














1、prometheus架构
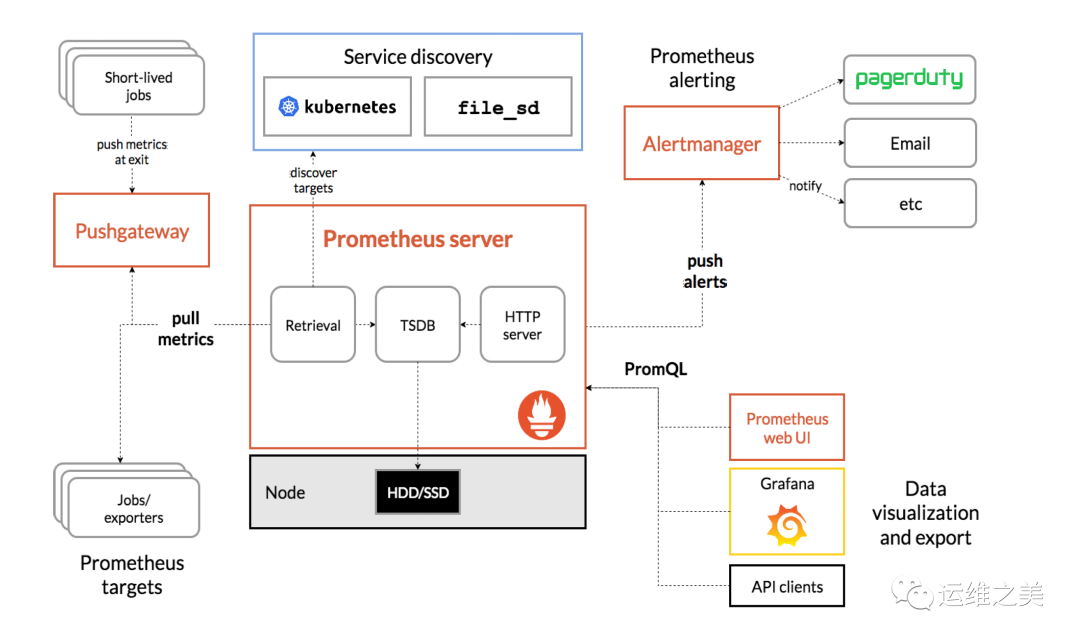
组件介绍
- Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
PushGateway:短期存储指标数据。主要用于临时性的任务 - Exporters:是提供监控数据的来源,采集已有的第三方服务监控指标并暴露metrics,常见的监控主机安装node-exporter,数据库mysql-exporter,按需安装,对于Exporter,Prometheus Server采用pull的方式来采集数据
- Alertmanager:告警触发并通过短信,邮件等将告警发送出来
- Web UI:简单的Web控制台,可以通过安装grafana,并配置prometheus数据源来做监控大盘
前置准备工作,提前部署好Prometheus,grafana,node-exporter,此处不做详细讲解
### 部署 Prometheus
docker run -d --name=prometheus -p 9090:9090 prom/prometheus
#可以将配置文件
访问地址:http://IP:9090
### 部署 Grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana
访问地址:http://IP:3000
### 部署node-exporter ###
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
tar xvfz node_exporter-*.*-amd64.tar.gz
cd node_exporter-*.*-amd64
./node_exporter2、前置准备工作
环境:prometheus服务端和alertmanager部署在同一台机器上,实验前提是prometheus服务端已经安装好
操作系统:Centos7.4
prometheus的告警管理分为两部分。通过在prometheus服务端设置告警规则, Prometheus服务器端通过拉取exporter的数据指标,当指标满足告警阈值后,通过Alertmanager管理这些告警,包括静默,抑制,聚合以及通过电子邮件,企业微信,钉钉等方法发送告警通知。
设置警报和通知的主要步骤如下:
- 部署prometheus,一台机器【本文略】
- node-exporter,所有要监控节点都要部署,类似于agent【本文略】
- 安装启动Alertmanager,和prometheus同节点
- 配置Prometheus对Alertmanager访问,配置告警规则;
- 配置企微后台,alertmanager配置对接企微并配置告警模板;
- 修改阈值触发告警
前置工作,也可以采用离线包方式部署
### 部署 Prometheus
#创建prometheus的docker-compose.yml的配置
services:
prometheus:
command:
- --web.listen-address=0.0.0.0:9090
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/var/lib/prometheus
- --storage.tsdb.retention.time=30d
- --web.enable-lifecycle
- --web.external-url=prometheus
- --web.enable-admin-api
container_name: prometheus
deploy:
resources:
limits:
cpus: '2'
memory: 8g
hostname: prometheus
image: prom/prometheus
labels:
- docker-compose-reset=true
- midware-group=monitor
network_mode: host
restart: always
volumes:
- /usr/share/zoneinfo/Hongkong:/etc/localtime
- /data/prometheus/data:/var/lib/prometheus
- /data/prometheus/config:/etc/prometheus
working_dir: /var/lib/prometheus
version: '3'
#执行docker-compose up -d启动prometheus服务
