













译者 | 布加迪
审校 | 重楼
从文档和数据中提取洞察力对于您做出明智的决策至关重要。然而在处理敏感信息时,会出现隐私问题。结合使用LangChain与OpenAI API,您就可以分析本地文档,无需上传到网上。
它们通过将数据保存在本地、使用嵌入和向量化进行分析以及在您的环境中执行进程来做到这一点。OpenAI不使用客户通过其API提交的数据来训练模型或改进服务。
搭建环境
创建一个新的Python虚拟环境,这将确保没有库版本冲突。然后运行以下终端命令来安装所需的库。
下面详细说明您将如何使用每个库:
- LangChain:您将用它来创建和管理用于文本处理和分析的语言链。它将提供用于文档加载、文本分割、嵌入和向量存储的模块。
- OpenAI:您将用它来运行查询,并从语言模型获取结果。
- tiktoken:您将用它来计算给定文本中token(文本单位)的数量。这是为了在与基于您使用的token数量收费的OpenAI API交互时跟踪token计数。
- FAISS:您将用它来创建和管理向量存储,允许基于嵌入快速检索相似的向量。
- PyPDF:这个库从PDF提取文本。它有助于加载PDF文件并提取其文本,供进一步处理。
安装完所有库之后,您的环境现已准备就绪。
获得OpenAI API密钥
当您向OpenAI API发出请求时,需要添加API密钥作为请求的一部分。该密钥允许API提供者验证请求是否来自合法来源,以及您是否拥有访问其功能所需的权限。
为了获得OpenAI API密钥,进入到OpenAI平台。
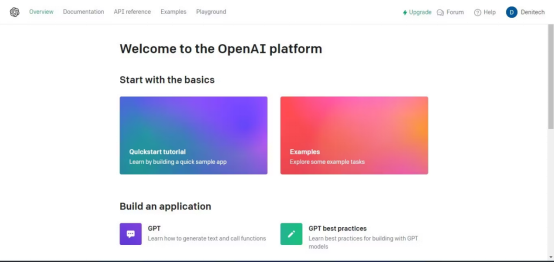
然后在右上方的帐户个人资料下,点击“查看API密钥”,将出现API密钥页面。
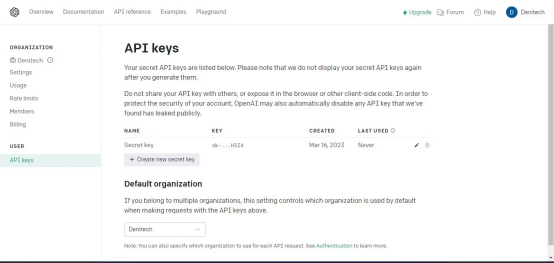
点击“创建新的密钥”按钮。为密钥命名,点击“创建新密钥”。OpenAI将生成API密钥,您应该复制并保存在安全的地方。出于安全原因,您将无法通过OpenAI帐户再次查看它。如果丢失了该密钥,需要生成新的密钥。
导入所需的库
为了能够使用安装在虚拟环境中的库,您需要导入它们。
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
加载用于分析的文档
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
查询文档
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
该函数使用创建的QA实例来运行查询并输出结果。
创建主函数
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__ == "__main__"构造函数来调用主函数:
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
执行文件分析
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
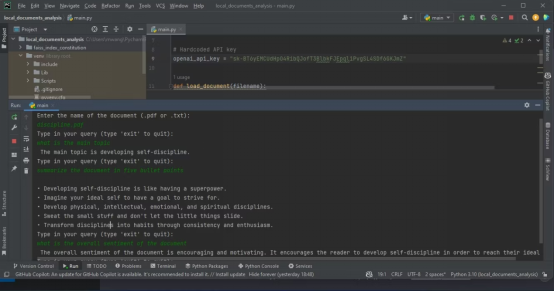
下面的截图显示了分析PDF的结果。
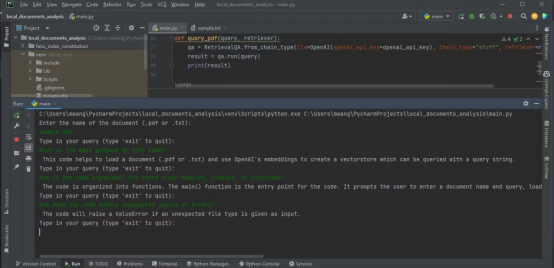
下面的输出显示了分析含有源代码的文本文件的结果。
确保所要分析的文件是PDF或文本格式。如果您的文档采用其他格式,可以使用在线工具将它们转换成PDF格式。
完整的源代码可以在GitHub代码库中获得:https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI。
原文标题:How to Analyze Documents With LangChain and the OpenAI API,作者:Denis Kuria


























