













一、推荐系统简介
在互联网时代,推荐系统随处可见,比如:我昨天晚上还在“某东”看一个运动鞋,今天早上“某条”上的广告就给我推荐运动鞋相关的广告。在看这个这篇公众号博文的你,是否已经注意到上面的广告是否是你曾经关注的?
推荐系统一直以来都是一个热门技术领域,也是机器学习技术在商业中最成功和最广泛的应用之一。它是根据用户的历史行为、社交关系、兴趣点等信息去判断用户当前需要或感兴趣的产品或者服务的一类应用。推荐系统本身是一种信息过滤的方法,与搜索和栏目导航组成三大主流的信息过滤方法。
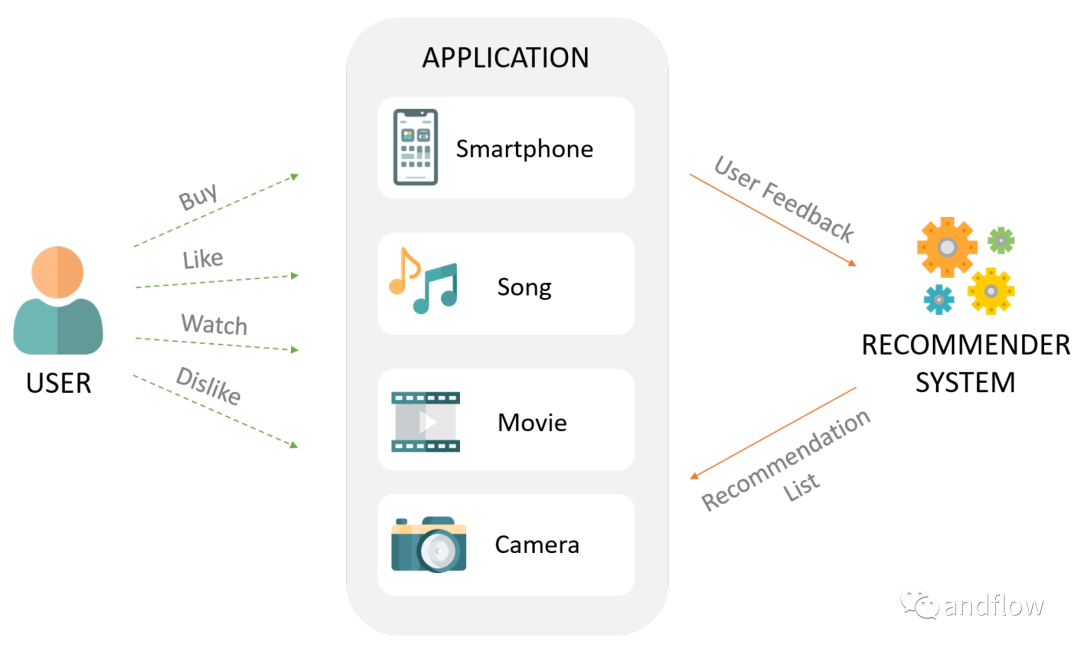
推荐系统对用户而言,能帮助他们找到喜欢的产品、服务,帮助用户做出选择;对服务提供方而言,可以给用户提供个性化的服务,提高用户信任度和粘性,增加营收。
二、什么是推荐引擎?
