AI 画图的著名公司 Stability AI,终于入局 AI 生成视频了。
本周二,基于 Stable Diffusion 的视频生成模型 Stable Video Diffusion 来了,AI 社区马上开始了热议。
很多人都表示「我们终于等到了」。

项目地址:https://github.com/Stability-AI/generative-models
现在,你可以基于原有的静止图像来生成一段几秒钟的视频。
基于 Stability AI 原有的 Stable Diffusion 文生图模型,Stable Video Diffusion 成为了开源或已商业行列中为数不多的视频生成模型之一。


但目前还不是所有人都可以使用,Stable Video Diffusion 已经开放了用户候补名单注册(https://stability.ai/contact)。
据介绍,Stable Video Diffusion 可以轻松适应各种下游任务,包括通过对多视图数据集进行微调从单个图像进行多视图合成。Stability AI 表示,正在计划建立和扩展这个基础的各种模型,类似于围绕 stable diffusion 建立的生态系统。


Stable Video Diffusion 以两种图像到视频模型的形式发布,能够以每秒 3 到 30 帧之间的可定制帧速率生成 14 和 25 帧的视频。
在外部评估中,Stability AI 证实这些模型超越了用户偏好研究中领先的闭源模型:

Stability AI 强调,Stable Video Diffusion 现阶段不适用于现实世界或直接的商业应用,后续将根据用户对安全和质量的见解和反馈完善该模型。

论文地址:https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
Stable Video Diffusion 是 Stability AI 各式各样的开源模型大家族中的一员。现在看来,他们的产品已经横跨图像、语言、音频、三维和代码等多种模态,这是他们致力于提升 AI 最好的证明。
Stable Video Diffusion 的技术层面
Stable Video Diffusion 作为一种高分辨率的视频潜在扩散模型,达到了文本到视频或图像到视频的 SOTA 水平。近期,通过插入时间层并在小型高质量视频数据集上进行微调,为 2D 图像合成训练的潜在扩散模型已转变为生成视频模型。然而,文献中的训练方法千差万别,该领域尚未就视频数据整理的统一策略达成一致。
在 Stable Video Diffusion 的论文中,Stability AI 确定并评估了成功训练视频潜在扩散模型的三个不同阶段:文本到图像预训练、视频预训练和高质量视频微调。他们还证明了精心准备的预训练数据集对于生成高质量视频的重要性,并介绍了训练出一个强大基础模型的系统化策划流程,其中包括了字幕和过滤策略。
Stability AI 在论文中还探讨了在高质量数据上对基础模型进行微调的影响,并训练出一个可与闭源视频生成相媲美的文本到视频模型。该模型为下游任务提供了强大的运动表征,例如图像到视频的生成以及对摄像机运动特定的 LoRA 模块的适应性。除此之外,该模型还能够提供强大的多视图 3D 先验,这可以作为多视图扩散模型的基础,模型以前馈方式生成对象的多个视图,只需要较小的算力需求,性能还优于基于图像的方法。