### 部署 Grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana
访问地址:http://IP:3000
### 部署node-exporter ###
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
tar xvfz node_exporter-*.*-amd64.tar.gz
cd node_exporter-*.*-amd64
./node_exporter3、安装AlertManager
以官网最新版本为例,可以从官网地址下载alertmanager安装包https://prometheus.io/download/
将包上传到服务器上,按照下面步骤安装和启动alertmanager服务
[root@localhost ~]# mkdir -p /data/alertmanager
[root@localhost~]# tar -xvf alertmanager-0.22.2.linux-amd64.tar.gz -C /data/alertmanager
[root@localhost~]# cd /data/alertmanager/
[root@localhost alertmanager]# nohup ./alertmanager &4、配置prometheus告警规则
prometheus中添加配置监控alertmanager服务器
prometheus.yml添加如下配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.61.123:9093
rule_files:
- "rules/*_rules.yml"
- "rules/*_alerts.yml"
scrape_configs:
- job_name: 'alertmanager' #配置alertmanager,等alertmanager部署后配置
static_configs:
- targets: ['localhost:9093']
- job_name: 'node_exporter' #配置node-exporter
static_configs:
- targets: ['192.168.61.123:9100']rule_files为告警触发的规则文件
prometheus当前路径下新建rules目录,创建如下配置文件,分别配置节点告警和pod容器告警
[root@prometheus prometheus]# cd rules/
[root@prometheus rules]# ls
node_alerts.yml pod_rules.yml- Node节点告警
node_alerts.yml #监控主机级别告警
[root@localhost rules]# cat node_alerts.yml
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up {job="kubernetes-nodes"} == 0
for: 15s
labels:
status: 非常严重
annotations:
summary: "{{.instance}}:服务器宕机"
description: "{{.instance}}:服务器延时超过15s"
- alert: CPU使用情况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.instance}}: High CPU Usage Detected"
description: "{{$labels.instance}}: CPU usage is {{$value}}, above 60%"
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"
description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})"
- alert: 内存使用
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{ $labels.instance}} 内存使用率过高!"
description: "{{ $labels.instance }} 内存使用大于80%(目前使用:{{ $value}}%)"
- alert: IO性能
expr: (avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) > 60
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高!"