推荐系统的核心是推荐引擎,推荐引擎根据特定客户之前的购买历史过滤出他或她感兴趣或会购买的产品。关于客户的可用数据越多,建议就越准确。但如果客户是新客户,这种方法将失败,因为我们没有该客户以前的数据。因此,为了解决这个问题,就需改变策略,通常推荐最受欢迎的产品给客户不一定准确,因为对所有新客户推荐内容都是一样的。因此,一些APP会询问新客户的兴趣,以便他们可以更准确地推荐。
针对不同的客户或者产品,推荐引擎的过滤方式可以包括:基于内容的过滤、协同过滤、混合过滤等。
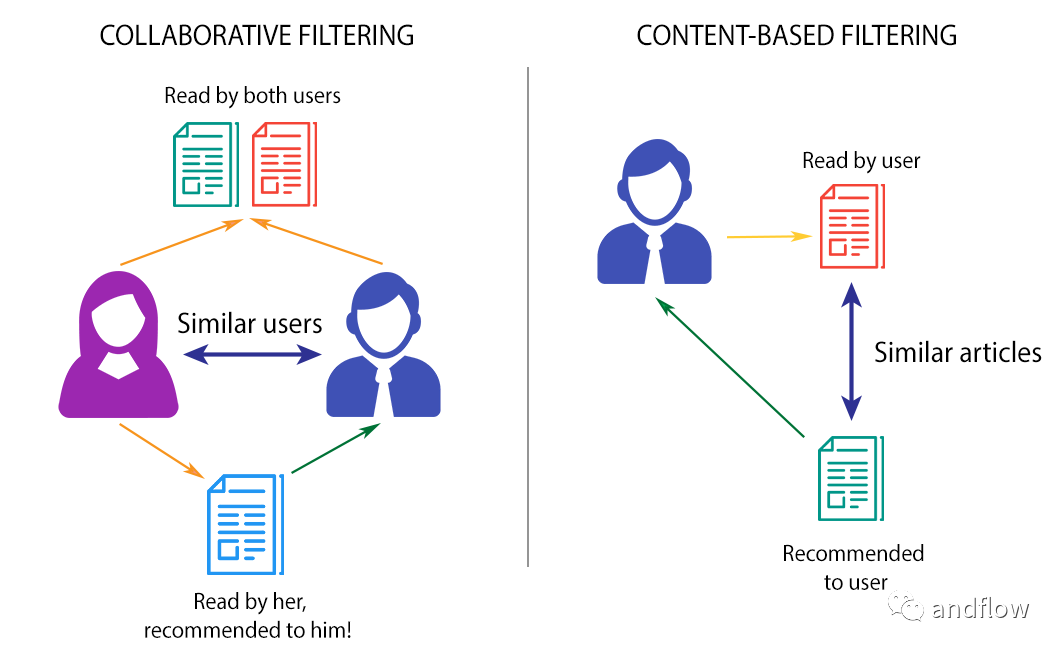
1.基于内容的过滤
基于内容的过滤根据产品提供的描述或某些数据来查找产品之间的相似性。根据用户的先前历史,找到用户可能喜欢的类似产品。例如:如果用户喜欢“谍中谍”之类的电影,那么我们可以向他推荐“汤姆克鲁斯”的电影。
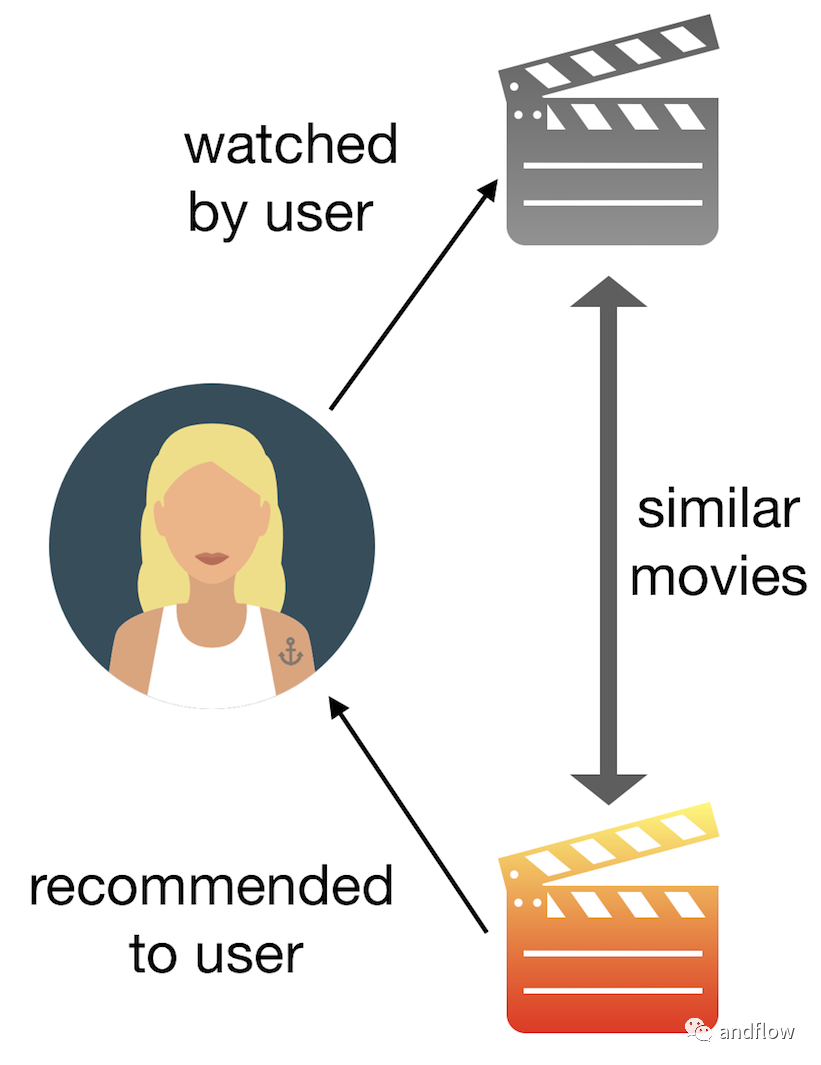
这种过滤方式使用两种类型的数据。第一,用户相关的信息——用户向量,包括用户的喜好、用户的兴趣、用户的个人信息(如年龄)、用户的历史等。第二,与产品相关的信息——项目向量,项目向量包含所有项目的特征,基于这些特征可以计算它们之间的相似性。
可以使用余弦相似度计算。如果“A”是用户向量,“B”是项目向量,则余弦相似度采用以下公式计算:
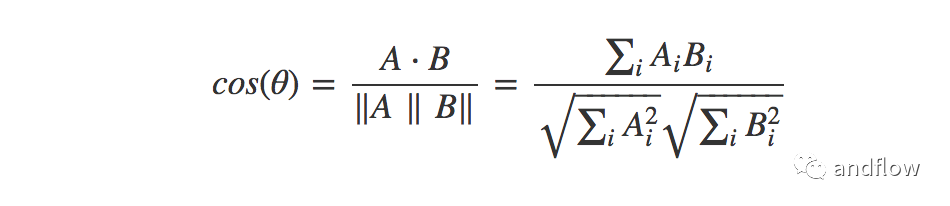
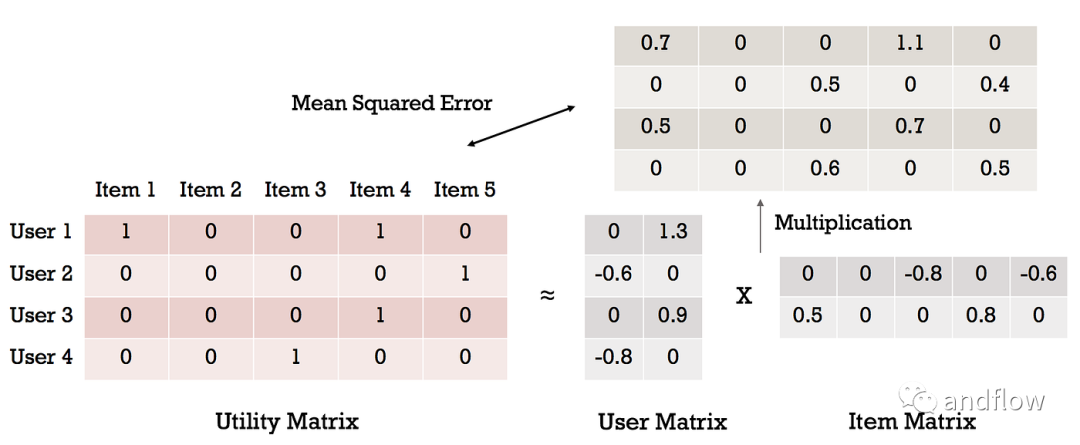
最后将余弦相似度矩阵中计算的值按降序排序,并推荐给该用户排在前面的一个或几个项目。
基于内容的过滤的优势是:
- 用户会被推荐他们喜欢的物品类型;
- 用户对推荐的类型感到满意;
- 只需要拥有新项目数据,就可以推荐新项目;
缺点是:
- 用户永远不会被推荐不同的项目;
- 由于用户不尝试不同类型的产品,业务无法扩展;
- 如果用户矩阵或项目矩阵发生变化,则需要重新计算余弦相似度矩阵;
2.协同过滤
协同过滤是根据用户的行为来执行的。用户的历史行为信息扮演着重要的角色。例如,如果用户“A”喜欢“Coldplay”、“The Linkin Park”和“Britney Spears”,而用户“B”喜欢“Coldplay”、“The Linkin Park”和“Taylor Swift”,则他们具有相似的兴趣。因此,存在用户“A”喜欢“Taylor Swift”并且用户“B”喜欢“Britney Spears”的巨大概率。这就是协同过滤的方式。
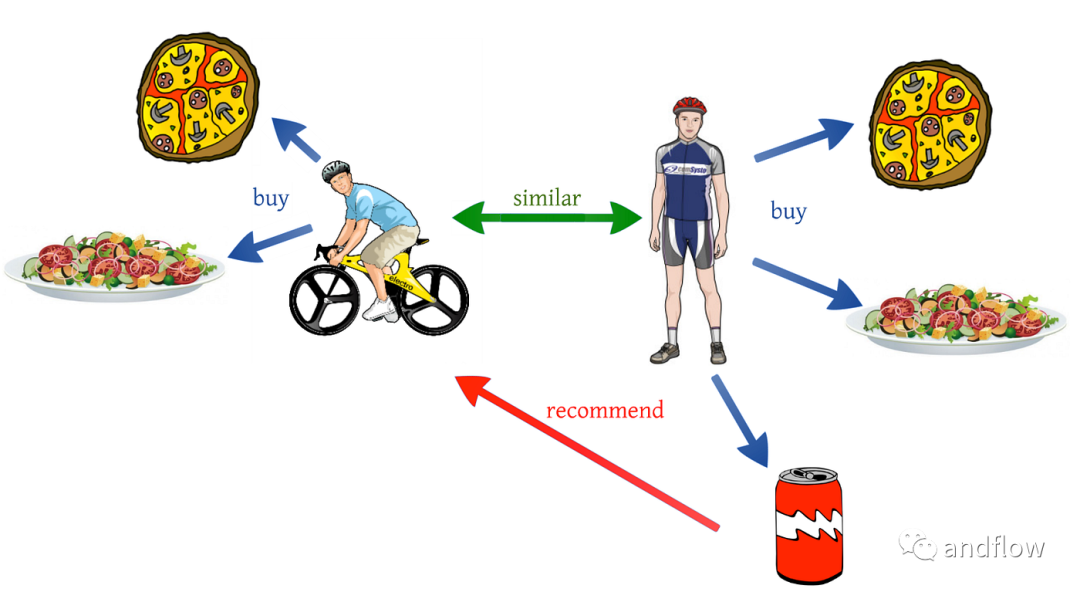
协同过滤技术包括:用户-用户协同过滤、项目-项目协同过滤。
(1) 用户-用户协同过滤
用户向量包括用户购买的所有物品以及针对每个特定产品给出的评价。使用n*n矩阵计算用户之间的相似性,其中n是存在的用户的数量。相似度使用相同的余弦相似度公式计算。现在,计算推荐矩阵。在这种情况下,评级乘以购买该项目的用户与必须向其推荐项目的用户之间的相似性。为该用户的所有新项目计算这个值,并按降序排序。然后,将最重要的项目推荐给该用户。
如果有新用户到来,或者老用户改变了他对项目的评价,则推荐项目就可能改变。

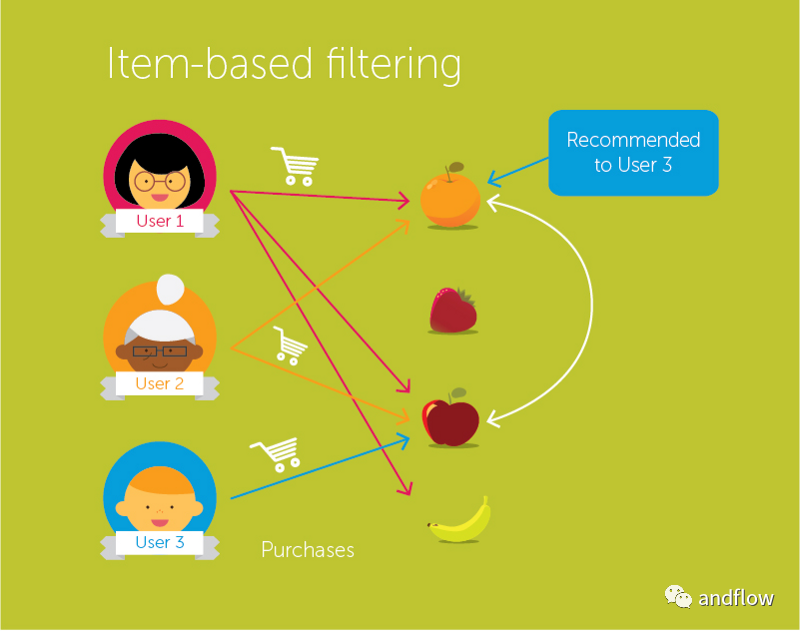
(2) 项目-项目协同过滤
在这种方式下,考虑的不是类似的用户,而是类似的项目。如果用户“A”喜欢“盗梦空间”,他可能会喜欢“火星人”,因为“盗梦空间”和“火星人”的某些方面是类似的。推荐矩阵是m*m矩阵,其中m是存在的项目的数量。
协同过滤算法的优势是:
- 可以向用户推荐新产品;
- 可以推广新产品,扩大业务;
缺点是:
- 需要用户以前的历史记录或产品数据;
- 如果没有用户购买或评价,则无法推荐新项目;
3.混合推荐算法
基于内容的推荐或者协同过滤算法各有优缺点。为了更准确地推荐产品,还可以使用混合推荐算法,即同时使用基于内容和协同过滤推荐产品。混合推荐算法具有更高的效率和更好的实用性。
三、10个最佳开源推荐系统相关资源
为了进一步理解推荐系统,以下收集了一些用于学习或者开发的最佳开源项目,包括:学习资源、开发包、完整的推荐系统等。
1.d2l-zh或d2l-en
GitHub(K):
- 中文:https://github.com/d2l-ai/d2l-zh
- 英文:https://github.com/d2l-ai/d2l-en
语言:Python
这个库包含各种交互式深度学习书籍,多种框架代码,数学和讨论,其中也包含推荐系统算法。这个库已经被斯坦福大学、麻省理工学院、哈佛和剑桥在内的70个国家的500所大学采用。绝对是学习人工智能技术的好资源。
这个库的目的是:
- 所有人均可在网上免费获取;
- 提供足够的技术深度,从而帮助读者实际成为深度学习应用科学家:既理解数学原理,又能够实现并不断改进方法;
- 包含可运行的代码,为读者展示如何在实际中解决问题。这样不仅直接将数学公式对应成实际代码,而且可以修改代码、观察结果并及时获取经验;
- 允许我们和整个社区不断快速迭代内容,从而紧跟仍在高速发展的深度学习领域;
- 由包含有关技术细节问答的论坛作为补充,使大家可以相互答疑并交换经验。
2.Recommenders
GitHub(16.7K):https://github.com/recommenders-team/recommenders
语言:Python

该库包含构建推荐系统的各种示例和最佳实践,以Jupyter notebooks的形式提供。
下图描述了这个最佳实践示例是如何在推荐系统开发工作流程中帮助研究人员/开发人员的。
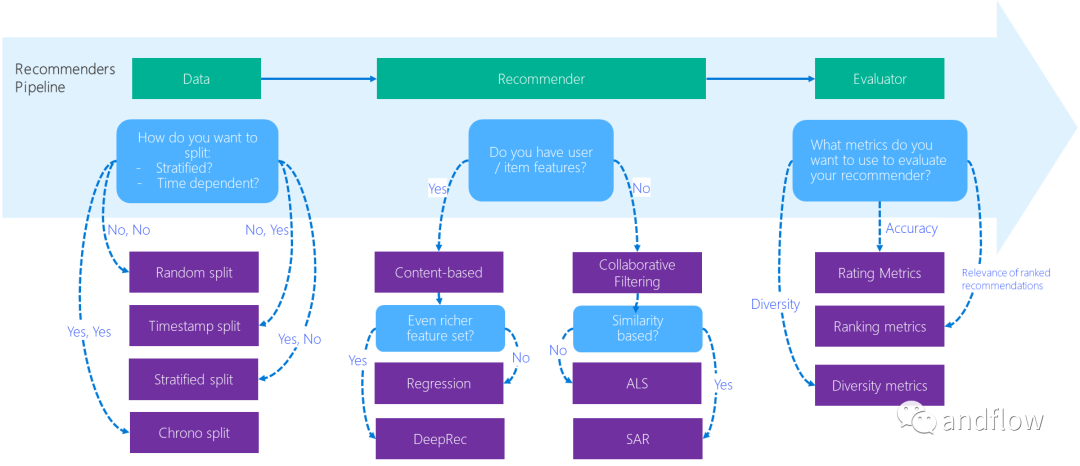
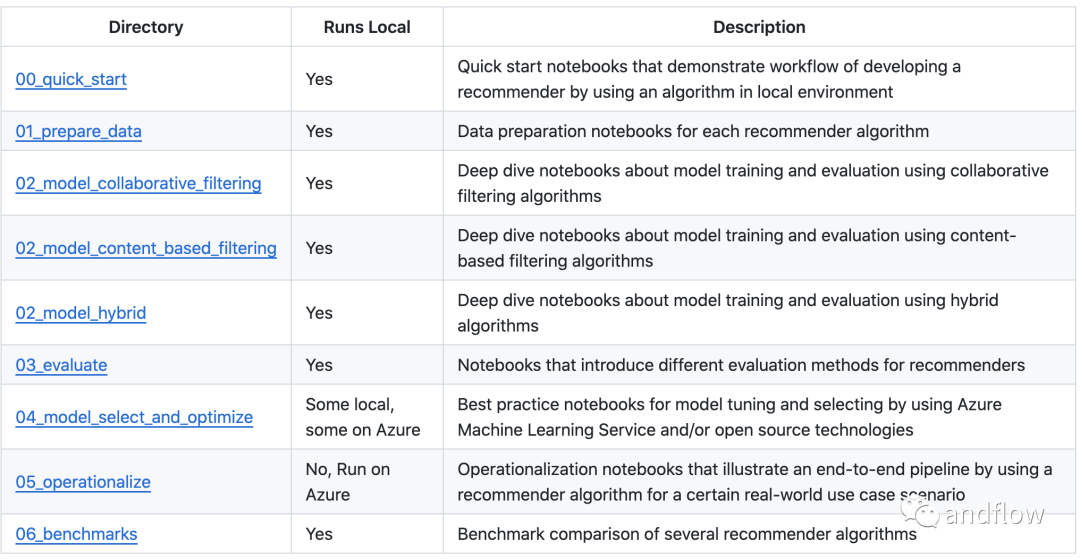
下面是examples目录下的子目录内容介绍。
3.Gorse
GitHub(7.7K):https://github.com/gorse-io/gorse
语言:Go
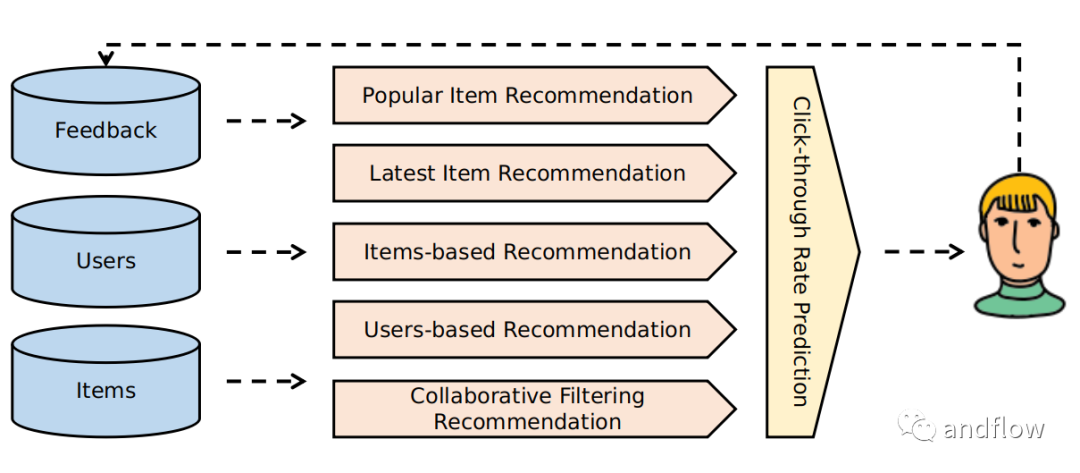
Gorse是一个用Go语言编写的开源推荐系统。Gorse的目标是成为一个通用的开源推荐系统,可以快速引入各种在线服务。通过将项目、用户和交互数据导入到Gorse中,系统将自动训练模型,为每个用户生成推荐。
特点包括:
- 多源推荐:热门、最新、基于用户、基于项目和协同过滤的推荐。
- AutoML:可在后台自动搜索最佳推荐模型。
- 分布式预测:支持单节点训练,而在推理阶段支持横向伸缩。
- RESTful API:为数据CRUD和推荐请求提供RESTful API。
- 在线评估:从最近新增的反馈中分析在线推荐性能。
