大模型的出现引发了智能体设计的革命性变革,在 ChatGPT 及其插件系统问世后,对大模型智能体的设计和开发吸引了极大的关注。帮助完成预订、下单等任务,协助编写文案,自主从网络上搜索最新的知识与新闻等等,这种通用、强大的智能助理,让大模型强大的语义理解、推理能力将之变成了可能。

为了提升大模型智能体交互的性能和可靠性,目前学界已经提出了多种基于不同提示语技术的智能体框架,如将思维链结合至决策过程的 ReAct、利用大模型的自检查能力的 RCI 等。
尽管大模型智能体已经表现出强大的能力,但上述方案都缺乏让大模型智能体从自身的既往交互经历中学习进化的能力。而这种持续进化的能力,正成为大模型智能体发展中亟待解决的问题。
一般来说,决策交互任务中通常会采用强化学习,基于过往交互历程来优化智能体的交互策略,但对于大模型来说,直接优化其参数的代价巨大。
Algorithm Distillation(算法蒸馏)等工作提出了 「即境强化学习」(in-context reinforcement learning)的概念,将强化学习训练过程输入预训练过的决策 transformer,就可以让模型在不需要更新参数的情况下,从输入的训练历程中学习到性能演进的模式,并优化下一步输出的策略。
然而这种模式却难以直接应用于文本大模型。因为复杂的观测、动作表示成文本需要消耗更多的词元(token),这将导致完整的训练历程难以塞入有限的上下文。
针对该问题,上海交通大学跨媒体语言智能实验室(X-LANCE)提出了一种解决方案:通过外置经验记忆来保存大模型的交互历史,凭借强化学习来更新经验记忆中的经历,就可以让整个智能体系统的交互性能得到进化。这样设计出来的智能体构成了一种半参数化的强化学习系统。论文已由 NeurIPS 2023 接收。

论文地址:https://arxiv.org/abs/2306.07929
实验显示,通过该方法设计的 「忆者」(Rememberer)智能体,在有效性与稳定性上均展现出了优势,超越了此前的研究成果,建立了新的性能基准。
方法

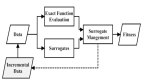
「忆者」智能体的技术架构
该工作为 「忆者」 智能体设计了一种 RLEM(Reinforcement Learning with Experience Memory)框架,使得智能体能够在交互中,根据当前交互状态从经验记忆中动态抽取过往经验来提升自身的交互行为,同时还可以利用环境返回的回报(reward)来更新经验记忆,使得整体策略得到持久改进。
在经验记忆中存储任务目标 、观测
、观测 、候选动作
、候选动作 以及对应的累积回报(Q 值)
以及对应的累积回报(Q 值) 。训练中,可以采用多步 Q 学习来更新记忆池中记录的 Q 值
。训练中,可以采用多步 Q 学习来更新记忆池中记录的 Q 值  :
:


在推断过程中,智能体依据任务相似度与观测相似度,从经验记忆中提取最相似的 k 条经历,来构成即境学习(in-context learning)的范例。
由于训练过程中得到的经历有成功的也有失败的,不同于此前基于经验记忆的方法只利用成功的经历,该工作提出了一种特别的输出格式来将失败经历也加以利用。
这种输出格式称为 「动作建议」(action advice),即要求模型输出时同时输出推荐的(encouraged)与不推荐的(discouraged)动作及其 Q 值估计,从而促使模型能够学习到范例中部分动作的失败,并在新的决策中避免。
结果
该工作在 WebShop 与 WikiHow 两个任务集上测试了所提出的 「忆者」智能体。


测试了采用不同初始经历、不同训练集构建的 「忆者」智能体,相比于 ReAct 及采用静态范例的基线,「忆者」不仅取得了更高的平均性能,而且性能对各种不同的初始化条件更加稳定,展现了巨大的优势。
同时还采用人类标注的经验记忆(Rememberer (A))做了实验,证明了所设计的相似度函数提取出的动态范例的有效,同时也证明,强化学习训练相比人类标注的经验记忆能够取得更好的性能。

消融实验的结果也证实了所采用的多步 Q 学习以及 「动作建议」输出格式的作用。

这一结果也证明,训练过程中,通过更新经验记忆,「忆者」智能体的交互性能确实在逐步进化,进一步说明了所设计方法的有效。
结论
针对大模型智能体难以利用自身交互经历进化自身交互性能的问题,上海交通大学跨媒体语言智能实验室(X-LANCE)提出了 RLEM 框架,设计了「忆者」智能体。实验结果显示,通过增强以外置经验记忆,并辅以强化学习对经验记忆更新,「忆者」智能体能够充分利用自身的交互经历进化交互策略,显著提升在基准任务集上的性能。
该工作为大模型智能体进化自身性能,以及将大模型智能体与强化学习结合,提供了富有价值的方案和见解,未来或有机会在此方向上探索得更深更远。