description: "{{ $labels.instance }} 流入磁盘IO大于60%(目前使用:{{ $value }})"- pod告警配置
pod_rules.yml文件配置 #pod级别告警
[root@localhost rules]# cat pod_rules.yml
groups:
- name: k8s_pod.rules
rules:
- alert: pod-status
expr: kube_pod_container_status_running != 1
for: 5s
labels:
severity: warning
annotations:
description : pod-{{ $labels.pod }}故障
summary: pod重启告警
- alert: Pod_all_cpu_usage
expr: (sum by(name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 10
for: 5m
labels:
severity: critical
service: pods
annotations:
description: 容器 {{ $labels.name }} CPU 资源利用率大于 75% , (current value is {{ $value }})
summary: Dev CPU 负载告警
- alert: Pod_all_memory_usage
expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 1024*10^3*2
for: 10m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} Memory 资源利用率大于 2G , (current value is {{ $value }})
summary: Dev Memory 负载告警
- alert: Pod_all_network_receive_usage
expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 1024*1024*50
for: 10m
labels:
severity: critical
annotations:
description: 容器 {{ $labels.name }} network_receive 资源利用率大于 50M , (current value is {{ $value }})
summary: network_receive 负载告警更多告警规则【科学上网】
https://samber.github.io/awesome-prometheus-alerts/rules
for子句:Prometheus将expr中的规则作为触发条件, 在这种情况下,Prometheus将在每次检查警报是否继续处于活动状态,然后再触发警报。处于活动状态但尚未触发的元素处于pending状态,for中定义时间即为达到活动状态持续时间才触发告警
配置加之后热重启prometheus服务
curl -XPOST http://localhost:9090/-/reload注:prometheus启动命令添加参数--web.enable-lifecycle可实现支持热重启
$ ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 0 rule files found上面命令可以检查配置文件修改是否正确
登录prometheus targets界面已经出现alertmanager的监控对象
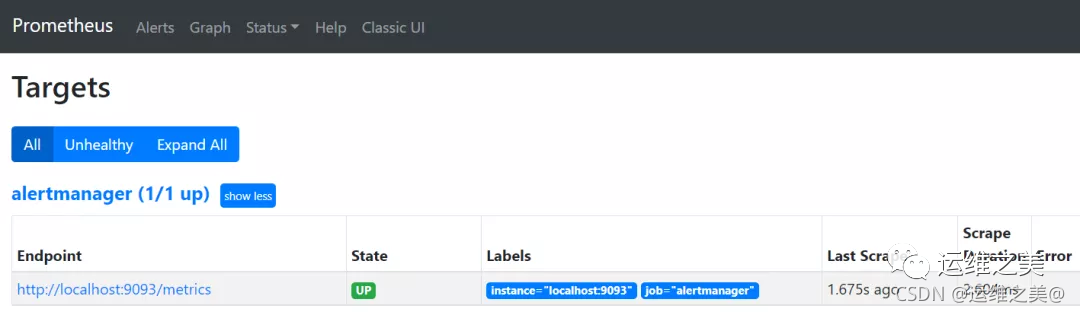
检查prometheus告警规则配置是否生效
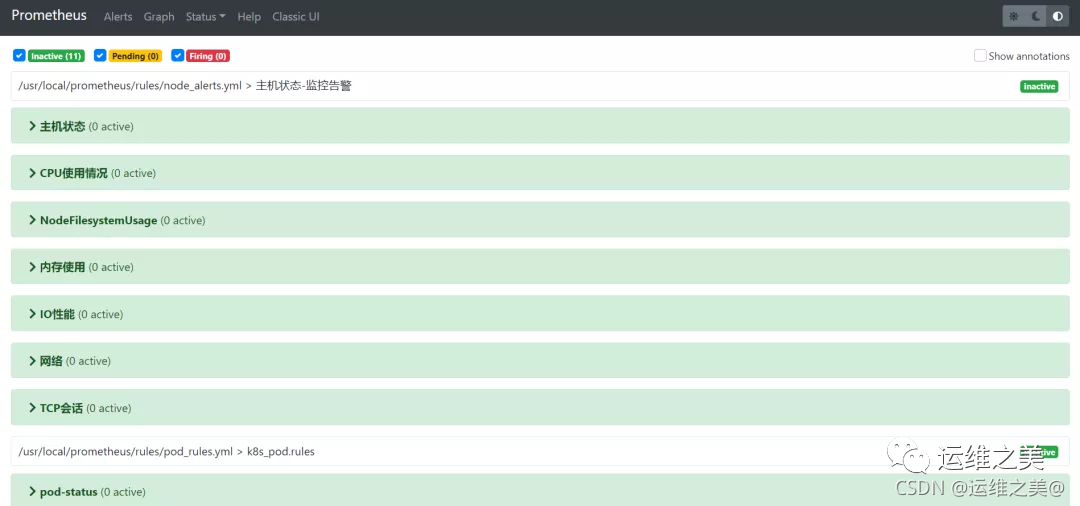
可以看到node和pod的监控指标都已经加载,Perfect,离成功更近一步
5、配置AlertManager告警发送
实现企业微信告警通知,需要首先在企业后台创建应用,起名叫prometheus
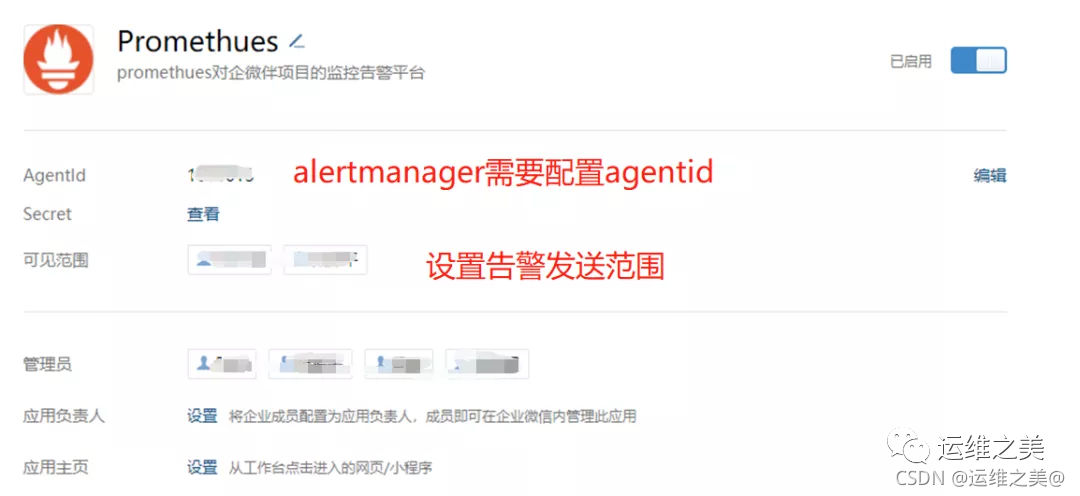
记录企业ID,secret,agentid信息,后边配置文件中需要。
[root@localhost alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 1m # 每1分钟检测一次是否恢复
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_corp_id: 'xxxxxxxxx' # 企业微信中企业ID
wechat_api_secret: 'xxxxxxxx'
templates:
- '/data/alertmanager/template/*.tmpl'
route:
receiver: 'wechat'
group_by: ['env','instance','type','group','job','alertname']
group_wait: 10s
group_interval: 5s
repeat_interval: 1h
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '57'
agent_id: 'xxxx' #企微后台查询的agentid
to_user : "@all"
api_secret: 'xxxxxxx' #后台查询的secret说明
- wechat_api_url配置为企业微信的接口地址,因此需要alertmanager所在服务器能够连接公网
- to_user需要配置,all是发送所有可见范围用户,无此标签告警无法发出,本人亲测,企微后台可见范围可以添加接收告警的用户
- 字段解释
- global:全局配置
- resolve_timeout:告警恢复超时时间,当接收的告警没有EndsAt字段时,经过该时间就将该告警标志为已解决,prometheus上用不上,告警都会带EndsAt字段
- route:告警分配配置
- group_by:设置分组标签,告警时出现的labels都可用于分组,如果需要对所有不同label都分组,可以使用’…’
- group_wait:告警发送等待时间,时间拉长便于告警聚合
- group_interval:前后两组告警发送间隔时间
- repeat_interval:重复告警发送间隔时间
- receiver:定义接收告警的对象
- receivers:告警接收对象,这部分信息参考步骤1获取