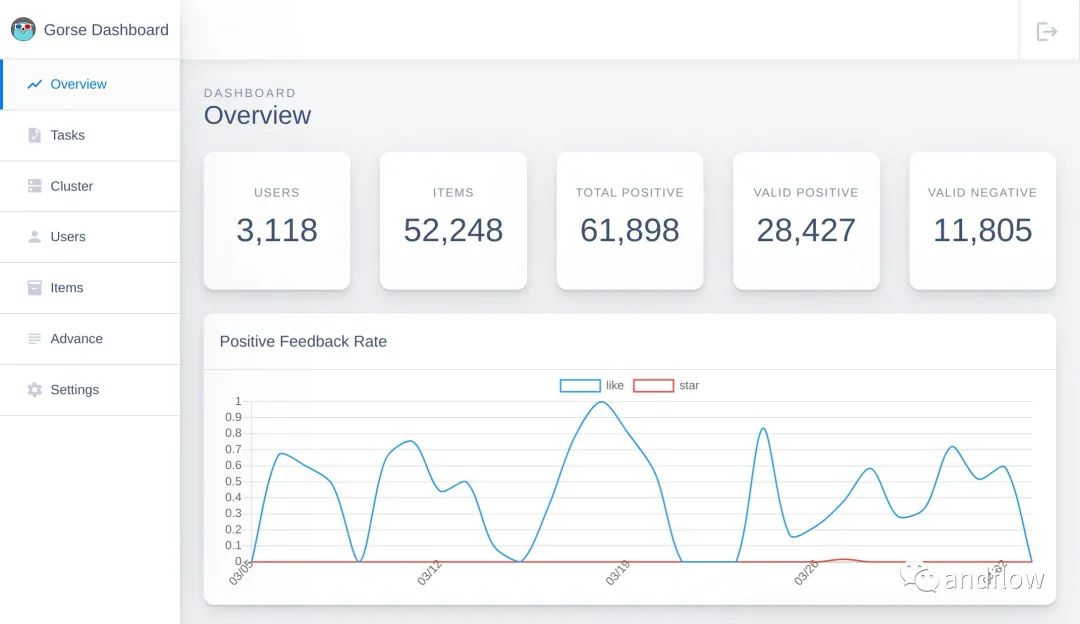
- 仪表板盘:提供GUI用于数据管理、系统监控和集群状态检查。
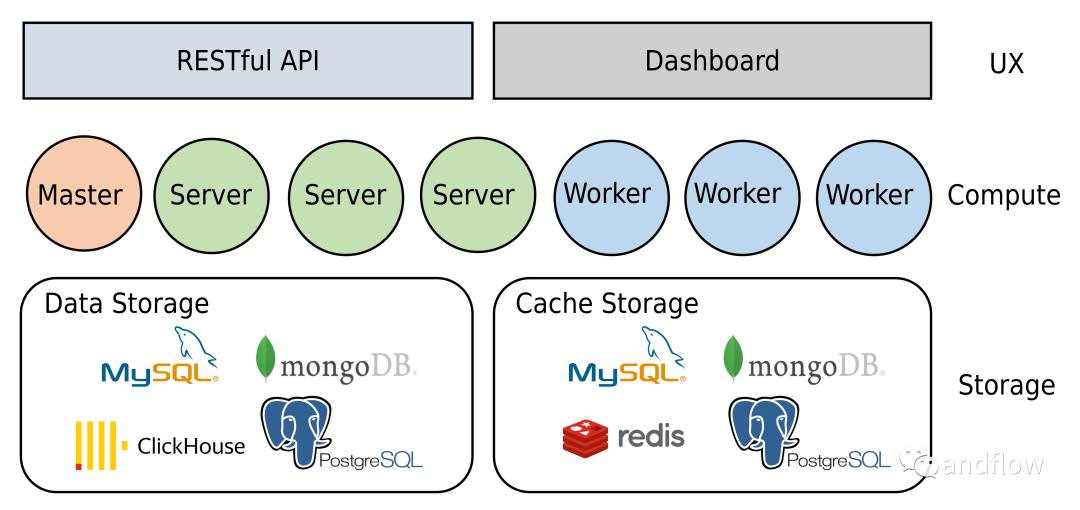
Gorse系统将数据存储在MySQL、MongoDB或Postgres中,中间结果缓存在Redis、MySQL、MongoDB或Postgres中。支持在一个单节点训练,并在分布式环境允许推荐系统。管理员可以通过主节点上的仪表盘监控系统运行状态、执行数据导入导出等操作。
其分布式架构如下:
仪表盘界面如下:
4.LightFM
GitHub(4.5K):https://github.com/lyst/lightfm
语言:Python

LightFM是一个用Python实现的一种混合推荐算法。用于隐式和显式反馈的推荐算法项目,包括基于BPR和WARP损失算法的有效实现。它易于使用,快速(通过多线程模型估计),并能够产生高质量的结果。
它还可以将项目和用户元数据合并到传统的矩阵分解算法中。从而允许推荐推广到新项目(通过项目特征)和新用户(通过用户特征)。
5.implicit
GitHub(3.3K):https://github.com/benfred/implicit
语言:Python
这个项目提供了几种不同的流行推荐算法的快速Python实现,以及用于快速Python协作过滤的隐式数据集:
- 交替最小二乘法,如在论文中所述的协同过滤隐式反馈数据集和应用共轭梯度法隐式反馈协同过滤
- 贝叶斯个性化排名
- 逻辑矩阵分解
- 使用余弦、TFIDF或BM 25作为距离度量的项-项最近邻模型。