具体而言,成功训练该模型包括以下三个阶段:
阶段一:图像预训练。本文将图像预训练视为训练 pipeline 的第一阶段,并将初始模型建立在 Stable Diffusion 2.1 的基础上,这样一来为视频模型配备了强大的视觉表示。为了分析图像预训练的效果,本文还训练并比较了两个相同的视频模型。图 3a 结果表明,图像预训练模型在质量和提示跟踪方面都更受青睐。
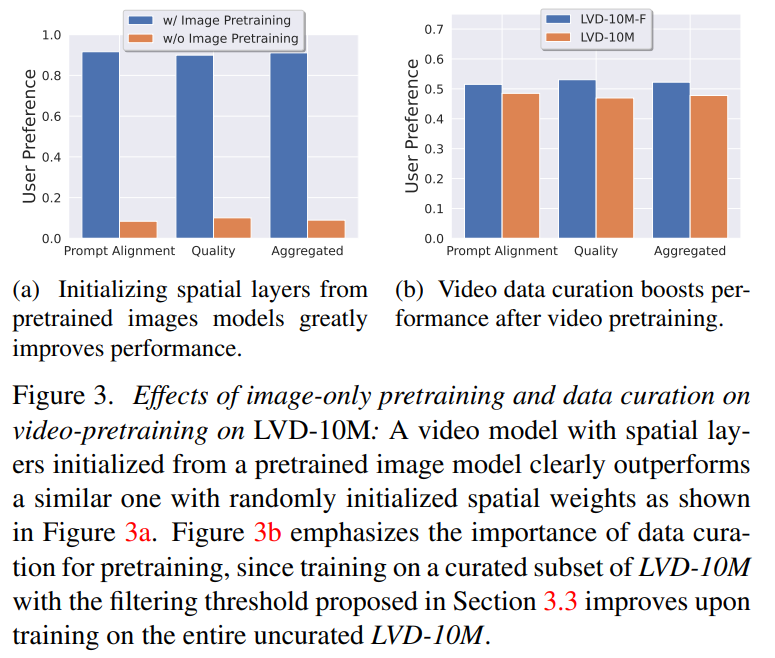
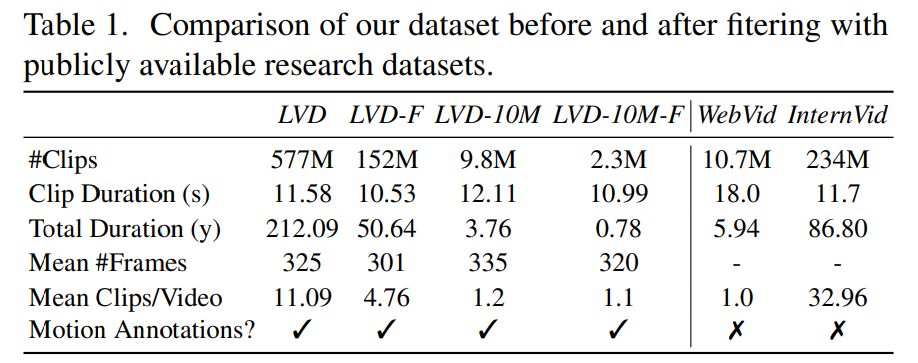
阶段 2:视频预训练数据集。本文依靠人类偏好作为信号来创建合适的预训练数据集。本文创建的数据集为 LVD(Large Video Dataset ),由 580M 对带注释的视频片段组成。
进一步的研究表明生成的数据集包含可能会降低最终视频模型性能的示例。因此,本文还采用了密集光流来注释数据集。
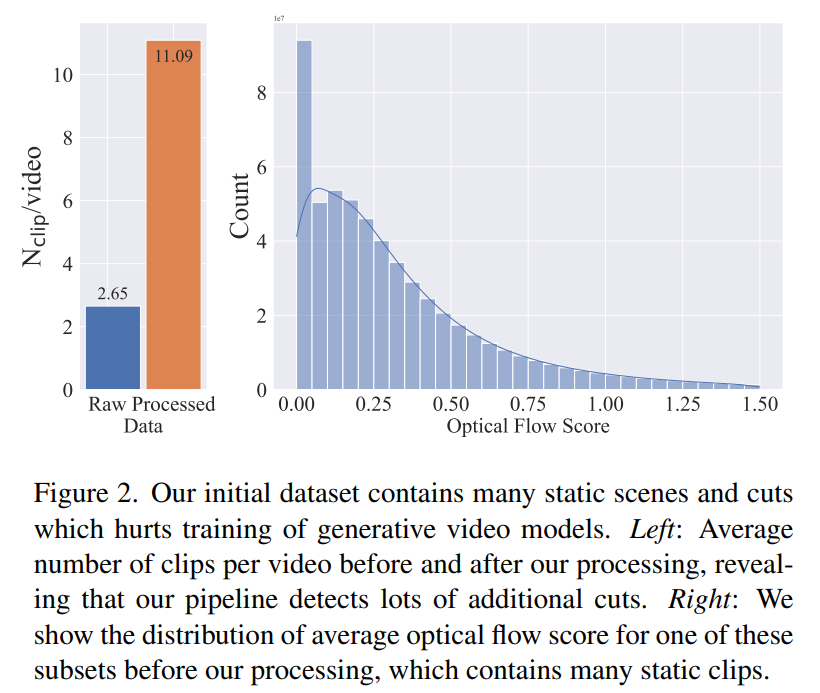
此外,本文还应用光学字符识别来清除包含大量文本的剪辑。最后,本文使用 CLIP 嵌入来注释每个剪辑的第一帧、中间帧和最后一帧。下表提供了 LVD 数据集的一些统计信息:
阶段 3:高质量微调。为了分析视频预训练对最后阶段的影响,本文对三个模型进行了微调,这些模型仅在初始化方面有所不同。图 4e 为结果。

看起来这是个好的开始。什么时候,我们能用 AI 直接生成一部电影呢?