融入常见的优化器概念。接下来,研究者将更详细地描述这些元素并解释相关原理。下图 2 为可视化展示。

提供详细的指令和上下文。在先前的研究中,元提示要么指示提议模型生成提示的释义,要么包含有关检查一批示例的最小指令。因此通过为元提示添加额外的指令和上下文可能是有益的。
(a) 提示工程教程。为了帮助 LLM 更好地理解提示工程的任务,研究者在元提示中提供一个提示工程的在线教程。
(b) 两步任务描述。提示工程任务可以分解为两个步骤,像 Pryzant et al. 所做的那样:在第一步,模型应该检查当前的提示和一批示例。在第二步,模型应该构建一个改进的提示。然而,在 Pryzant et al. 的方法中,每一步都是即时解释的。与之相反的是,研究者考虑的是在元提示中澄清这两个步骤,并提前传递期望。
(c) 逐步推理模板。为了鼓励模型仔细检查批次 B 中的每个示例并反思当前提示的局限性,研究者引导提示提议模型 M_proposal 回答一系列问题。例如:输出是否正确?提示是否正确描述了任务?是否有必要编辑提示?
(d) 上下文规范。在实践中,提示插入整个输入序列的位置是灵活的。它可以在输入文本之前描述任务,例如「将英语翻译成法语」。它也可以出现在输入文本之后,例如「一步一步地思考」,以引发推理能力。为了认识到这些不同的上下文,研究者明确指定了提示与输入之间的相互作用。例如:「Q: <input> A :一步一步地思考。」
融入常见的优化器概念。在前面方程 1 中描述的提示工程问题本质上是一个优化问题,而方程 2 中的提示提议可以被视为进行一次优化步骤。因此,研究者考虑以下在基于梯度的优化中常用的概念,并开发他们元提示中使用的对应词。
(e) 批处理大小。批处理大小是在每个提示提议步骤 (方程 2) 中使用的 (失败) 示例数量。作者在分析中尝试了批处理大小为 {1, 2, 4, 8}。
(f) 步长。在基于梯度的优化中,步长确定模型权重更新的幅度。在提示工程中,其对应物可能是可以修改的单词(token)数量。作者直接指定「你可以更改原始提示中的最多 s 个单词」,其中 s ∈ {5, 10, 15, None}。
(g) 优化历史和动量。动量 (Qian, 1999) 是一种通过保持过去梯度的移动平均来加速优化并避免振荡的技术。为了开发动量的语言对应部分,本文包含了所有过去的提示(时间戳为 0, 1, ..., t − 1)、它们在 dev 集上的表现以及提示编辑的摘要。
实验
作者使用以下四组任务来评估 PE2 的有效性和局限性:
1. 数学推理;2. 指令归纳;3. 反事实评估;4. 生产提示。
改进的基准与更新的 LLMs。在表 2 的前两部分中,作者观察到使用 TEXT-DAVINCI-003 可以显著提高性能,表明它更能够在 Zero-shot CoT 中解决数学推理问题。此外,两个提示之间的差距缩小了(MultiArith:3.3% → 1.0%,GSM8K:2.3% → 0.6%),表明 TEXT-DAVINCI-003 对提示释义的敏感性减小。鉴于此,依赖简单释义的方法如 Iterative APE,可能无法有效地提升最终结果。更精确和有针对性的提示编辑是提高性能的必要条件。

PE2 在各种任务上优于 Iterative APE 和 APO。PE2 能够找到一个在 MultiArith 上达到 92.3% 准确率(比 Zero-shot CoT 高 6.3%)和在 GSM8K 上达到 64.0% 的提示 (+3.1%)。此外,PE2 找到的提示在指令归纳基准、反事实评估和生产提示上优于 Iterative APE 和 APO。
在前面图 1 中,作者总结了 PE2 在指令归纳基准、反事实评估和生产提示上获得的性能提升,展示了 PE2 在各种语言任务上取得了强大的性能。值得注意的是,当使用归纳初始化时,PE2 在 12 个反事实任务中的 11 个上优于 APO (图 6 所示),证明了 PE2 能够推理矛盾和反事实情境。

PE2 生成有针对性的提示编辑和高质量提示。在图 4 (a) 中,作者绘制了提示优化过程中提示提议的质量。实验中观察到三种提示优化方法有非常明显的模式:Iterative APE 基于释义,因此新生成的提示具有较小的方差。APO 进行了大幅度的提示编辑,因此性能在第一步下降。PE2 在这三种方法中是最稳定的。在表 3 中,作者列出了这些方法找到的最佳提示。APO 和 PE2 都能够提供「考虑所有部分 / 细节」的指令。此外,PE2 被设计为仔细检查批次,使其能够超越简单的释义编辑,进行非常具体的提示编辑,例如「记得根据需要添加或减去」。

了解更多内容,请参考原论文。