6.spotlight
GitHub(2.9K):https://github.com/maciejkula/spotlight
语言:Python

Spotlight是个使用PyTorch构建的深度推荐模型。旨在成为推荐系统快速实践工具和新型推荐模型的原型。
7.EasyRec
GitHub(1.3K):https://github.com/alibaba/EasyRec
语言:Python

EasyRec是一个阿里巴巴开源的大规模推荐算法框架。实现了用于常见推荐任务的最先进的深度学习模型:候选生成(匹配),评分(排名)和多任务学习。它通过简单的配置和超参数调整(HPO)提高了生成高性能模型的效率。
8.Tensorflow Recommenders
GitHub(1.7K):https://github.com/tensorflow/recommenders

TensorFlow Recommenders是一个使用TensorFlow构建的推荐系统模型的库。这个项目可用于构建推荐系统的完整工作流程,包括:数据准备、模型制定、培训、评估和部署等环节。它建立在Keras框架之上,具备温和学习曲线,同时也支持灵活地构建复杂的模型。
9.TorchRec
GitHub(2K):https://github.com/pytorch/torchrec
语言:Python
TorchRec是一个PyTorch域库,旨在提供大规模推荐系统(RecSys)所需的常见稀疏并行原语。它允许作者使用跨多个GPU来训练模型。
TorchRec提供的内容包括:
- 使用混合数据并行性、模型并行性,轻松创作支持大型高性能多设备/多节点模型的并行性原语。
