大家好,今天跟大家分享一个实战的教程。
老规矩,先看效果(明确一下目标):

随着人脸识别技术的发展,给我们的日常生活带来了许多的便利,但是同样的也存在隐私的问题。以及可能被不法分子用于做一些违法事情。
所以很多视频博主,都会给路人打码。但是手动打码是一件非常繁琐的事情,对于单帧图片还算简单,但是假设视频的帧率是 25FPS,即一秒中有25帧图片,那么一个几分钟的视频,其工作量也非常的可怕。
因此我们尝试使用程序自动去执行这样子的操作!
我们可以使用Opencv、Mediapipe和Python,实现实时模糊人脸。
我们可以分两步完成:
- 在打码之前,首先确定人脸位置
- 取出脸,模糊它,然后将处理后的人脸放回到视频帧中(视频处理类似)
(留个作业:如何实现对除了本人以外的其他人打码?)
1、在打码之前,首先确定人脸位置
老规矩,首先配置一下环境,安装必要的库(OpenCV 和 MediaPipe)
在 MediaPipe 库中提供了人脸关键点检测的模块。
详细的内容可以参考:https://google.github.io/mediapipe/solutions/face_mesh.html
当然在该项目的代码中,也提供人脸关键点检测的代码。
“facial_landmarks.py”的文件:
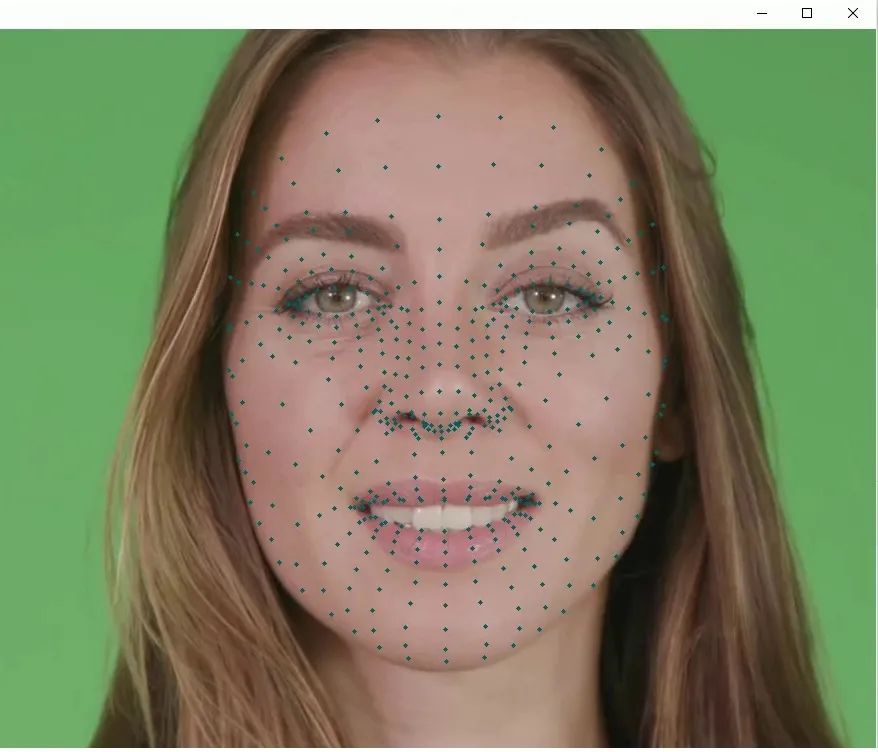
人脸关键点检测效果图
下面我们就一起来写一下这部分的代码:
- 首先导入必要的库以及用于人脸关键点检测的模块:
- 然后使用检测出来的人脸关键点最外围的一圈关键点绘制一个多边形(脸部轮廓)。这里使用opencv 中的convxhull() 函数可以实现:
绘制完成后的结果如下所示:

之后使用上面所提取到的人脸关键点坐标创建mask,用提取我们在视频帧中感兴趣的区域:
结果如下所示:

得到这个mask,我们就可以进一步对人脸进行模糊(打码)处理。
打码的操作,这里使用的是OpenCV 中的cv2.blur() 函数:
结果:
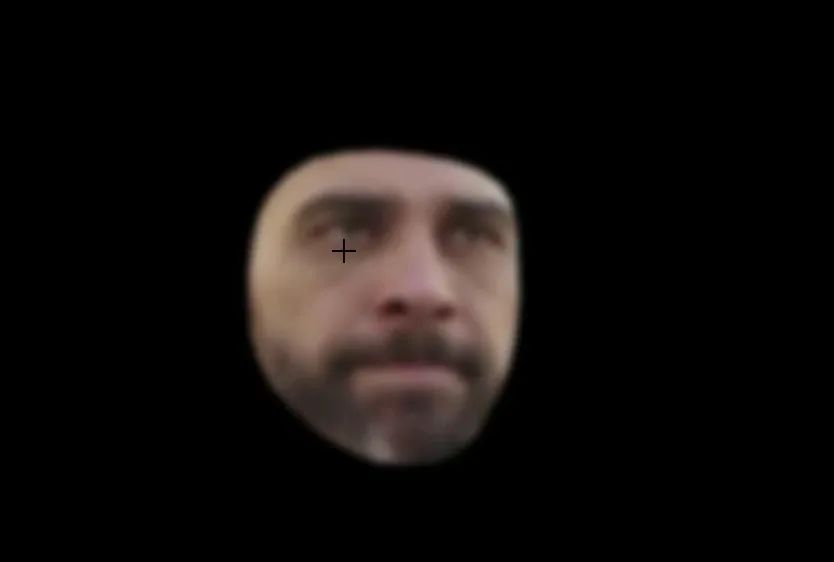
目前,我们已经实现对人脸进行打码操作,剩下的就是对人脸以外的区域进行提取,并合并成最终的结果即可!
对人脸以外的区域进行提取(背景),实际上对上面的mask 进行取反即可。
背景提取:
从图像的细节可以看出,背景是完全可见的,但面部区域已经变成黑色了。这是我们将在下一步中应用模糊人脸的空白区域。

最后一步,将上面两步获取的人脸mask 和背景进行相加即可,这里使用cv2.add() 即可实现我们的目标:
结果:

这是对一帧图片进行处理。
2、取出脸,模糊它,然后将处理后的人脸放回到视频帧中
上面的操作都是在单帧图片上进行处理的,如果我们需要出来的是视频的话,其实原理是完全一样的,只不过是将一个视频拆成一系列的图片即可。
稍微做一些修改:
(1)输入文件 (图片 ---> 视频)
(2)对输入的视频帧,做一个循环遍历: