译者 | 朱先忠
审校 | 重楼
简介

GPT等语言模型最近变得非常流行,并被应用于各种文本生成任务,例如在ChatGPT或其他会话人工智能系统中。通常,这些语言模型规模巨大,经常使用超过数百亿个参数,并且需要大量的计算资源和资金来运行。
在英语模型的背景下,这些庞大的模型被过度参数化了,因为它们使用模型的参数来记忆和学习我们这个世界的各个方面,而不仅仅是为英语建模。如果我们要开发一个应用程序,要求模型只理解语言及其结构,那么我们可能会使用一个小得多的模型。
注意:您可以在本文提供的Jupyter笔记本https://github.com/dhruvbird/ml-notebooks/blob/main/next_word_probability/inference-next-word-probability.ipynb上找到在训练好的模型上运行推理的完整源代码。
问题描述
假设我们正在构建一个滑动键盘系统,该系统试图预测你下一次在手机上键入的单词。基于滑动模式跟踪的模式,用户想要的单词存在很多可能性。然而,这些可能的单词中有许多并不是英语中的实际单词,可以被删除。即使在这个最初的修剪和消除步骤之后,仍有许多候选者,我们需要为用户选择其中之一作为建议。
为了进一步修剪这个候选词列表,我们可以使用基于深度学习的语言模型,该模型能够查看所提供的上下文,并告诉我们哪一个候选者最有可能完成句子。
例如,如果用户键入句子“I’ve scheduled this(我已经安排好了)”,然后按如下图所示滑动一个模式:
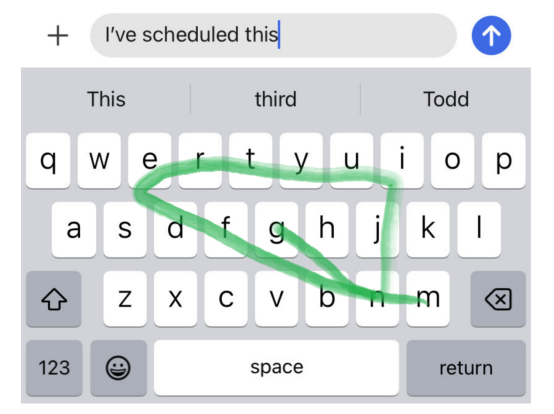
然后,用户可能想要的一些英语单词是:
- messing(搅乱)
- meeting(会议)
然而,如果我们仔细想想,很可能用户的意思是“开会”,而不是“捣乱”,因为句子前半部分有“scheduled(预定)”一词。
考虑到目前为止我们所知道的一切,我们可以选择什么方案以便通过编程进行调整呢?让我们在下面的部分发挥头脑风暴,想出一些解决方案。
头脑风暴解决方案
算法和数据结构
使用第一性原理(first principles),从数据语料库开始,找到组合在一起的成对单词,并训练一个马尔可夫模型(https://en.wikipedia.org/wiki/Markov_model)来预测句子中出现成对单词的概率,这似乎是合理的。但是,您会注意到这种方法存在两个重要问题。
- 空间利用率:英语中有25万到100万个单词,其中不包括数量不断增长的大量专有名词。因此,任何建模一对单词出现在一起的概率的传统软件解决方案都必须维护一个具有250k*250k=625亿个单词对的查询表,这显然有点过分。其实,许多单词配对似乎不经常出现,可以进行修剪。即使在修剪之后,仍然存在很多对单词需要考虑。
- 完整性:对一对单词的概率进行编码并不能公正地解决手头的问题。例如,当你只看最近的一对单词时,前面的句子上下文就完全丢失了。在“你的一天过得怎么样(How is your day coming)”这句话中,如果你想检查“来了(coming)”之后的单词,你会有很多以“来了“开头的配对。这会漏掉该单词之前的整个句子上下文。人们可以想象使用单词三元组等……但这加剧了上述空间利用问题。
接下来,让我们把重点转移到利用英语本质的解决方案上,看看这是否能对我们有所帮助。
自然语言处理
从历史上看,NLP(自然语言处理)领域涉及理解句子的词性,并使用这些信息来执行这种修剪和预测决策。可以想象这样的情形:使用与每个单词相关联的一个POS标签来确定句子中的下一个单词是否有效。
然而,计算一个句子的词性的过程本身就是一个复杂的过程,需要对语言有专门的理解,正如NLTK的词性标记页面所证明的那样。
接下来,让我们来看一种基于深度学习的方法,它需要更多的标记数据,但不需要那么多的语言专业知识来构建。
深度学习(神经网络)
深度学习的出现颠覆了NLP领域。随着基于LSTM和Transformer的语言模型的发明,解决方案通常包括向模型抛出一些高质量的数据,并对其进行训练以预测下一个单词。
从本质上讲,这就是GPT模型正在做的事情。GPT模型总是被不断训练来预测给定句子前缀的下一个单词(标记)。
例如,给定句子前缀“It is so would a would”,模型很可能会为句子后面的单词提供以下高概率预测。
- day(白天)
- experience(经验)
- world(世界)
- life(生活)
以下单词完成句子前缀的概率也可能较低。
- red(红色)
- mouse(老鼠)
- line(线)
Transformer模型体系结构(machine_learning_model)是ChatGPT等系统的核心。然而,对于学习英语语义的更受限制的应用场景,我们可以使用更便宜的运行模型架构,例如LSTM(长短期记忆)模型。
LSTM模型
接下来,让我们构建一个简单的LSTM模型,并训练它来预测给定标记(token)前缀的下一个标记。现在,你可能会问什么是标记。
符号化
通常,对于语言模型,标记可以表示:
- 单个字符(或单个字节)
- 目标语言中的整个单词
- 介于1和2之间的词汇,这通常被称为子词
将单个字符(或字节)映射到标记是非常有限制的,因为我们要重载该标记,以保存关于它发生位置的大量上下文。这是因为,例如,“c”这个字符出现在许多不同的单词中,在我们看到“c”之后预测下一个字符需要我们认真观察引导上下文。
将一个单词映射到一个标记也是有问题的,因为英语本身有25万到100万个单词。此外,当一个新词被添加到语言中时会发生什么呢?我们需要回去重新训练整个模型来解释这个新词吗?
子词标记化(Sub-word tokenization)被认为是2023年的行业标准。它将频繁出现在一起的字节的子字符串分配给唯一的标记。通常,语言模型有几千(比如4000)到数万(比如60000)个独特的标记。确定什么构成标记的算法由BPE(字节对编码:Byte pair encoding)算法确定。
要选择词汇表中唯一标记的数量(称为词汇表大小),我们需要注意以下几点:
- 如果我们选择的标记太少,我们就会回到每个角色一个标记的模式,模型很难学到任何有用的内容。
- 如果我们选择了太多的标记,我们最终会出现这样的情况:模型的嵌入表覆盖了模型的其余权重,并且很难在受约束的环境中部署模型。嵌入表的大小将取决于我们为每个标记使用的维度的数量。使用256、512、786等大小并不罕见。如果我们使用512的标记嵌入维度,并且我们有100k个标记,那么我们最终会得到一个在内存中使用200MiB的嵌入表。
因此,我们需要在选择词汇量时进行平衡。在本例中,我们选取6600个标记,并用6600的词汇大小训练我们的标记生成器。接下来,让我们来看看模型定义本身。
PyTorch模型
模型本身非常简单。我们创建了以下几个层:
- 标记嵌入(词汇大小=6600,嵌入维数=512),总大小约为15MiB(假设嵌入表的数据类型为4字节的float32类型)
- LSTM(层数=1,隐藏尺寸=786),总尺寸约为16MiB
- 多层感知器(786至3144至6600维度),总尺寸约93MiB
整个模型具有约31M个可训练参数,总大小约为120MiB。
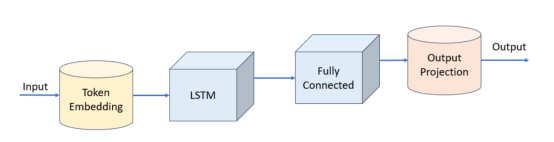
下面给出的是模型的PyTorch代码。
class WordPredictionLSTMModel(nn.Module):
def __init__(self, num_embed, embed_dim, pad_idx, lstm_hidden_dim, lstm_num_layers, output_dim, dropout):
super().__init__()
self.vocab_size = num_embed
self.embed = nn.Embedding(num_embed, embed_dim, pad_idx)
self.lstm = nn.LSTM(embed_dim, lstm_hidden_dim, lstm_num_layers, batch_first=True, dropout=dropout)
self.fc = nn.Sequential(
nn.Linear(lstm_hidden_dim, lstm_hidden_dim * 4),
nn.LayerNorm(lstm_hidden_dim * 4),
nn.LeakyReLU(),
nn.Dropout(p=dropout),
nn.Linear(lstm_hidden_dim * 4, output_dim),
)
#
def forward(self, x):
x = self.embed(x)
x, _ = self.lstm(x)
x = self.fc(x)
x = x.permute(0, 2, 1)
return x
#
#以下是使用torchinfo库输出的模型摘要信息。
LSTM模型摘要
=================================================================
Layer (type:depth-idx) Param #
=================================================================
WordPredictionLSTMModel -
├─Embedding: 1–1 3,379,200
├─LSTM: 1–2 4,087,200
├─Sequential: 1–3 -
│ └─Linear: 2–1 2,474,328
│ └─LayerNorm: 2–2 6,288
│ └─LeakyReLU: 2–3 -
│ └─Dropout: 2–4 -
│ └─Linear: 2–5 20,757,000
=================================================================
Total params: 30,704,016
Trainable params: 30,704,016
Non-trainable params: 0
=================================================================解释准确性:在P100 GPU上对该模型进行了约8小时的12M英语句子训练后,我们获得了4.03的损失值、29%的前1名准确率和49%的前5名准确率。这意味着,29%的时间中该模型能够正确预测下一个标记,而49%的时间中训练集中的下一个标记是该模型的前5个预测之一。
那么,我们的成功指标应该是什么?虽然我们模型的前1名和前5名精度数字并不令人印象深刻,但它们对我们的问题并不那么重要。我们的候选单词是一小组符合滑动模式的可能单词。我们希望我们的模型能够选择一个理想的候选者来完成句子,使其在语法和语义上连贯一致。由于我们的模型通过训练数据学习语言的性质,我们希望它能为连贯句子分配更高的概率。例如,如果我们有一个句子“The baseball player(棒球运动员)”和可能的补全词(“ran”、“swim”、“hid”),那么“ran”这个词比其他两个词更适合后续使用。因此,如果我们的模型预测单词ran的概率比其他单词高,那么它对我们来说是有效的。
解释损失值:损失值4.03意味着,预测的负对数可能性为4.03;这意味着,正确预测下一个标记的概率为e^-4.03=0.0178或1/56。随机初始化的模型通常具有大约8.8的损失值,即-log_e(1/6600),因为该模型随机预测1/6600个标记(6600是词汇表大小)。虽然4.03的损失值似乎不大,但重要的是要记住,经过训练的模型比未经训练(或随机初始化)的模型好大约120倍。
接下来,让我们看看如何使用此模型来改进滑动键盘的建议。
使用模型修剪无效建议
让我们来看一个真实的例子。假设我们有一个部分完成的句子“I think”,用户做出下面蓝色所示的滑动模式,从“o”开始,在字母“c”和“v”之间,并在字母“e”和“v”之间结束。
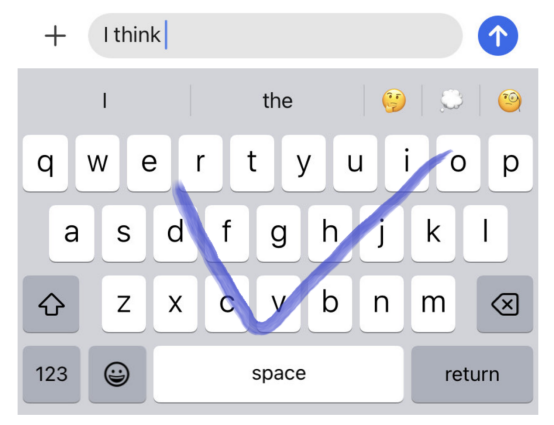
可以用这种滑动模式表示的一些可能的单词是:
- Over(结束)
- Oct(十月的缩写)
- Ice(冰)
- I’ve(我已经)
在这些建议中,最有可能的可能是“I’ve”。让我们将这些建议输入到我们的模型中,看看它会产生什么结果。
[I think] [I've] = 0.00087
[I think] [over] = 0.00051
[I think] [ice] = 0.00001
[I think] [Oct] = 0.00000=符号后的值是单词有效完成句子前缀的概率。在这种情况下,我们看到“我已经”这个词被赋予了最高的概率。因此,它是最有可能跟在句子前缀“I think”后面的词。
下一个问题是:我们如何计算下一个单词的概率。
计算下一个单词的概率
为了计算一个单词是句子前缀的有效完成的概率,我们在eval(推理)模式下运行模型,并输入标记化的句子前缀。在为单词添加空白前缀后,我们还将该单词标记化。这样做是因为HuggingFace预标记化器在单词开头用空格分隔单词,所以我们希望确保我们的输入与HuggingFace标记化器使用的标记化策略一致。
让我们假设候选单词由3个标记T0、T1和T2组成。
- 我们首先使用原始标记化的句子前缀来运行该模型。对于最后一个标记,我们检查预测标记T0的概率。我们将其添加到“probs”列表中。
- 接下来,我们对前缀+T0进行预测,并检查标记T1的概率。我们将此概率添加到“probs”列表中。
- 接下来,我们对前缀+T0+T1进行预测,并检查标记T2的概率。我们将此概率添加到“probs”列表中。
“probs”列表包含按顺序生成标记T0、T1和T2的各个概率。由于这些标记对应于候选词的标记化,我们可以将这些概率相乘,得到候选词完成句子前缀的组合概率。
用于计算完成概率的代码如下所示。
def get_completion_probability(self, input, completion, tok):
self.model.eval()
ids = tok.encode(input).ids
ids = torch.tensor(ids, device=self.device).unsqueeze(0)
completion_ids = torch.tensor(tok.encode(completion).ids, device=self.device).unsqueeze(0)
probs = []
for i in range(completion_ids.size(1)):
y = self.model(ids)
y = y[0,:,-1].softmax(dim=0)
#prob是完成的概率。
prob = y[completion_ids[0,i]]
probs.append(prob)
ids = torch.cat([ids, completion_ids[:,i:i+1]], dim=1)
#
return torch.tensor(probs)
#我们可以在下面看到更多的例子。
[That ice-cream looks] [really] = 0.00709
[That ice-cream looks] [delicious] = 0.00264
[That ice-cream looks] [absolutely] = 0.00122
[That ice-cream looks] [real] = 0.00031
[That ice-cream looks] [fish] = 0.00004
[That ice-cream looks] [paper] = 0.00001
[That ice-cream looks] [atrocious] = 0.00000
[Since we're heading] [toward] = 0.01052
[Since we're heading] [away] = 0.00344
[Since we're heading] [against] = 0.00035
[Since we're heading] [both] = 0.00009
[Since we're heading] [death] = 0.00000
[Since we're heading] [bubble] = 0.00000
[Since we're heading] [birth] = 0.00000
[Did I make] [a] = 0.22704
[Did I make] [the] = 0.06622
[Did I make] [good] = 0.00190
[Did I make] [food] = 0.00020
[Did I make] [color] = 0.00007
[Did I make] [house] = 0.00006
[Did I make] [colour] = 0.00002
[Did I make] [pencil] = 0.00001
[Did I make] [flower] = 0.00000
[We want a candidate] [with] = 0.03209
[We want a candidate] [that] = 0.02145
[We want a candidate] [experience] = 0.00097
[We want a candidate] [which] = 0.00094
[We want a candidate] [more] = 0.00010
[We want a candidate] [less] = 0.00007
[We want a candidate] [school] = 0.00003
[This is the definitive guide to the] [the] = 0.00089
[This is the definitive guide to the] [complete] = 0.00047
[This is the definitive guide to the] [sentence] = 0.00006
[This is the definitive guide to the] [rapper] = 0.00001
[This is the definitive guide to the] [illustrated] = 0.00001
[This is the definitive guide to the] [extravagant] = 0.00000
[This is the definitive guide to the] [wrapper] = 0.00000
[This is the definitive guide to the] [miniscule] = 0.00000
[Please can you] [check] = 0.00502
[Please can you] [confirm] = 0.00488
[Please can you] [cease] = 0.00002
[Please can you] [cradle] = 0.00000
[Please can you] [laptop] = 0.00000
[Please can you] [envelope] = 0.00000
[Please can you] [options] = 0.00000
[Please can you] [cordon] = 0.00000
[Please can you] [corolla] = 0.00000
[I think] [I've] = 0.00087
[I think] [over] = 0.00051
[I think] [ice] = 0.00001
[I think] [Oct] = 0.00000
[Please] [can] = 0.00428
[Please] [cab] = 0.00000
[I've scheduled this] [meeting] = 0.00077
[I've scheduled this] [messing] = 0.00000这些例子显示了单词在它之前完成句子的概率。候选词按概率递减的顺序排列。
由于Transformer正在慢慢取代基于序列的任务的LSTM和RNN模型,让我们来看看针对相同目标的Transformer模型会是什么样子。
一种Transformer(转换器)模型
基于转换器的模型是一种非常流行的架构,用于训练语言模型来预测句子中的下一个单词。我们将使用的具体技术是因果注意(causal attention)机制。我们将使用因果注意来训练PyTorch中的转换器编码器层。因果注意意味着:我们将允许序列中的每个标记只查看其之前的标记。这类似于单向LSTM层在仅向前训练时使用的信息。
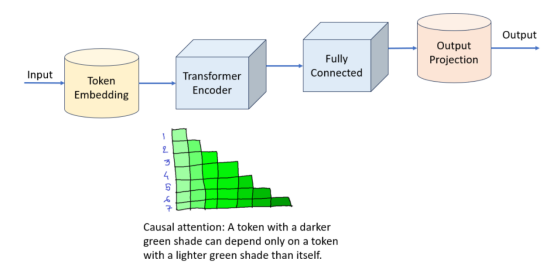
我们将在这里看到的Transformer模型直接基于nn.TransformerEncoder和PyTorch中的nn.TransformerEncoderLayer。
import math
def generate_src_mask(sz, device):
return torch.triu(torch.full((sz, sz), True, device=device), diagnotallow=1)
#
class PositionalEmbedding(nn.Module):
def __init__(self, sequence_length, embed_dim):
super().__init__()
self.sqrt_embed_dim = math.sqrt(embed_dim)
self.pos_embed = nn.Parameter(torch.empty((1, sequence_length, embed_dim)))
nn.init.uniform_(self.pos_embed, -1.0, 1.0)
#
def forward(self, x):
return x * self.sqrt_embed_dim + self.pos_embed[:,:x.size(1)]
#
#
class WordPredictionTransformerModel(nn.Module):
def __init__(self, sequence_length, num_embed, embed_dim, pad_idx, num_heads, num_layers, output_dim, dropout, norm_first, activation):
super().__init__()
self.vocab_size = num_embed
self.sequence_length = sequence_length
self.embed_dim = embed_dim
self.sqrt_embed_dim = math.sqrt(embed_dim)
self.embed = nn.Sequential(
nn.Embedding(num_embed, embed_dim, pad_idx),
PositionalEmbedding(sequence_length, embed_dim),
nn.LayerNorm(embed_dim),
nn.Dropout(p=0.1),
)
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim, nhead=num_heads, dropout=dropout, batch_first=True, norm_first=norm_first, activatinotallow=activation,
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.LayerNorm(embed_dim * 4),
nn.LeakyReLU(),
nn.Dropout(p=dropout),
nn.Linear(embed_dim * 4, output_dim),
)
#
def forward(self, x):
src_attention_mask = generate_src_mask(x.size(1), x.device)
x = self.embed(x)
x = self.encoder(x, is_causal=True, mask=src_attention_mask)
x = self.fc(x)
x = x.permute(0, 2, 1)
return x
#
#我们可以用这个模型代替我们之前使用的LSTM模型,因为它是API兼容的。对于相同数量的训练数据,该模型需要更长的时间来训练,并且具有可比较的性能。
Transformer模型更适合长序列。在我们的例子中,我们有长度为256的序列。执行下一个单词补全所需的大多数上下文往往是本地的,所以我们在这里并不真正需要借助转换器的力量。
结论
在本文中,我们学习了如何使用基于LSTM(RNN)和Transformer模型的深度学习技术来解决非常实际的NLP问题。并不是每个语言任务都需要使用具有数十亿参数的模型。需要建模语言本身而不需要记忆大量信息的专业应用程序可以使用更小的模型来处理,这些模型可以比我们现在看到的大规模语言模型更容易、更高效地部署。
注:本文中所有图片均由作者本人创作。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Language Models for Sentence Completion,作者:Dhruv Matani