- name:告警接收名称,与route中的receiver一一对应,这里我们配置的是企业微信
- corp_id: 企业微信唯一ID,我的企业 -> 企业信息
- to_party: 告警需要发送的组
- agent_id: 自己创建应用的ID,自己创建的应用详情页面查看
- api_secret: 自己创建应用的密钥,自己创建的应用详情页面查看
- send_resolved: 告警解决是否发送通知
- inhibit_rules:告警抑制规则
当新的告警匹配到target_match规则,而已发送告警满足source_match规则,并且新告警与已发送告警中equal定义的标签完全相同,则抑制这个新的告警。
上述配置的结果就是同个instance的同个alertname告警,major会抑制warning告警,这很好理解,比如阈值告警,达到critical肯定也达到了warning,没必要发送两个告警。
不过,从实际测试结果看,这个抑制规则只能在触发告警时使用,对于告警恢复没有,应该是个bug,也有可能我用的版本过低,有时间再去看下源码,查一查
templates:告警消息模板
企业微信告警发送模板,当前路径新建template目录
[root@localhost alertmanager]# cat template/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
=========xxx环境监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }} {{ $alert.Labels.pod }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
=========xxx环境异常恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}配置修改后,执行命令进行热重启
curl -XPOST http://localhost:9093/-/reload配置完成,我们可以调整告警阈值进行测试
修改/usr/local/prometheus/rules/node_alerts.yml中磁盘告警阈值
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 10修改为>10就告警,登录管理界面发现马上就收到告警了
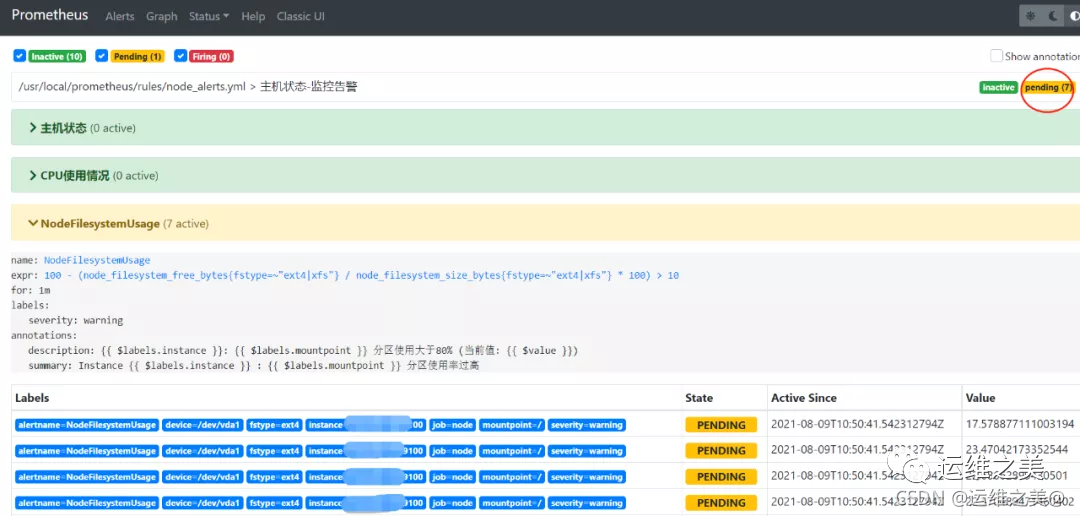
这里说明一下 Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing。
- Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。
- Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。
- Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到 Inactive,如此循环。
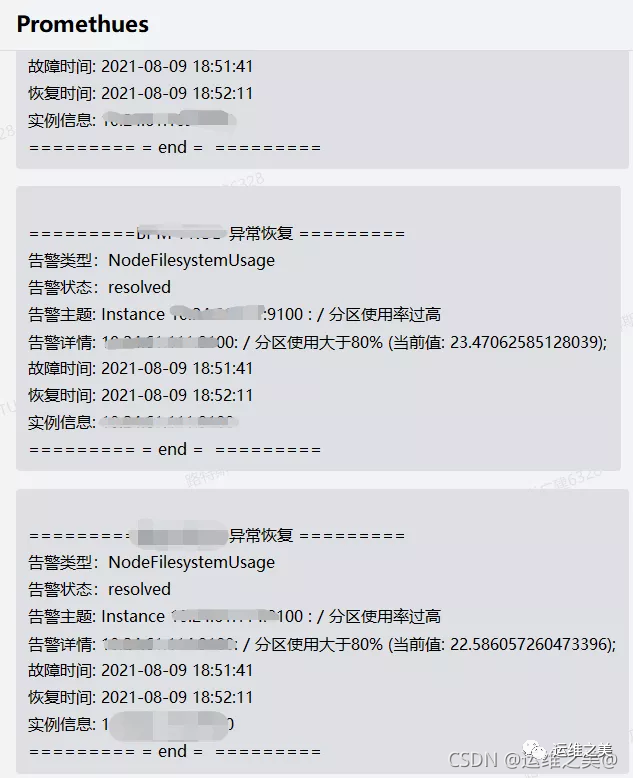
大功告成,此处该有掌声!


