- TorchRec Sharder可以使用不同的分片策略对嵌入表进行分片,包括数据并行、表式、行式、表式行式、列式、表式列式分片。
- TorchRec规划器可以自动为模型生成优化的分片计划。
- 流水线训练与数据加载设备传输(复制到GPU)、设备间通信(input_dist)和计算(向前、向后)重叠,以提高性能。
- 针对由FBGEMM提供支持的RecSys优化内核。
- 量化支持降低精度的训练和推理。
- RecSys的通用模块。
- 用于RecSys的经过生产验证的模型架构。
- RecSys数据集(点击日志和movielens)
- 端到端训练的例子,比如在criteo click logs数据集上训练的dlrm事件预测模型。
10.RecSysDatasets
GitHub:https://github.com/RUCAIBox/RecSysDatasets
语言:Python

这是用于训练推荐系统(RS)的公共数据源。所有数据集都可以转换为原子文件, 它是一个统一、全面、高效的推荐系统资源。转换为原子文件后的数据集,可以使用RecBole在这些数据集上测试不同推荐模型的性能。
数据集包括:购物、电影、广告、音乐、图书、图片、游戏、网站、食品、新闻、衣服等等。
总之
以上这些开源推荐系统相关资源,可以让我们更好地学习推荐技术。基于现有的这些技术,互联网平台可以让用户更能够快速接纳自己提供的信息或者产品,给自己带来营收,为用户提供“千人千面”的服务。但同时也产生了“大数据杀熟”或者“信息茧房”的副作用。未来的推荐系统,也许还应该更加人性化一些吧。




























